本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
获取有关数据和数据质量的见解
使用数据质量和见解报告对您导入到 Data Wrangler 中的数据进行分析。建议您在导入数据集之后创建报告。可以使用该报告来协助您清理和处理自己的数据。该报告为您提供诸如缺失值数量和异常值数量之类的信息。如果您的数据存在问题,例如目标泄漏或不平衡,则见解报告可以让您注意到这些问题。
按照以下过程创建数据质量和见解报告。该过程假设您已将数据集导入到 Data Wrangler 流中。
创建数据质量和见解报告
-
选择 Data Wrangler 流中节点旁边的 +。
-
选择获取数据见解。
-
对于分析名称,为见解报告指定名称。
-
(可选)对于目标列,指定目标列。
-
对于问题类型,请指定回归或分类。
-
对于数据大小,指定下列项之一:
-
50 K – 使用您导入的数据集的前 50000 行来创建报告。
-
整个数据集 – 使用您导入的整个数据集来创建报告。
注意
针对整个数据集创建数据质量和见解报告需要使用 Amazon SageMaker 处理任务。 SageMaker 处理任务预置了获取所有数据见解所需的额外计算资源。有关 SageMaker 处理任务的更多信息,请参阅带 SageMaker 处理功能的数据转换工作负载。
-
-
选择创建。
下面的主题说明了报告的各个部分:
可以下载报告或在线查看。要下载报告,请选择屏幕右上角的下载按钮。下图显示了该按钮。

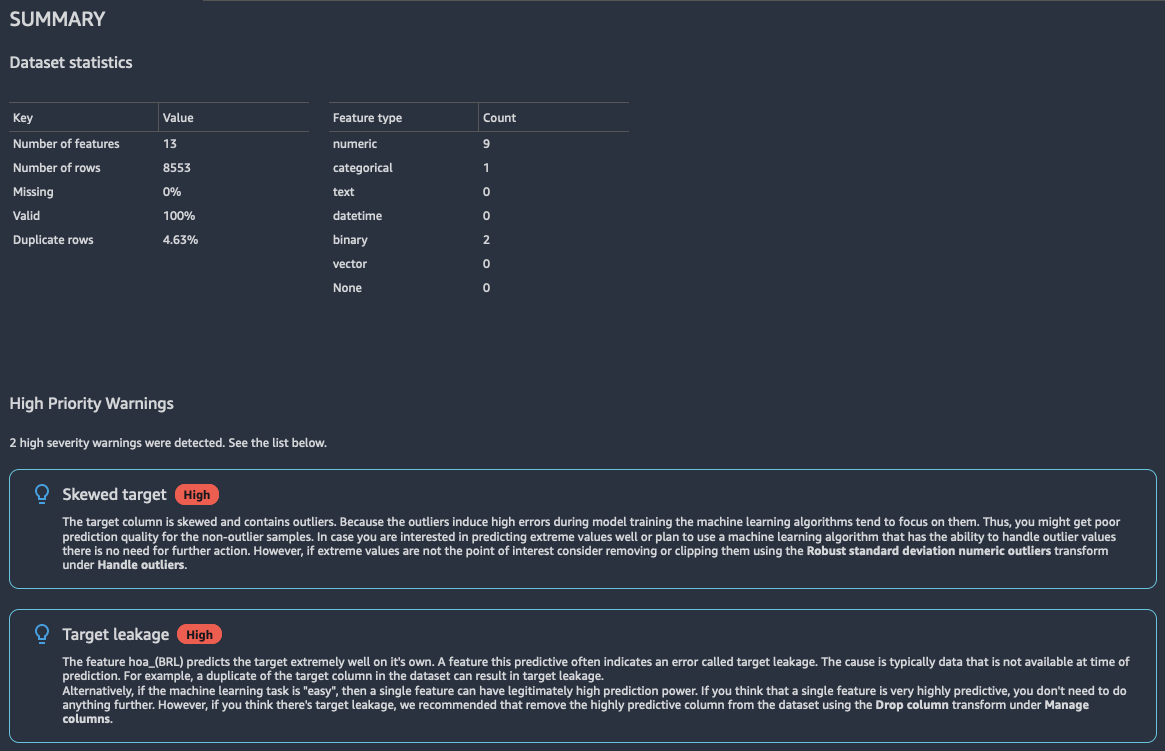
Summary
见解报告对数据进行了简单汇总,其中包括缺失值、无效值、特征类型、异常值计数等一般信息。还可能包括高严重性警告,这些警告指出数据可能存在问题。我们建议您对警告进行调查研究。
下面是一个报告摘要示例。
目标列
在创建数据质量和见解报告时,Data Wrangler 会为您提供选项来选择目标列。目标列是要预测的列。在选择目标列时,Data Wrangler 会自动创建目标列分析。它还按特征的预测能力顺序对特征进行排名。选择目标列时,必须指定是要解决回归问题还是分类问题。
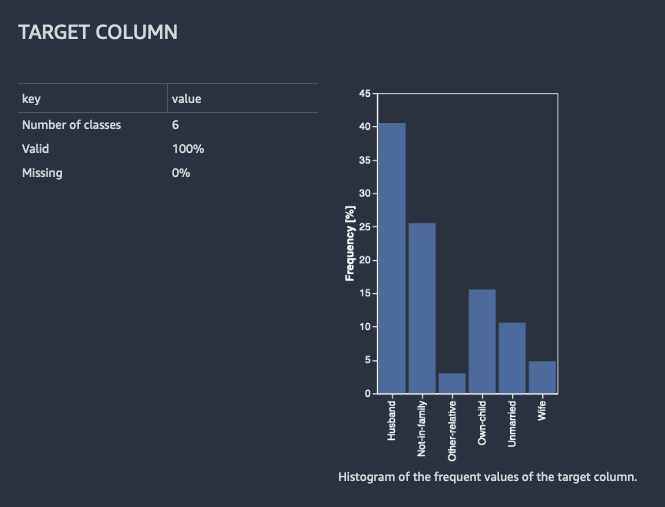
对于分类,Data Wrangler 会显示最常见分类的表和直方图。分类是指类别。它还会显示目标值缺失或无效的观测值或行。
下图显示了分类问题的目标列分析示例。
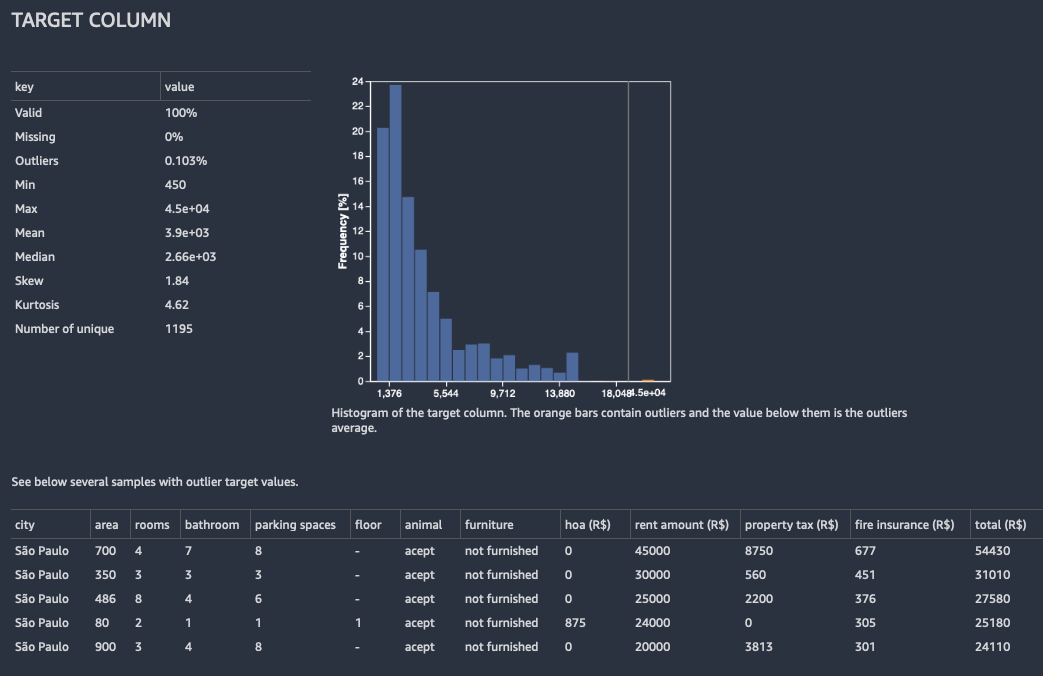
对于回归,Data Wrangler 会显示目标列中所有值的直方图。它还会显示带有缺失、无效或异常值目标值的观测值或行。
下图显示了回归问题的目标列分析示例。
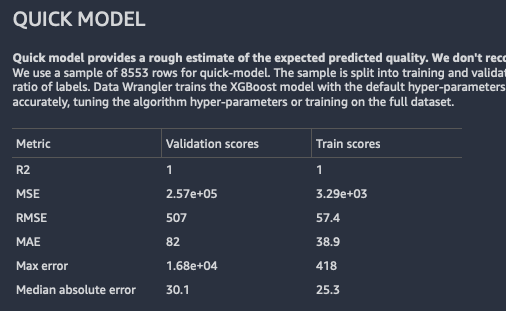
快速模型
快速模型提供您用于训练数据的模型的预期预测质量的估计值。
Data Wrangler 将您的数据拆分为训练层和验证层。它使用 80% 的样本进行训练,使用 20% 的值进行验证。对于分类,对样本进行分层分割。对于分层分割,每个数据分区的标签比例相同。对于分类问题,训练层和分类层之间的标签比例必须相同,这一点非常重要。Data Wrangler 使用默认的超参数训练XGBoost模型。它对验证数据进行提前停止,并执行最少的特征预处理。
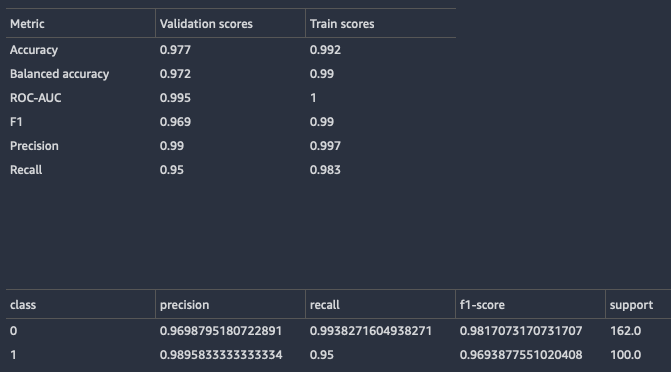
对于分类模型,Data Wrangler 会返回模型摘要和混淆矩阵。
以下是分类模型摘要示例。要详细了解所返回的信息,请参阅 定义。
以下是快速模型返回的混淆矩阵的示例。
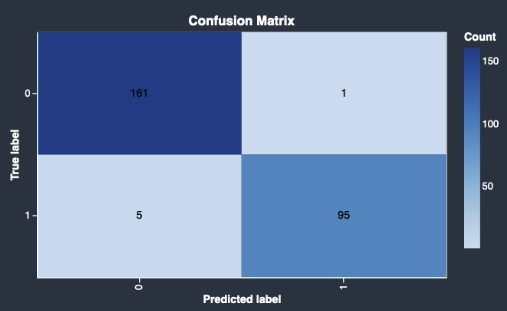
混淆矩阵提供了以下信息:
-
预测标签与真实标签匹配的次数。
-
预测标签与真实标签不匹配的次数。
真实标签表示数据中的实际观察值。例如,如果您使用模型来检测欺诈性交易,那么真实标签表示实际上是欺诈性交易或非欺诈性交易。预测标签表示模型为数据分配的标签。
可以使用混淆矩阵来查看模型对状况存在或不存在的预测程度。如果您预测的是欺诈性交易,可以使用混淆矩阵来了解模型的敏感性和特定性。敏感性是指模型检测欺诈性交易的能力。特定性是指该模型能够避免将非欺诈性交易检测为欺诈性交易。
以下是回归问题的快速模型输出的示例。
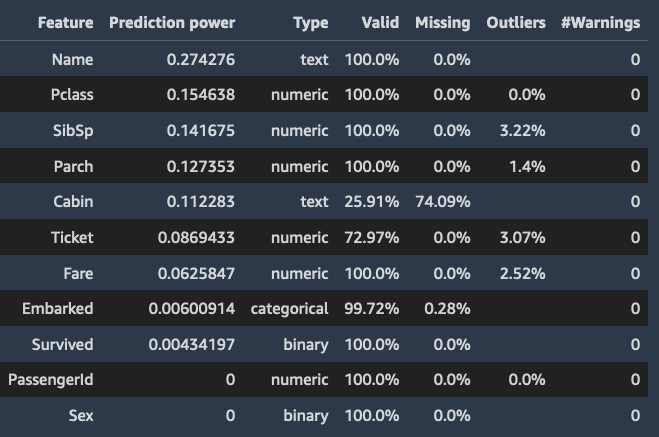
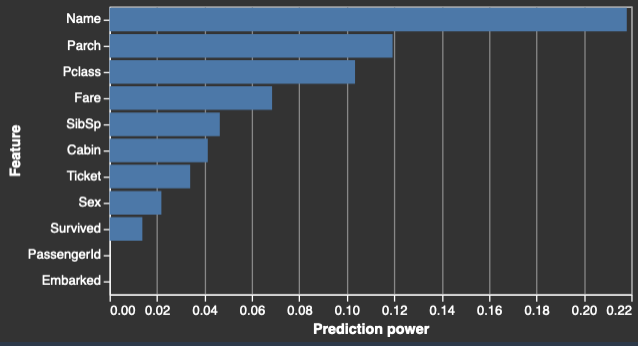
特征摘要
当您指定目标列时,Data Wrangler 会根据特征的预测能力对特征进行排序。预测能力是在将数据拆分为 80% 训练层和 20% 验证层之后,根据数据来衡量的。Data Wrangler 在训练层上分别拟合每个特征的模型。它应用最少的特征预处理并衡量验证数据的预测性能。
它将分数标准化为范围 [0,1]。预测分数越高,表示列自身对用于预测目标更有用。分数较低的列表示无法用于预测目标列的列。
某一列无法单独用于预测,但与其他列一起使用时具有预测性,这种情况并不常见。您可以放心地使用预测分数来确定数据集内的某个特征是否具有预测性。
分数低通常表示该特征是多余的。分数为 1 表示完美的预测能力,这通常表示目标泄漏。目标泄漏通常发生在数据集包含预测时不可用的列时。例如,它可能是目标列的重复项。
以下是显示每个特征预测值的表和直方图的示例。
样本
Data Wrangler 提供有关样本是否异常或数据集内是否存在重复项的信息。
Data Wrangler 使用孤立森林算法来检测异常样本。孤立森林算法将异常分数与数据集的每个样本(行)相关联。异常分数低表示样本异常。高分数与非异常样本关联。异常分数为负的样本通常被视为异常样本,异常分数为正的样本被视为非异常样本。
查看可能存在异常的样本时,我们建议您注意异常值。例如,可能会由于收集和处理数据时出错而存在的异常值。根据 Data Wrangler 对孤立森林算法的实施,以下是异常程度最高的样本示例。我们建议您在检查异常样本时运用专业领域知识和业务逻辑。
Data Wrangler 会检测重复行,并计算您的数据中重复行的比例。某些数据来源可能包含有效的重复项。其他数据来源可能具有表明数据收集存在问题的重复项。由于数据收集错误而产生的重复样本可能会干扰依赖于将数据拆分为独立训练层和验证层的机器学习流程。
以下是见解报告中可能受到重复样本影响的元素:
-
快速模型
-
预测能力估计
-
自动超参数优化
可以使用管理行下的删除重复项转换,从数据集内删除重复样本。Data Wrangler 会显示重复程度最高的行。
定义
以下是数据见解报告中使用的技术术语的定义。
