本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
Amazon SageMaker 调试器架构
本主题将引导您对 Amazon SageMaker Debugger 工作流程进行高级概述。
Debugger 支持用于性能优化的分析功能,以识别计算问题,例如系统瓶颈和利用率不足,并协助大规模优化硬件资源利用率。
Debugger 用于模型优化的调试功能用来分析可能出现的不收敛训练问题,在使用优化算法尽可能减少损失函数时可能会出现此类问题,例如梯度下降及其变化。
下图显示了 SageMaker 调试器的架构。带有粗边界线的方框是 Debugger 管理的内容,用来分析您的训练作业。
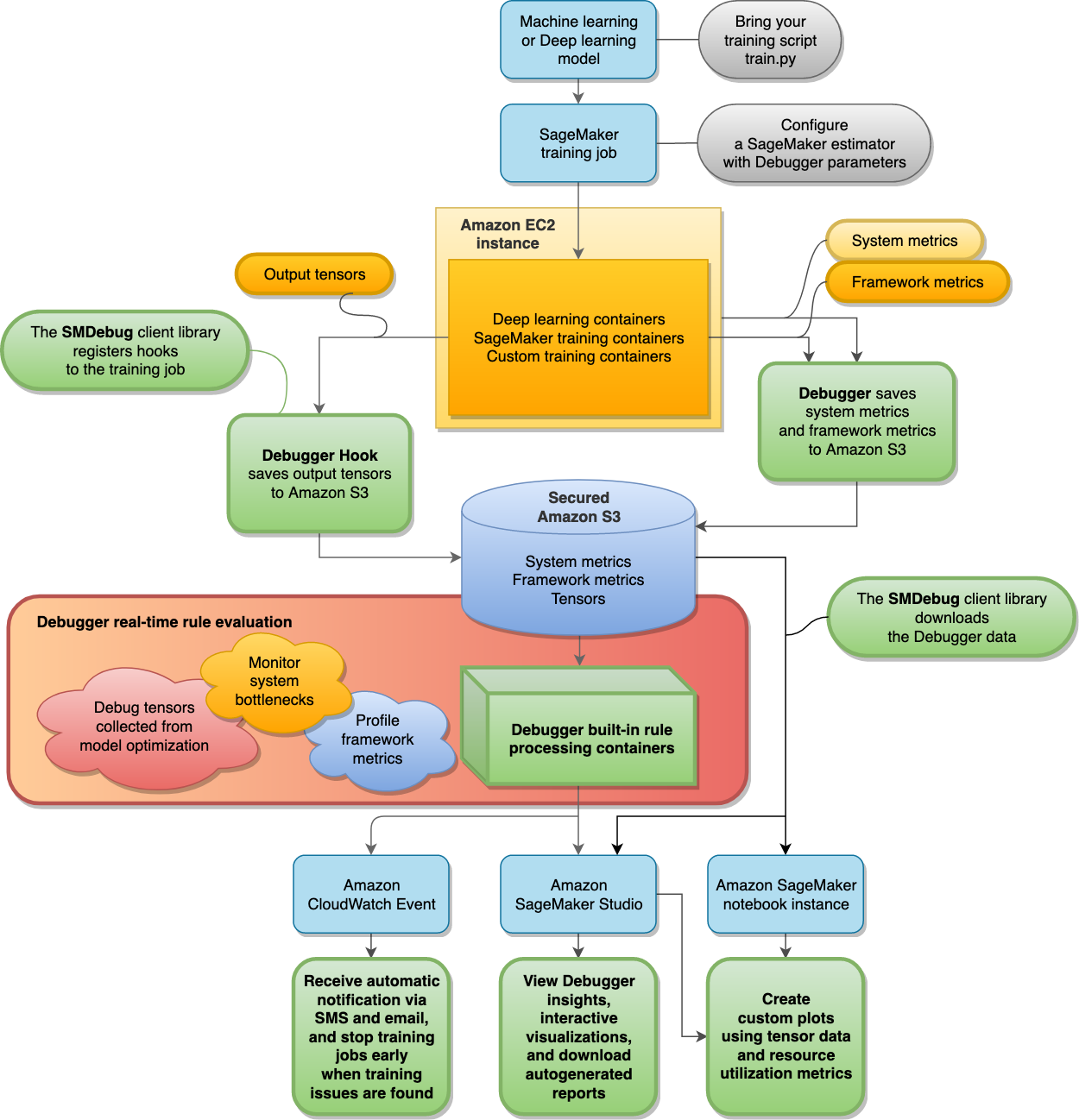
Debugger 将来自训练作业的以下数据存储在安全的 Amazon S3 存储桶中:
-
输出张量 – 在训练 ML 模型时,在向前和向后传递期间不断更新的标量和模型参数的集合。输出张量包括标量值(准确性和损失)和矩阵(权重、梯度、输入层和输出层)。
注意
默认情况下,Debugger 会监视和调试 SageMaker 训练作业,而无需在估算器中配置任何调试器特定的参数。 SageMaker Debugger 每 500 毫秒收集一次系统指标,每 500 个步骤收集一次基本输出张量(损耗和精度等标量输出)。它还运行
ProfilerReport规则来分析系统指标并聚合 Studio Debugger Insights 控制面板和分析报告。Debugger 将输出数据保存在安全的 Amazon S3 存储桶中。
Debugger 内置规则在处理容器上运行,设计为通过处理在 S3 存储桶中收集的训练数据来评估机器学习模型(请参阅处理数据和评估模型)。内置规则完全由 Debugger 管理。您也可以创建根据自己的模型自定义的规则,来监控您所关注的任何问题。
