本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
用于配置 Debugger 挂钩的示例笔记本和代码示例
以下部分提供了如何使用 Debugger 钩子保存、访问并可视化输出张量的笔记本和代码示例。
张量可视化示例笔记本
以下两个笔记本示例演示了 Amazon SageMaker Debugger 在可视化张量方面的高级用法。Debugger 提供了对训练深度学习模型的透明视图。
-
SageMaker Studio 笔记本中的交互式张量分析 MXNet
此笔记本示例展示了如何使用 Amazon Deb SageMaker ugger 可视化保存的张量。通过可视化张量,您可以在训练深度学习算法时查看张量值如何变化。本笔记本包括一项神经网络配置不佳的训练作业,并使用 Amazon D SageMaker ebugger 来聚合和分析张量,包括梯度、激活输出和权重。例如,下图显示了出现梯度消失问题的卷积层的梯度分布情况。
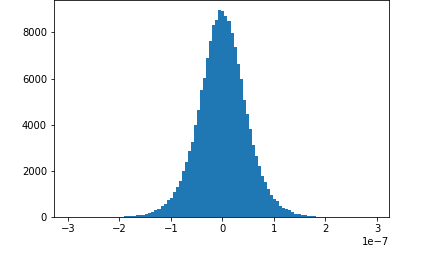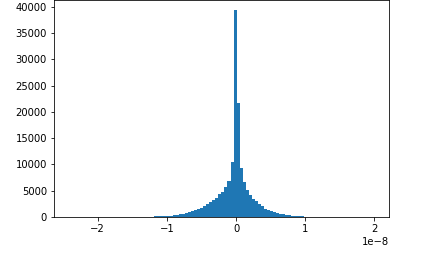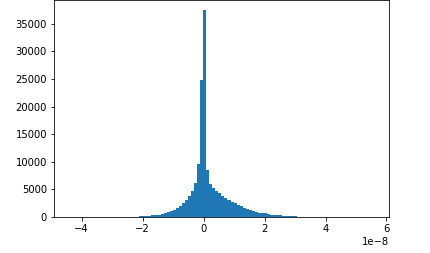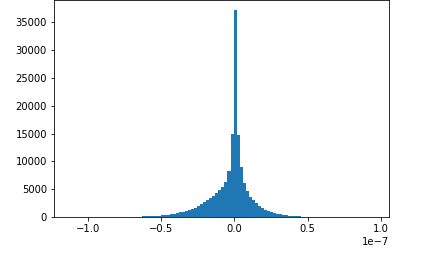
该笔记本还说明了正确的初始超参数设置如何生成相同的张量分布图,从而改进了训练过程。
-
此笔记本示例展示了如何使用 Amazon Debugger 保存和可视化 MXNet Gluon SageMaker 模型训练作业中的张量。它说明了 Debugger 设置为将所有张量保存到 Amazon S3 存储桶中,并检索可视化的 ReLu 激活输出。下图显示了 ReLu 激活输出的三维可视化。颜色方案设置为以蓝色表示接近于 0 的值,以黄色表示接近于 1 的值。

在此笔记本中,从中导入的
TensorPlot类tensor_plot.py旨在绘制以二维图像作为输入的卷积神经网络 (CNNs)。笔记本附带的tensor_plot.py脚本使用调试器检索张量并可视化。CNN你可以在 SageMaker Studio 上运行这个笔记本来重现张量可视化并实现自己的卷积神经网络模型。 -
在 SageMaker 笔记本中进行实时张量分析 MXNet
此示例将指导您安装在 Amazon SageMaker 训练作业中发射张量所需的组件,并在训练运行时使用调试器API操作访问这些张量。在 Fashion MNIST 数据集上训练胶子CNN模型。在作业运行期间,您将看到 Debugger 如何从 100 个批次的每个批次中检索第一个卷积层的激活输出并对其进行可视化。此外,它还会向您展示作业完成后如何对权重进行可视化。
使用调试器内置集合保存张量
您可以使用使用内置的张量集合 CollectionConfigAPI,也可以使用保存它们。DebuggerHookConfig API以下示例说明如何使用调试器挂钩配置的默认设置来构造 SageMaker TensorFlow 估计器。您也可以将其用于MXNet PyTorch、和XGBoost估算器。
注意
在以下示例代码中,DebuggerHookConfig 的 s3_output_path 参数可选。如果您未指定,Debugger 会将张量保存在中s3://<output_path>/debug-output/,其中<output_path>是 SageMaker 训练作业的默认输出路径。例如:
"s3://sagemaker-us-east-1-111122223333/sagemaker-debugger-training-YYYY-MM-DD-HH-MM-SS-123/debug-output"
import sagemaker from sagemaker.tensorflow import TensorFlow from sagemaker.debugger import DebuggerHookConfig, CollectionConfig # use Debugger CollectionConfig to call built-in collections collection_configs=[ CollectionConfig(name="weights"), CollectionConfig(name="gradients"), CollectionConfig(name="losses"), CollectionConfig(name="biases") ] # configure Debugger hook # set a target S3 bucket as you want sagemaker_session=sagemaker.Session() BUCKET_NAME=sagemaker_session.default_bucket() LOCATION_IN_BUCKET='debugger-built-in-collections-hook' hook_config=DebuggerHookConfig( s3_output_path='s3://{BUCKET_NAME}/{LOCATION_IN_BUCKET}'. format(BUCKET_NAME=BUCKET_NAME, LOCATION_IN_BUCKET=LOCATION_IN_BUCKET), collection_configs=collection_configs ) # construct a SageMaker TensorFlow estimator sagemaker_estimator=TensorFlow( entry_point='directory/to/your_training_script.py', role=sm.get_execution_role(), base_job_name='debugger-demo-job', instance_count=1, instance_type="ml.p3.2xlarge", framework_version="2.9.0", py_version="py39", # debugger-specific hook argument below debugger_hook_config=hook_config ) sagemaker_estimator.fit()
要查看 Debugger 内置集合的列表,请参阅 Debugger 内置集合
通过修改 Debugger 内置集合来保存张量
您可以使用CollectionConfigAPI操作修改 Debugger 内置集合。以下示例说明如何调整内置losses集合并构造 SageMaker TensorFlow 估算器。您也可以将其用于MXNet PyTorch、和XGBoost估计器。
import sagemaker from sagemaker.tensorflow import TensorFlow from sagemaker.debugger import DebuggerHookConfig, CollectionConfig # use Debugger CollectionConfig to call and modify built-in collections collection_configs=[ CollectionConfig( name="losses", parameters={"save_interval": "50"})] # configure Debugger hook # set a target S3 bucket as you want sagemaker_session=sagemaker.Session() BUCKET_NAME=sagemaker_session.default_bucket() LOCATION_IN_BUCKET='debugger-modified-collections-hook' hook_config=DebuggerHookConfig( s3_output_path='s3://{BUCKET_NAME}/{LOCATION_IN_BUCKET}'. format(BUCKET_NAME=BUCKET_NAME, LOCATION_IN_BUCKET=LOCATION_IN_BUCKET), collection_configs=collection_configs ) # construct a SageMaker TensorFlow estimator sagemaker_estimator=TensorFlow( entry_point='directory/to/your_training_script.py', role=sm.get_execution_role(), base_job_name='debugger-demo-job', instance_count=1, instance_type="ml.p3.2xlarge", framework_version="2.9.0", py_version="py39", # debugger-specific hook argument below debugger_hook_config=hook_config ) sagemaker_estimator.fit()
有关CollectionConfig参数的完整列表,请参阅调试器 CollectionConfig API
使用 Debugger 自定义集合保存张量
您也可以选择保存精简数量的张量而不是完整的张量集(例如,当您希望减少保存在 Amazon S3 存储桶中的数据量时)。以下示例说明了如何自定义 Debugger 钩子配置以指定要保存的目标张量。你可以将其用于 TensorFlow、MXNet PyTorch、和XGBoost估计器。
import sagemaker from sagemaker.tensorflow import TensorFlow from sagemaker.debugger import DebuggerHookConfig, CollectionConfig # use Debugger CollectionConfig to create a custom collection collection_configs=[ CollectionConfig( name="custom_activations_collection", parameters={ "include_regex": "relu|tanh", # Required "reductions": "mean,variance,max,abs_mean,abs_variance,abs_max" }) ] # configure Debugger hook # set a target S3 bucket as you want sagemaker_session=sagemaker.Session() BUCKET_NAME=sagemaker_session.default_bucket() LOCATION_IN_BUCKET='debugger-custom-collections-hook' hook_config=DebuggerHookConfig( s3_output_path='s3://{BUCKET_NAME}/{LOCATION_IN_BUCKET}'. format(BUCKET_NAME=BUCKET_NAME, LOCATION_IN_BUCKET=LOCATION_IN_BUCKET), collection_configs=collection_configs ) # construct a SageMaker TensorFlow estimator sagemaker_estimator=TensorFlow( entry_point='directory/to/your_training_script.py', role=sm.get_execution_role(), base_job_name='debugger-demo-job', instance_count=1, instance_type="ml.p3.2xlarge", framework_version="2.9.0", py_version="py39", # debugger-specific hook argument below debugger_hook_config=hook_config ) sagemaker_estimator.fit()
有关CollectionConfig参数的完整列表,请参阅调试器 CollectionConfig
