本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
了解在 Amazon 中部署模型和获取推论的选项 SageMaker
为了帮助您开始使用 SageMaker 推理,请参阅以下章节,其中说明了在中部署模型 SageMaker 和获取推理的选项。该Amazon 中的推理选项 SageMaker部分可以帮助您确定哪个功能最适合您的推理用例。
您可以参阅资源本节,了解更多疑难解答和参考信息、有助于您入门的博客和示例,以及常见问题FAQs。
主题
开始前的准备工作
以下主题假设您已构建和训练了一个或多个机器学习模型,并已准备好部署它们。您无需训练模型即可在 SageMaker 中部署模型 SageMaker 并获得推论。如果您没有自己的模型,也可以使用 SageMaker内置算法或预训练模型。
如果您是新手 SageMaker ,但尚未选择要部署的模型,请按照 Amazon 入门 SageMaker教程中的步骤进行操作。使用本教程来熟悉如何 SageMaker管理数据科学过程以及它如何处理模型部署。有关模型训练的更多信息,请参阅训练模型。
有关更多信息、参考和其他示例,请参阅资源。
模型部署步骤
对于推理端点,常规工作流包括以下内容:
通过指向 Amazon S3 中存储的模型工件和容器映像,在 SageMaker Inference 中创建模型。
选择推理选项。有关更多信息,请参阅 Amazon 中的推理选项 SageMaker。
通过 SageMaker 在终端节点后面选择所需的实例类型和实例数量来创建推理终端节点配置。您可以使用 Amazon SageMaker 推理推荐器来获取实例类型的建议。对于无服务器推理,您只需根据模型大小提供所需的内存配置。
创建 SageMaker 推理端点。
调用您的端点以收到推理作为响应。
下图显示了上述工作流。
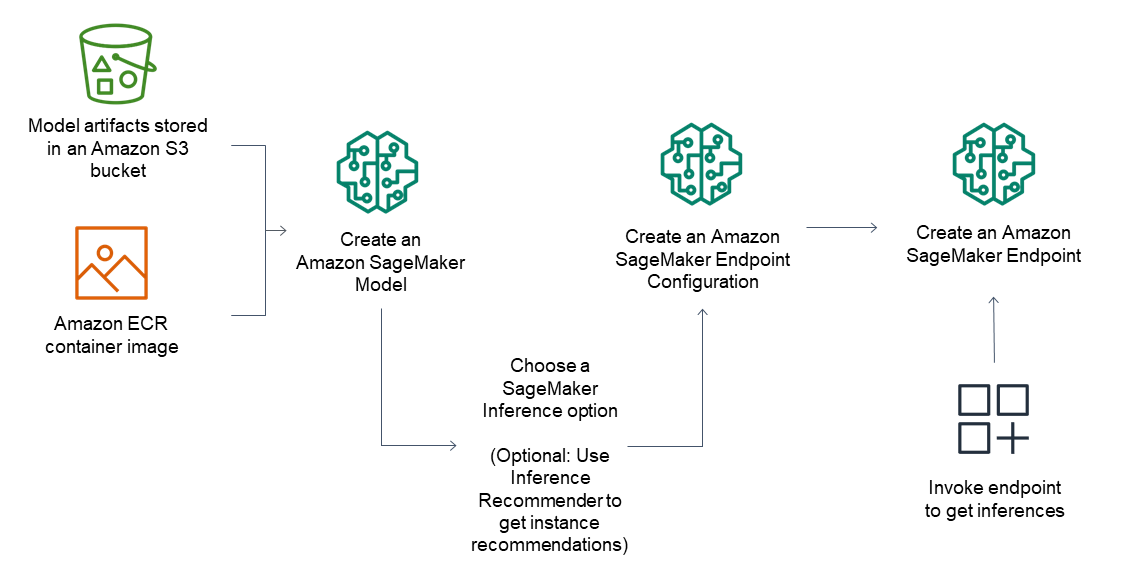
您可以使用控制 AWS 台、SDK、 SageMaker Python AWS CloudFormation 或 AWS CLI。 AWS SDKs
要使用批量转换进行批量推理,请指向您的模型构件和输入数据,然后创建批量推理作业。与其托管终端节点进行推理,不如将您的推断 SageMaker输出到您选择的 Amazon S3 位置。
