本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
扩展训练
以下各节介绍了您可能想要扩大训练规模的场景,以及如何使用 AWS 资源来扩大训练规模。在以下情况之一中,您可能需要扩展训练规模:
-
从单个扩展GPU到多个 GPUs
-
从单个实例扩展到多个实例
-
使用自定义训练脚本
从单个扩展GPU到多个 GPUs
根据机器学习中使用的数据量或模型的大小,可能会出现训练模型的时间超过您愿意等待的时间的情况。有时,由于模型或训练数据太大,训练可能完全无法正常工作。一种解决方案是增加用于训练GPUs的数量。 在具有多个实例上GPUs,例如p3.16xlarge具有八个的实例GPUs,数据和处理将分成八个GPUs。当您使用分布式训练库时,这可以为您训练模型所用的时间带来近乎线性的加速。它所花的时间略高于p3.2xlarge使用一个GPU所花费的时间的 1/8。
| 实例类型 | GPUs |
|---|---|
| p3.2xlarge | 1 |
| p3.8xlarge | 4 |
| p3.16xlarge | 8 |
| p3dn.24xlarge | 8 |
注意
SageMaker 训练使用的 ml 实例类型的GPUs数量与相应的 p3 实例类型相同。例如,ml.p3.8xlarge具有与 p3.8xlarge -4 GPUs 相同的数字。
从单个实例扩展到多个实例
如果您想进一步扩展训练,则可以使用更多的实例。但是,您应先考虑选择更大的实例类型,然后再考虑添加更多实例。查看上表,了解每个 p3 实例类型GPUs中有多少个。
如果您已经从 a GPU 上的单跳p3.2xlarge到 a GPUs 上的四个p3.8xlarge,但决定需要更高的处理能力,那么如果您在尝试增加实例数量p3.16xlarge之前选择 a,则可能会看到更好的性能并降低成本。根据您使用的库,保持在单个实例上进行训练时,相比使用多个实例的场景性能会更好,成本也更低。
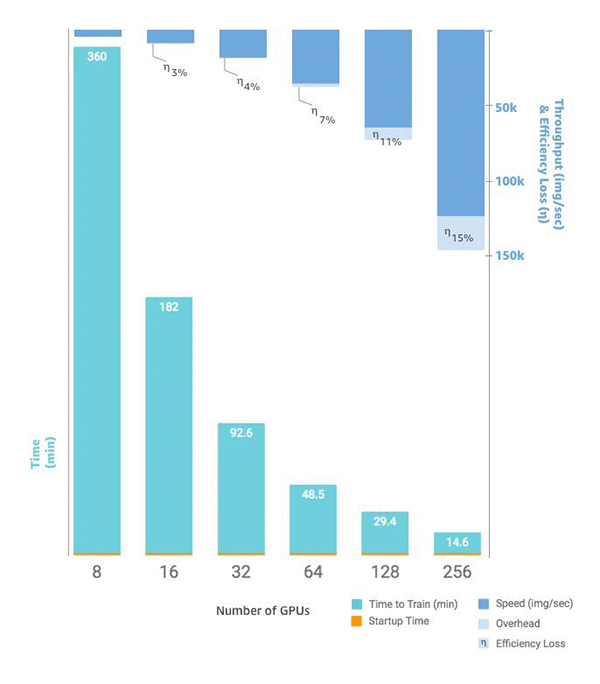
当你准备好扩展实例数量时,你可以通过设置 SageMaker Python SDK estimator 函数来实现这一点instance_count。例如,您可以创建 instance_type = p3.16xlarge 和 instance_count =
2。在两个相同的实例中p3.16xlarge,你有16 GPUs 个,而不是单个实例GPUs上的八个。下图显示了扩展和吞吐量,从单个实例GPUs上的 8 个开始
自定义训练脚本
虽然可以 SageMaker 轻松部署和扩展实例数量GPUs,但根据您选择的框架,管理数据和结果可能非常困难,这就是经常使用外部支持库的原因。 这种最基本的分布式训练形式需要修改训练脚本来管理数据分布。
SageMaker 还支持 Horovod 和每个主要深度学习框架原生的分布式训练的实现。如果您选择使用这些框架中的示例,则可以遵循深度学习容器指南 D SageMaker eep Learning Containers 以及演示实现的各种示例笔记本
