本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
使用 Amazon A SageMaker I 创建模型 ModelBuilder
准备模型以便在 A SageMaker I 终端节点上部署需要多个步骤,包括选择模型映像、设置终端节点配置、对序列化和反序列化函数进行编码以在服务器和客户端之间传输数据、识别模型依赖关系以及将其上传到 Amazon S3。 ModelBuilder可以降低初始设置和部署的复杂性,帮助您一步创建可部署的模型。
ModelBuilder 可以为您执行以下任务:
只需一步即可将使用各种框架(如 XGBoost 或 PyTorch )训练的机器学习模型转换为可部署的模型。
根据模型框架自动选择容器,因此无需手动指定容器。您仍然可以通过向
ModelBuilder传递自己的 URI 来使用自己的容器。在将数据发送到服务器进行推理和反序列化服务器返回的结果之前,先处理客户端的数据序列化。数据格式正确,无需手动处理。
启用自动捕获依赖关系并根据模型服务器的预期对模型进行打包。
ModelBuilder的自动捕获依赖关系是一种尽力动态加载依赖关系的方法。(我们建议您在本地测试自动捕获,并更新依赖关系以满足您的需求。)对于大型语言模型 (LLM) 用例,可以选择对服务属性执行本地参数调整,这些属性可以在托管在 SageMaker AI 端点上时部署以提高性能。
支持大多数流行的模型服务器和容器 TorchServe,例如 Triton DJLServing 和 TGI 容器。
使用以下方法构建您的模型 ModelBuilder
ModelBuilder是一个 Python 类,它采用框架模型(例如 XGBoost 或 PyTorch)或用户指定的推理规范,并将其转换为可部署的模型。 ModelBuilder提供了生成要部署的工件的生成功能。生成的模型构件是特定于模型服务器的,您也可以将其指定为输入之一。有关该ModelBuilder课程的更多详细信息,请参阅ModelBuilder
下图说明了使用 ModelBuilder 时创建模型的整体工作流程。ModelBuilder 采用模型或推理规范以及架构,以创建可在部署之前在本地测试的可部署模型。
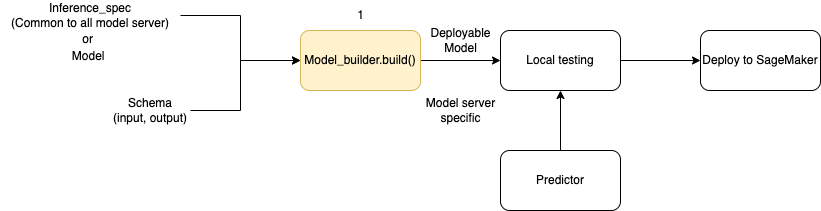
ModelBuilder 可以处理您想要应用的任何自定义功能。但是,要部署框架模型,模型构建器至少需要模型、输入和输出示例以及角色。在下面的代码示例中,调用 ModelBuilder 时使用了一个框架模型和一个具有最小参数的 SchemaBuilder 的实例(以推理出用于序列化和反序列化端点输入和输出的相应函数)。未指定容器,也未传递任何打包的依赖关系 — SageMaker AI 会在您构建模型时自动推断出这些资源。
from sagemaker.serve.builder.model_builder import ModelBuilder from sagemaker.serve.builder.schema_builder import SchemaBuilder model_builder = ModelBuilder( model=model, schema_builder=SchemaBuilder(input, output), role_arn="execution-role", )
下面的代码示例调用了具有推理规范的 ModelBuilder(作为 InferenceSpec 实例),而不是模型,并进行了额外的自定义。在这种情况下,对模型构建器的调用包括一个存储模型构件的路径,同时还会开启所有可用依赖关系的自动捕获。有关 InferenceSpec 的其他详细信息,请参阅 自定义模型加载和请求处理。
model_builder = ModelBuilder( mode=Mode.LOCAL_CONTAINER, model_path=model-artifact-directory, inference_spec=your-inference-spec, schema_builder=SchemaBuilder(input, output), role_arn=execution-role, dependencies={"auto": True} )
定义序列化和反序列化方法
调用 SageMaker AI 端点时,数据通过具有不同 MIME 类型的 HTTP 负载发送。例如,发送到端点进行推理的映像需要在客户端转换为字节,然后通过 HTTP 有效载荷发送到端点。端点收到有效载荷后,需要将字节字符串反序列化为模型所期望的数据类型(也称为服务器端反序列化)。模型完成预测后,还需要将结果序列化为字节,通过 HTTP 有效载荷发送回用户或客户端。客户端收到响应字节数据后,需要执行客户端反序列化,将字节数据转换回预期的数据格式,例如 JSON。您至少需要将数据转换为以下任务:
推理请求序列化(由客户端处理)
推理请求反序列化(由服务器或算法处理)
针对有效载荷调用模型并发回响应有效载荷
推理响应序列化(由服务器或算法处理)
推理响应反序列化(由您处理)
下图显示了调用端点时发生的序列化和反序列化过程。
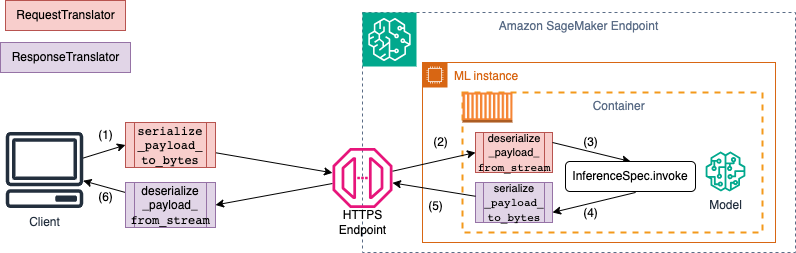
当您向 SchemaBuilder 提供输入和输出示例时,架构构建器会生成相应的编组函数,用于序列化和反序列化输入和输出。您可以使用 CustomPayloadTranslator 进一步自定义序列化函数。但在大多数情况下,像下面这样的简单序列化器也是可行的:
input = "How is the demo going?" output = "Comment la démo va-t-elle?" schema = SchemaBuilder(input, output)
有关的更多详细信息SchemaBuilder,请参阅SchemaBuilder
下面的代码片段概述了一个示例,在此示例中,您想要在客户端和服务器端自定义序列化和反序列化函数。您可以使用 CustomPayloadTranslator 定义自己的请求和响应转换器,并将这些翻译器传递给 SchemaBuilder。
通过将输入和输出包含在转换器中,模型构建器可以提取模型所需的数据格式。例如,假设样本输入是原始映像,您的自定义转换器会裁剪映像,并将裁剪后的映像作为张量发送到服务器。ModelBuilder 需要原始输入和任何自定义预处理或后处理代码,以推导出在客户端和服务器端转换数据的方法。
from sagemaker.serve import CustomPayloadTranslator # request translator class MyRequestTranslator(CustomPayloadTranslator): # This function converts the payload to bytes - happens on client side def serialize_payload_to_bytes(self, payload: object) -> bytes: # converts the input payload to bytes ... ... return //return object as bytes # This function converts the bytes to payload - happens on server side def deserialize_payload_from_stream(self, stream) -> object: # convert bytes to in-memory object ... ... return //return in-memory object # response translator class MyResponseTranslator(CustomPayloadTranslator): # This function converts the payload to bytes - happens on server side def serialize_payload_to_bytes(self, payload: object) -> bytes: # converts the response payload to bytes ... ... return //return object as bytes # This function converts the bytes to payload - happens on client side def deserialize_payload_from_stream(self, stream) -> object: # convert bytes to in-memory object ... ... return //return in-memory object
在创建 SchemaBuilder 对象时,您可以将输入和输出示例以及先前定义的自定义转换器起传入,如以下示例所示:
my_schema = SchemaBuilder( sample_input=image, sample_output=output, input_translator=MyRequestTranslator(), output_translator=MyResponseTranslator() )
然后,将输入和输出示例以及之前定义的自定义转换器传递给 SchemaBuilder 对象。
my_schema = SchemaBuilder( sample_input=image, sample_output=output, input_translator=MyRequestTranslator(), output_translator=MyResponseTranslator() )
以下各节将详细介绍如何使用 ModelBuilder 构建模型,并使用其支持类来自定义使用体验。
自定义模型加载和请求处理
通过 InferenceSpec 提供自己的推理代码,还能提供额外的自定义功能。通过 InferenceSpec,您可以绕过模型的默认加载和推理处理机制,自定义模型的加载方式以及如何处理传入的推理请求。在使用非标准模型或自定义推理管道时,这种灵活性尤为有益。您可以自定义 invoke 方法,以控制模型如何预处理和后处理传入的请求。invoke 方法可确保模型正确处理推理请求。以下示例InferenceSpec使用 HuggingFace 管道生成模型。有关的更多详细信息InferenceSpec,请参阅InferenceSpec
from sagemaker.serve.spec.inference_spec import InferenceSpec from transformers import pipeline class MyInferenceSpec(InferenceSpec): def load(self, model_dir: str): return pipeline("translation_en_to_fr", model="t5-small") def invoke(self, input, model): return model(input) inf_spec = MyInferenceSpec() model_builder = ModelBuilder( inference_spec=your-inference-spec, schema_builder=SchemaBuilder(X_test, y_pred) )
下面的示例是对前一个示例的更个性化的修改。模型是通过具有依赖关系的推理规范定义的。在这种情况下,推理规范中的代码依赖于 lang-segment 软件包。dependencies 的参数包含一条语句,指示构建器使用 Git 安装 lang-segment。由于用户会指示模型构建器自定义安装依赖关系,因此 auto 密钥是 False,用于关闭依赖关系的自动捕获。
model_builder = ModelBuilder( mode=Mode.LOCAL_CONTAINER, model_path=model-artifact-directory, inference_spec=your-inference-spec, schema_builder=SchemaBuilder(input, output), role_arn=execution-role, dependencies={"auto": False, "custom": ["-e git+https://github.com/luca-medeiros/lang-segment-anything.git#egg=lang-sam"],} )
构建模型并部署
调用 build 函数创建可部署模型。此步骤在工作目录中创建推理代码(如 inference.py),其中包含创建架构、运行输入和输出的序列化和反序列化以及运行其他用户指定的自定义逻辑所需的代码。
作为完整性检查, SageMaker AI 会将部署所需的文件打包和封存,作为ModelBuilder构建功能的一部分。在此过程中, SageMaker AI 还会为 pickle 文件创建 HMAC 签名,并在deploy(或create)期间将密钥作为环境变量添加到 CreateModelAPI 中。端点启动使用环境变量来验证 pickle 文件的完整性。
# Build the model according to the model server specification and save it as files in the working directory model = model_builder.build()
使用模型现有的 deploy 方法部署模型。在此步骤中, SageMaker AI 会在开始预测传入请求时设置一个端点来托管您的模型。虽然 ModelBuilder 会推理出部署模型所需的端点资源,但您可以使用自己的参数值覆盖这些估计值。以下示例指示 SageMaker AI 在单个ml.c6i.xlarge实例上部署模型。由 ModelBuilder 构建的模型还能在部署过程中实时记录日志。
predictor = model.deploy( initial_instance_count=1, instance_type="ml.c6i.xlarge" )
如果您想对分配给模型的端点资源进行更精细的控制,可以使用 ResourceRequirements 对象。使用该ResourceRequirements对象,您可以请求要部署的最少数量的模型 CPUs、加速器和副本。您还可以请求内存的最小和最大限制(单位:MB)。要使用此功能,您需要将端点类型指定为 EndpointType.INFERENCE_COMPONENT_BASED。下面的示例请求将四个加速器、最小内存大小 1024 MB 和一个模型副本部署到 EndpointType.INFERENCE_COMPONENT_BASED 类型的端点。
resource_requirements = ResourceRequirements( requests={ "num_accelerators": 4, "memory": 1024, "copies": 1, }, limits={}, ) predictor = model.deploy( mode=Mode.SAGEMAKER_ENDPOINT, endpoint_type=EndpointType.INFERENCE_COMPONENT_BASED, resources=resource_requirements, role="role" )
使用自己的容器 (BYOC)
如果您想自带容器(从 A SageMaker I 容器扩展而来),也可以指定图像 URI,如以下示例所示。您还需要确定与 ModelBuilder 映像对应的模型服务器,以便生成模型服务器特有的构件。
model_builder = ModelBuilder( model=model, model_server=ModelServer.TORCHSERVE, schema_builder=SchemaBuilder(X_test, y_pred), image_uri="123123123123.dkr.ecr.ap-southeast-2.amazonaws.com/byoc-image:xgb-1.7-1") )
ModelBuilder 在本地模式下使用
您可以使用 mode 参数在本地测试和部署到端点之间切换,从而在本地部署模型。您需要将模型构件存储在工作目录中,如以下代码段所示:
model = XGBClassifier() model.fit(X_train, y_train) model.save_model(model_dir + "/my_model.xgb")
传递模型对象、SchemaBuilder 实例,并将模式设置为 Mode.LOCAL_CONTAINER。当您调用 build 函数时,ModelBuilder 会自动识别支持的框架容器并扫描依赖关系。以下示例演示了在局部模式下使用 XGBoost 模型创建模型。
model_builder_local = ModelBuilder( model=model, schema_builder=SchemaBuilder(X_test, y_pred), role_arn=execution-role, mode=Mode.LOCAL_CONTAINER ) xgb_local_builder = model_builder_local.build()
调用 deploy 函数进行本地部署,如以下代码段所示。如果您为实例类型或计数指定参数,则会忽略这些参数。
predictor_local = xgb_local_builder.deploy()
本地模式故障排除
根据您的本地设置,您可能会遇到在您的环境中顺利运行 ModelBuilder 的困难。有关您可能面临的一些问题以及如何解决这些问题,请参阅以下列表。
已在使用:您可能会遇到
Address already in use错误。在这种情况下,可能有一个 Docker 容器正在此端口上运行,或者有其他进程正在使用此端口。您可以按照 Linux 文档中概述的方法来识别进程,并从容地将本地进程从 8080 端口重定向到其他端口,或清理 Docker 实例。 IAM 权限问题:在尝试拉取 Amazon ECR 映像或访问 Amazon S3 时,您可能会遇到权限问题。在这种情况下,请导航到笔记本或 Studio Classic 实例的执行角色,以验证
SageMakerFullAccess策略或相应的 API 权限。EBS 卷容量问题:如果您部署大型语言模型(LLM),则在本地模式下运行 Docker 时可能会耗尽空间,或者遇到 Docker 缓存的空间限制。在这种情况下,您可以尝试将 Docker 卷移动到有足够空间的文件系统上。要移动 Docker 卷,请完成以下步骤:
打开终端并运行
df来显示磁盘使用情况,输出结果如下所示:(python3) sh-4.2$ df Filesystem 1K-blocks Used Available Use% Mounted on devtmpfs 195928700 0 195928700 0% /dev tmpfs 195939296 0 195939296 0% /dev/shm tmpfs 195939296 1048 195938248 1% /run tmpfs 195939296 0 195939296 0% /sys/fs/cgroup /dev/nvme0n1p1 141545452 135242112 6303340 96% / tmpfs 39187860 0 39187860 0% /run/user/0 /dev/nvme2n1 264055236 76594068 176644712 31% /home/ec2-user/SageMaker tmpfs 39187860 0 39187860 0% /run/user/1002 tmpfs 39187860 0 39187860 0% /run/user/1001 tmpfs 39187860 0 39187860 0% /run/user/1000将默认 Docker 目录从移
/dev/nvme0n1p1至,/dev/nvme2n1这样你就可以充分利用 256 GB 的 SageMaker AI 音量。有关更多详细信息,请参阅有关如何移动 Docker 目录的文档。 使用以下命令停止 Docker:
sudo service docker stop在
/etc/docker中添加daemon.json,或将以下 JSON blob 追加到现有 blob 中。{ "data-root": "/home/ec2-user/SageMaker/{created_docker_folder}" }使用以下命令将
/var/lib/docker中的 Docker 目录移至/home/ec2-user/SageMaker AI:sudo rsync -aP /var/lib/docker/ /home/ec2-user/SageMaker/{created_docker_folder}使用以下命令开始 Docker:
sudo service docker start使用以下命令清理垃圾:
cd /home/ec2-user/SageMaker/.Trash-1000/files/* sudo rm -r *如果您使用的是 SageMaker 笔记本实例,则可以按照 Docker 准备文件
中的步骤为本地模式准备 Docker。
ModelBuilder 例子
有关使用ModelBuilder构建模型的更多示例,请参阅ModelBuilder示例笔记本
