本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
IP 洞察的工作方式
Amazon SageMaker AI IP Insights 是一种无监督算法,它以(实体、IPv4地址)对的形式使用观察到的数据,将实体与 IP 地址关联起来。IP 洞察通过学习实体和 IP 地址的潜在向量表示形式,确定实体有多大可能使用特定 IP 地址。然后,这两种表示形式之间的距离可以作为媒介,用来确定这两者之间关联的可能性。
IP 洞察算法使用神经网络来学习实体和 IP 地址的潜在向量表示形式。实体首先被哈希处理为大型但固定的哈希空间,然后由简单嵌入层进行编码。用户名或帐户等字符串IDs可以直接输入到日志文件中显示的 IP Insights。您无需预处理实体标识符的数据。在训练和推理期间,您可以将实体作为任意字符串值提供。哈希大小应配置一个足够高的值,以确保当不同的实体映射到同一潜在向量时,发生的碰撞数无足轻重。有关如何选择适当的哈希大小的详细信息,请参阅适用于大规模多任务学习的特征哈希
在训练期间,IP 洞察通过随机配对实体和 IP 地址,自动生成负样本。这些负样本代表实际上不太可能出现的数据。模型接受训练,用来区分在训练数据中观察到的正样本和这些生成的负样本。更具体地说,模型训练是为了尽量减少交叉熵,也称为日志丢失,定义如下:
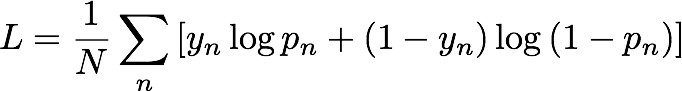
yn 是标签,指示采样是来自主导观察数据的实际分布 (yn=1),还是来自生成负采样的分布 (yn=0)。pn 是从实际分布采样的概率(正如模型预测的那样)。
生成负采样是一个重要的过程,用于实现观察到的数据的准确模型。如果负样本极不可能出现,例如,如果负样本中的所有 IP 地址都是 10.0.0.0,那么模型就可以随意地学会区分负样本,并且无法准确地描述实际观察到的数据集的特征。为了确保负样本更加逼真,IP 洞察通过随机生成 IP 地址和从训练数据中随机选择 IP 地址来生成负样本。您可以使用 random_negative_sampling_rate 和 shuffled_negative_sampling_rate 超参数,配置负样本的类型,以及生成负样本的速率。
给定 n 个(实体,IP 地址对),IP 洞察模型会输出分数 Sn,指示实体与 IP 地址的相容程度。该分数为相对于来自负分布的数据,实际分布值对的给定(实体、IP 地址)的对数差异比。其定义如下:
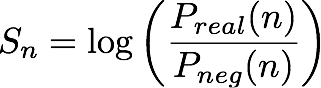
该分数实际上是一个度量,表示第 n 个实体和 IP 地址的向量表示法之间的相似度。它可以解释为在现实中观察到这个事件比在随机生成的数据集中观察到这个事件的可能性要大多少。在训练过程中,算法使用此分数计算样本来自实际分布的概率 pn 的估计值,在交叉熵最小化中使用,其中: