本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
检索增强生成
基础模型通常是离线训练的,这使得模型不了解在模型训练后创建的任何数据。此外,基础模型在非常通用的领域语料库上训练,这使得它们在特定于领域的任务中的效率较低。您可以使用 Retrieive Argented Generation (RAG) 从基础模型之外检索数据,并通过在上下文中添加检索到的相关数据来增强提示。有关RAG模型架构的更多信息,请参阅知识密集型任务的检索增强生成。NLP
使用RAG,用于增强提示的外部数据可以来自多个数据源,例如文档存储库、数据库或APIs。第一步是将您的文档和任何用户查询转换为兼容的格式,以执行相关性搜索。为了使格式兼容,需要使用嵌入式语言模型,将文档集合或知识库以及用户提交的查询转换为数字表示形式。嵌入是在向量空间中对文本进行数字表示的过程。RAG模型架构比较了知识库向量中用户查询的嵌入情况。然后,将知识库中类似文档的相关上下文附加到原始用户提示中。接下来,此增强提示将发送到基础模型。您可以异步更新知识库及其相关嵌入。
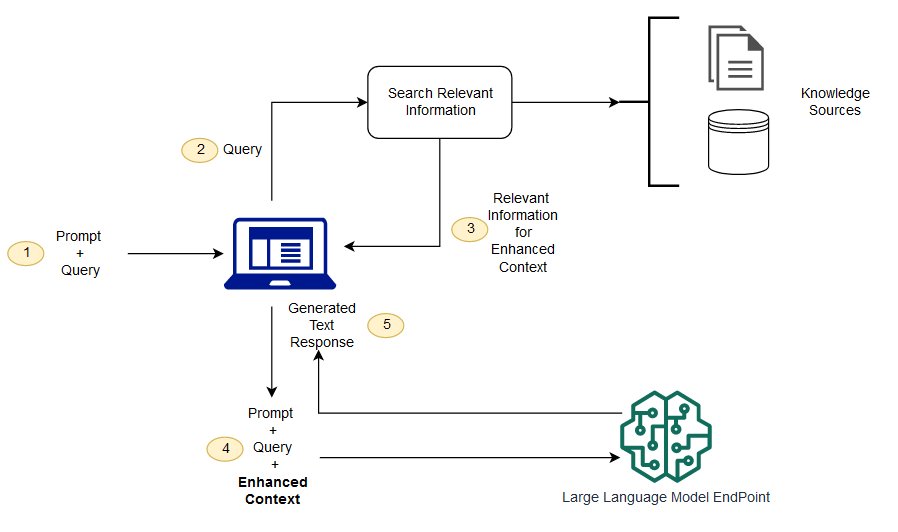
检索到的文档应足够大,以包含有用的上下文以帮助增强提示,但又要足够小,以适应提示的最大序列长度。您可以使用特定于任务的 JumpStart 模型,例如来自的通用文本嵌入 () GTE 模型 Hugging Face,为您的提示和知识库文档提供嵌入内容。在比较提示和文档嵌入以找到最相关的文档之后,使用补充上下文构造一个新的提示。然后,将增强提示传递给您选择的文本生成模型。
示例笔记本
有关RAG基础模型解决方案的更多信息,请参阅以下示例笔记本:
您可以克隆 Amazon SageMaker 示例存储库
