本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
从提供的基本生命周期脚本开始 HyperPod
本节将引导你了解以自上而下的方法开启 Slurm 的基本流程 HyperPod 的每个组成部分。它从准备要运行的 HyperPod 集群创建请求开始 CreateClusterAPI,然后深入研究生命周期脚本的层次结构。使用 Awsome 分布式训练 GitHub 存储库
git clone https://github.com/aws-samples/awsome-distributed-training/
用于在上设置 Slurm 集群的基本生命周期脚本 SageMaker HyperPod 可在中找到。1.architectures/5.sagemaker_hyperpods/LifecycleScripts/base-config
cd awsome-distributed-training/1.architectures/5.sagemaker_hyperpods/LifecycleScripts/base-config
以下流程图详细概述了应如何设计基本生命周期脚本。图表下方的描述和程序指南解释了它们在 HyperPod CreateClusterAPI通话期间的工作原理。
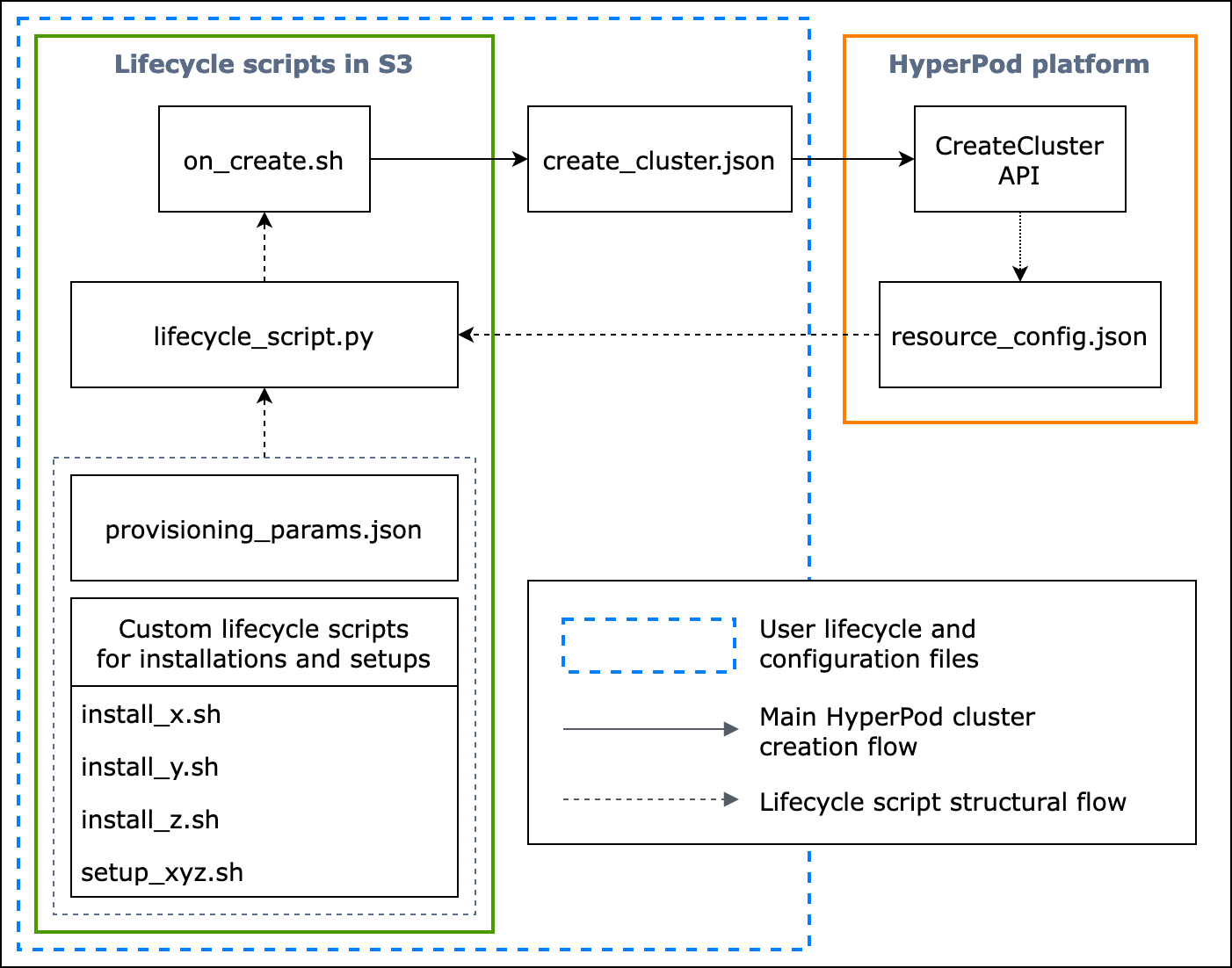
图: HyperPod 集群创建和生命周期脚本结构的详细流程图。(1) 虚线箭头指向方框 “调入” 的位置,显示配置文件和生命周期脚本的准备流程。它从准备脚本provisioning_parameters.json和生命周期脚本开始。然后对它们进行编码,lifecycle_script.py以便按顺序进行集体执行。lifecycle_script.py脚本的执行由 on_create.sh shell 脚本完成,该脚本将在 HyperPod实例终端中运行。(2) 实心箭头显示了主 HyperPod 集群的创建流程以及方框是如何 “调入” 或 “提交给” 的。 on_create.sh是创建集群请求的必填项,可以在控制台用户界面中的创建集群请求表中找到。create_cluster.json提交请求后,CreateClusterAPI根据请求和生命周期脚本中的给定配置信息 HyperPod 运行。(3) 虚线箭头表示 HyperPod 平台在集群资源配置期间resource_config.json在集群中创建的实例。 resource_config.json包含 HyperPod 群集资源信息,例如群集ARN、实例类型和 IP 地址。请务必注意,在创建集群期间,您应该准备好生命周期脚本,resource_config.json以备不时之需。有关更多信息,请参阅下面的程序指南。
以下程序指南解释了 HyperPod 集群创建期间发生的事情以及基本生命周期脚本是如何设计的。
-
create_cluster.json— 要提交 HyperPod集群创建请求,您需要准备JSON格式的CreateCluster请求文件。在此最佳实践示例中,我们假设请求文件已命名create_cluster.json。写信create_cluster.json给集 HyperPod 群配置实例组。最佳做法是添加与您计划在集群上配置的 Slurm 节点数量相同的实例组。 HyperPod 确保为要分配给计划设置的 Slurm 节点的实例组指定唯一的名称。此外,您还需要指定 S3 存储桶路径,以将整组配置文件和生命周期脚本存储到
CreateCluster请求表单InstanceGroups.LifeCycleConfig.SourceS3Uri中的字段名,并将入口点 shell 脚本的文件名(假设已命名on_create.sh)指定到。InstanceGroups.LifeCycleConfig.OnCreate注意
如果您在 HyperPod 控制台用户界面中使用创建集群提交表单,则控制台会代表您管理填写和提交
CreateCluster请求,并在后端运行。CreateClusterAPI在这种情况下,您无需创建create_cluster.json;相反,请确保在 “创建集群” 提交表单中指定了正确的集群配置信息。 -
on_create.sh— 对于每个实例组,您需要提供一个入口点 shell 脚本,以运行命令on_create.sh、运行脚本来安装软件包,以及使用 Slurm 设置 HyperPod集群环境。您需要准备的两件事是设置 Slurm 所provisioning_parameters.jsonHyperPod 必需的,以及一组用于安装软件包的生命周期脚本。编写此脚本是为了查找和运行以下文件,如中的示例脚本所示on_create.sh。 注意
确保将整组生命周期脚本上传到您在中指定的 S3 位置
create_cluster.json。你还应该把你的provisioning_parameters.json放在同一个位置。-
provisioning_parameters.json— 这是一个用于在上配置 Slurm 节点的配置表 HyperPod. 该on_create.sh脚本会找到此JSON文件并定义用于标识其路径的环境变量。通过此JSON文件,你可以配置 Slurm 节点和要与之通信的存储选项,例如 Ama FSx zon for Lustre for Slurm。在中provisioning_parameters.json,请确保根据计划设置方式,使用您在中create_cluster.json指定的名称将 HyperPod 集群实例组适当地分配给 Slurm 节点。下图显示了如何编写两个JSON配置文件
create_cluster.json和provisioning_parameters.json以将 HyperPod 实例组分配给 Slurm 节点的示例。在此示例中,我们假设设置了三个 Slurm 节点:控制器(管理)节点、登录节点(可选)和计算(工作节点)。提示
为了帮助您验证这两个JSON文件, HyperPod服务团队提供了一个验证脚本
validate-config.py。要了解更多信息,请参阅 在上创建 Slurm 集群之前验证JSON配置文件 HyperPod。 
图: HyperPod集群创建和 Slurm 配置之间的
create_cluster.json直接比较。provisiong_params.json中的实例组数量create_cluster.json应与您要配置为 Slurm 节点的节点数量相匹配。对于图中的示例,将在由三个实例组组组成的 HyperPod 集群上配置三个 Slurm 节点。您应通过相应地指定实例组名称将 HyperPod 集群实例组分配给 Slurm 节点。 -
resource_config.json— 在创建集群期间,编写lifecycle_script.py脚本是为了期望有来自的resource_config.json文件 HyperPod。此文件包含有关集群的信息,例如实例类型和 IP 地址。运行时
CreateClusterAPI, HyperPod会/opt/ml/config/resource_config.json根据该文件在上创建一个资源配置create_cluster.json文件。文件路径保存到名为的环境变量中SAGEMAKER_RESOURCE_CONFIG_PATH。重要
该
resource_config.json文件由 HyperPod 平台自动生成,NOT您需要创建它。以下代码将显示一个示例resource_config.json,说明将根据上create_cluster.json一步创建的集群进行创建,并帮助您了解后端会发生什么以及自动生成的resource_config.json会是什么样子。{ "ClusterConfig": { "ClusterArn": "arn:aws:sagemaker:us-west-2:111122223333:cluster/abcde01234yz", "ClusterName": "your-hyperpod-cluster" }, "InstanceGroups": [ { "Name": "controller-machine", "InstanceType": "ml.c5.xlarge", "Instances": [ { "InstanceName": "controller-machine-1", "AgentIpAddress": "111.222.333.444", "CustomerIpAddress": "111.222.333.444", "InstanceId": "i-12345abcedfg67890" } ] }, { "Name": "login-group", "InstanceType": "ml.m5.xlarge", "Instances": [ { "InstanceName": "login-group-1", "AgentIpAddress": "111.222.333.444", "CustomerIpAddress": "111.222.333.444", "InstanceId": "i-12345abcedfg67890" } ] }, { "Name": "compute-nodes", "InstanceType": "ml.trn1.32xlarge", "Instances": [ { "InstanceName": "compute-nodes-1", "AgentIpAddress": "111.222.333.444", "CustomerIpAddress": "111.222.333.444", "InstanceId": "i-12345abcedfg67890" }, { "InstanceName": "compute-nodes-2", "AgentIpAddress": "111.222.333.444", "CustomerIpAddress": "111.222.333.444", "InstanceId": "i-12345abcedfg67890" }, { "InstanceName": "compute-nodes-3", "AgentIpAddress": "111.222.333.444", "CustomerIpAddress": "111.222.333.444", "InstanceId": "i-12345abcedfg67890" }, { "InstanceName": "compute-nodes-4", "AgentIpAddress": "111.222.333.444", "CustomerIpAddress": "111.222.333.444", "InstanceId": "i-12345abcedfg67890" } ] } ] } -
lifecycle_script.py— 这是主要 Python 脚本,它在配置时共同运行在 HyperPod 集群上设置 Slurm 的生命周期脚本。此脚本读取中provisioning_parameters.json指定或标识的路径on_create.sh,将相关信息传递给每个生命周期脚本,然后按顺序运行生命周期脚本。resource_config.json生命周期脚本是一组脚本,您可以完全灵活地对其进行自定义,以便在集群创建期间安装软件包并设置必要的或自定义配置,例如设置 Slurm、创建用户、安装 Conda 或 Docker。该示例
lifecycle_script.py脚本已准备好在存储库中运行其他基本生命周期脚本,例如启动 Slurm deamons () start_slurm.sh、安装 Ama FSx zon for Lustre ( mount_fsx.sh) 以及设置 MariaDB 会计 () 和记账 ()。 setup_mariadb_accounting.shRDSsetup_rds_accounting.sh您还可以添加更多脚本,将它们打包到同一个目录下,然后向中添加代码行 lifecycle_script.py以让脚本 HyperPod 运行。有关基本生命周期脚本的更多信息,另请参阅 Awsome Distributed Training GitHub 存储库中的 3.1 生命周期脚本。 注意
HyperPod 在群集的每个实例SageMaker HyperPod DLAMI上运行,AMI并且预先安装的软件包符合它们与功能之间的兼容性。 HyperPod请注意,如果您重新安装任何预安装的软件包,则需要负责安装兼容的软件包,并且请注意,某些 HyperPod 功能可能无法按预期运行。
除了默认设置外,该
utils文件夹下还有更多用于安装以下软件的脚本。该 lifecycle_script.py文件已经准备好包含用于运行安装脚本的代码行,因此请参阅以下项目来搜索这些行并取消注释以激活它们。-
以下代码行用于安装 Docker
、Enroot 和 Pyxis。 这些软件包是在 Slurm 集群上运行 Docker 容器所必需的。 要启用此安装步骤,请在
config.py文件 True中将enable_docker_enroot_pyxis参数设置为。# Install Docker/Enroot/Pyxis if Config.enable_docker_enroot_pyxis: ExecuteBashScript("./utils/install_docker.sh").run() ExecuteBashScript("./utils/install_enroot_pyxis.sh").run(node_type) -
您可以将集 HyperPod 群与适用于 Prometheus 的亚马逊托管服务和 Amazon Managed Grafana 集成,将有关 HyperPod集群和集群节点的指标导出到亚马逊托管 Grafana 控制面板。要导出指标并使用 Amazon Managed Grafana 上的 Slurm
控制面板、导出NVIDIADCGM器 控制面板和EFA指标控制面板 ,您需要安装 Prometheus 的 Slurm 导出器、导出器和节点 导出器。NVIDIA DCGM EFA 有关在亚马逊托管 Grafana 工作空间上安装导出器包和使用 Grafana 控制面板的更多信息,请参阅。SageMaker HyperPod 集群资源监控 要启用此安装步骤,请在
config.py文件 True中将enable_observability参数设置为。# Install metric exporting software and Prometheus for observability if Config.enable_observability: if node_type == SlurmNodeType.COMPUTE_NODE: ExecuteBashScript("./utils/install_docker.sh").run() ExecuteBashScript("./utils/install_dcgm_exporter.sh").run() ExecuteBashScript("./utils/install_efa_node_exporter.sh").run() if node_type == SlurmNodeType.HEAD_NODE: wait_for_scontrol() ExecuteBashScript("./utils/install_docker.sh").run() ExecuteBashScript("./utils/install_slurm_exporter.sh").run() ExecuteBashScript("./utils/install_prometheus.sh").run()
-
-
-
确保将步骤 2 中的所有配置文件和安装脚本上传到您在步骤 1 的
CreateCluster请求中提供的 S3 存储桶。例如,假设你create_cluster.json有以下几点。"LifeCycleConfig": { "SourceS3URI": "s3://sagemaker-hyperpod-lifecycle/src", "OnCreate": "on_create.sh" }然后,你
"s3://sagemaker-hyperpod-lifecycle/src"应该包含on_create.shlifecycle_script.py、provisioning_parameters.json、和所有其他安装脚本。假设您已在本地文件夹中准备好文件,如下所示。└── lifecycle_files // your local folder ├── provisioning_parameters.json ├── on_create.sh ├── lifecycle_script.py └── ... // more setup scrips to be fed into lifecycle_script.py要上传文件,请按如下方式使用 S3 命令。
aws s3 cp --recursive./lifecycle_scriptss3://sagemaker-hyperpod-lifecycle/src
