本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
Amazon 中的 RL 环境 SageMaker
Amazon SageMaker RL 使用环境来模仿现实世界的场景。根据环境的当前状态和一个或多个代理采取的操作,模拟器处理操作的影响,并返回接下来的状态和奖励。对于在真实世界中训练代理不能确保安全的情况(例如,飞行无人机),或者强化学习算法需要很长时间才能收敛(例如下象棋)时,模拟器很有用。
下图显示与赛车游戏的模拟器交互的示例。
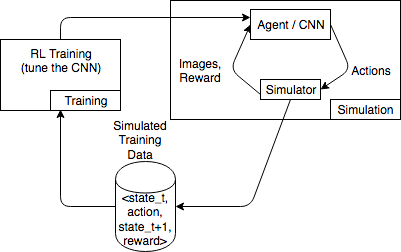
模拟环境包含一个代理和一个模拟器。在这里,卷积神经网络 (CNN) 使用来自模拟器的图像并生成控制游戏控制器的动作。借助多个模拟,此环境生成 state_t、action、state_t+1 和 reward_t+1 格式的训练数据。定义奖励并不是一件小事,会影响到 RL 模型的质量。我们想要提供一些奖励功能的示例,但希望让其可供用户配置。
在 RL 环境中使用 OpenAI Gym 界面 SageMaker
要在 SageMaker RL 中使用 OpenAI Gym 环境,请使用以下元素。API有关 OpenAI Gym 的更多信息,请参阅 Gym 文档
-
env.action_space– 定义代理可采取的操作,指定每项操作是连续还是离散的,并指定操作为连续操作时的最小值和最大值。 -
env.observation_space– 定义代理从环境中收到的观测值,以及连续观测的最小值和最大值。 -
env.reset()– 初始化训练回合。reset()函数返回环境的初始状态,而代理使用初始状态以采取其第一个操作。然后,操作反复发送到step(),直到回合达到最终状态。当step()返回done = True时,此情节结束。RL 工具包通过调用reset()重新初始化环境。 -
step()– 将代理操作作为输入,并输出环境的下一个状态、奖励、回合是否已终止,以及用于传递调试信息的info字典。环境负责验证输入。 -
env.render()– 用于具有可视化功能的环境。RL 工具包在每次调用step()函数后,调用此函数捕获环境的可视化内容。
使用开源环境
您可以通过构建自己的容器在 SageMaker RL 中使用开源环境 RoboSchool,例如 EnergyPlus 和。有关的更多信息 EnergyPlus,请参阅 https://energyplus.net/
使用商业环境
您可以通过构建自己的容器在 SageMaker RL 中使用商业环境,例如MATLAB和 Simulink。您需要管理自己的许可证。
