本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
通过文本分类(单标签)对文本进行分类
要将文章和文本分类为预定义类别,请使用文本分类。例如,您可以使用文本分类来识别评论中传达的情绪或文本部分背后的情绪。使用 Amazon G SageMaker round Truth 文本分类,让工作人员将文本按您定义的类别进行分类。您可以使用 Amazon A SageMaker I 控制台的 Ground Truth 部分或CreateLabelingJob操作创建文本分类标签任务。
重要
如果您手动创建输入清单文件,请使用 "source" 来识别要标注的文本。有关更多信息,请参阅 输入数据。
创建文本分类标注作业(控制台)
您可以按照说明学习创建标注作业(控制台)如何在 SageMaker AI 控制台中创建文本分类标注作业。在步骤 10 中,从任务类别下拉菜单中选择文本,然后选择文本分类(单标签)作为任务类型。
Ground Truth 为标注任务提供类似于以下内容的工作人员 UI。使用控制台创建标注作业时,需要指定说明,以便于工作人员完成工作人员可以从中选择的作业和标签。
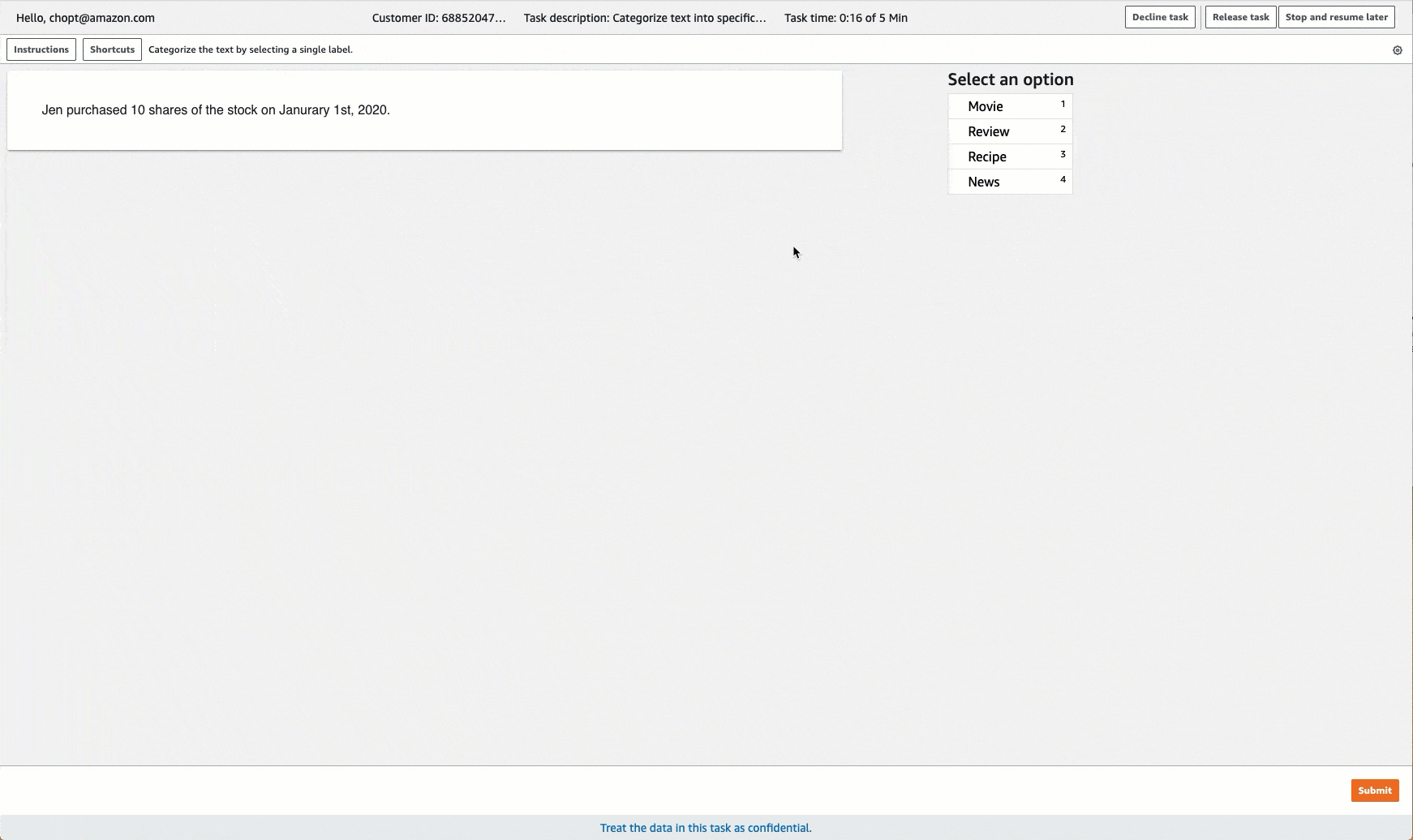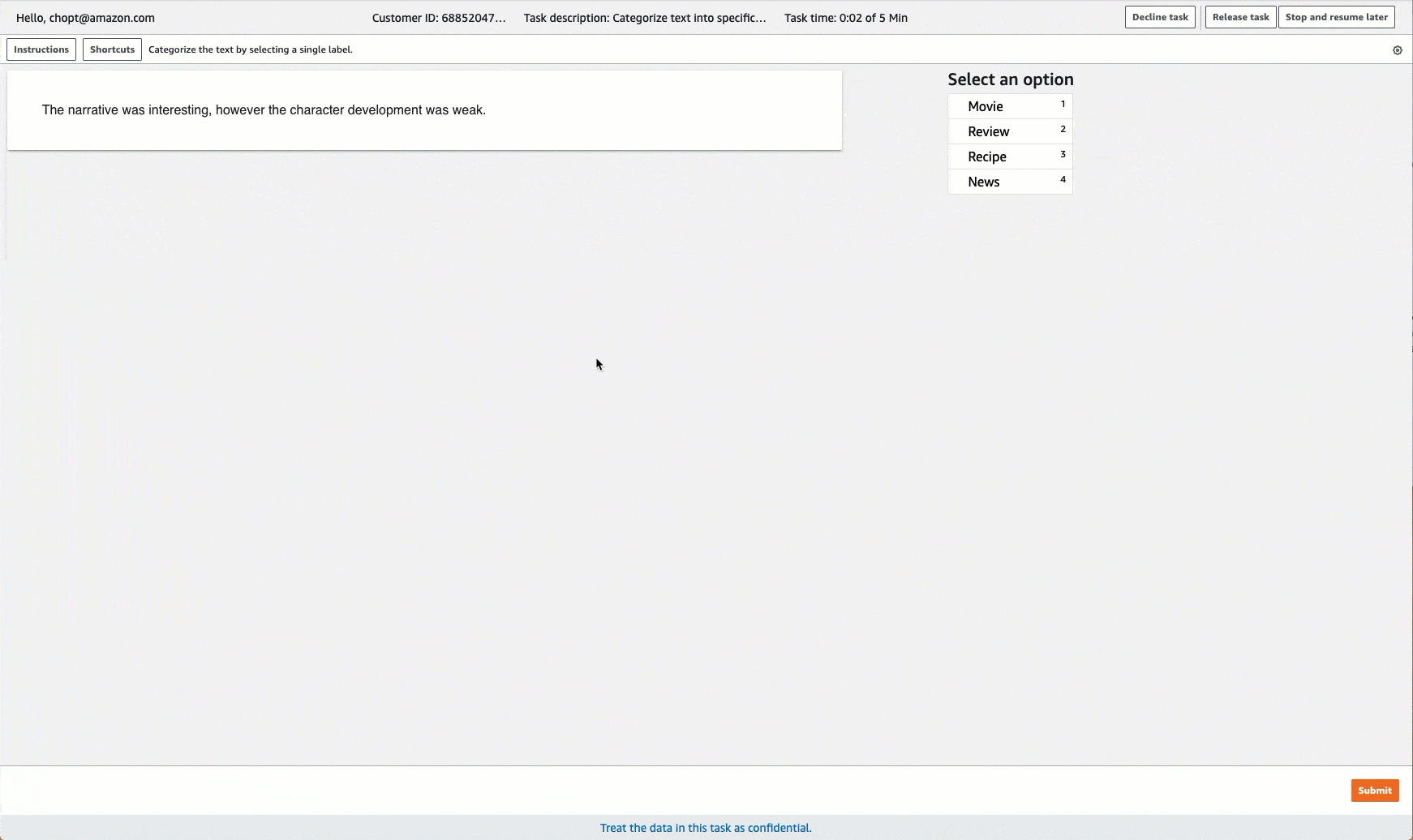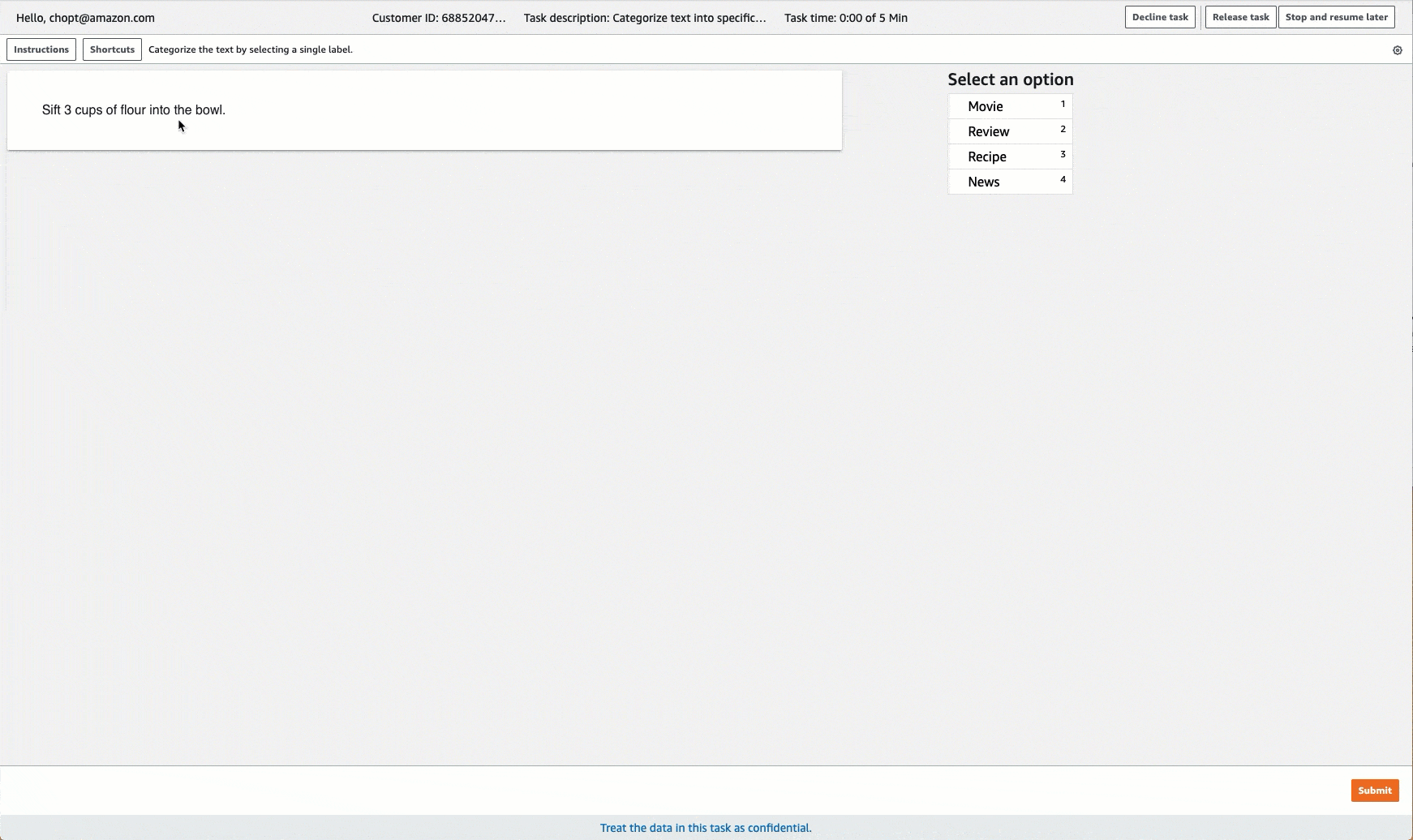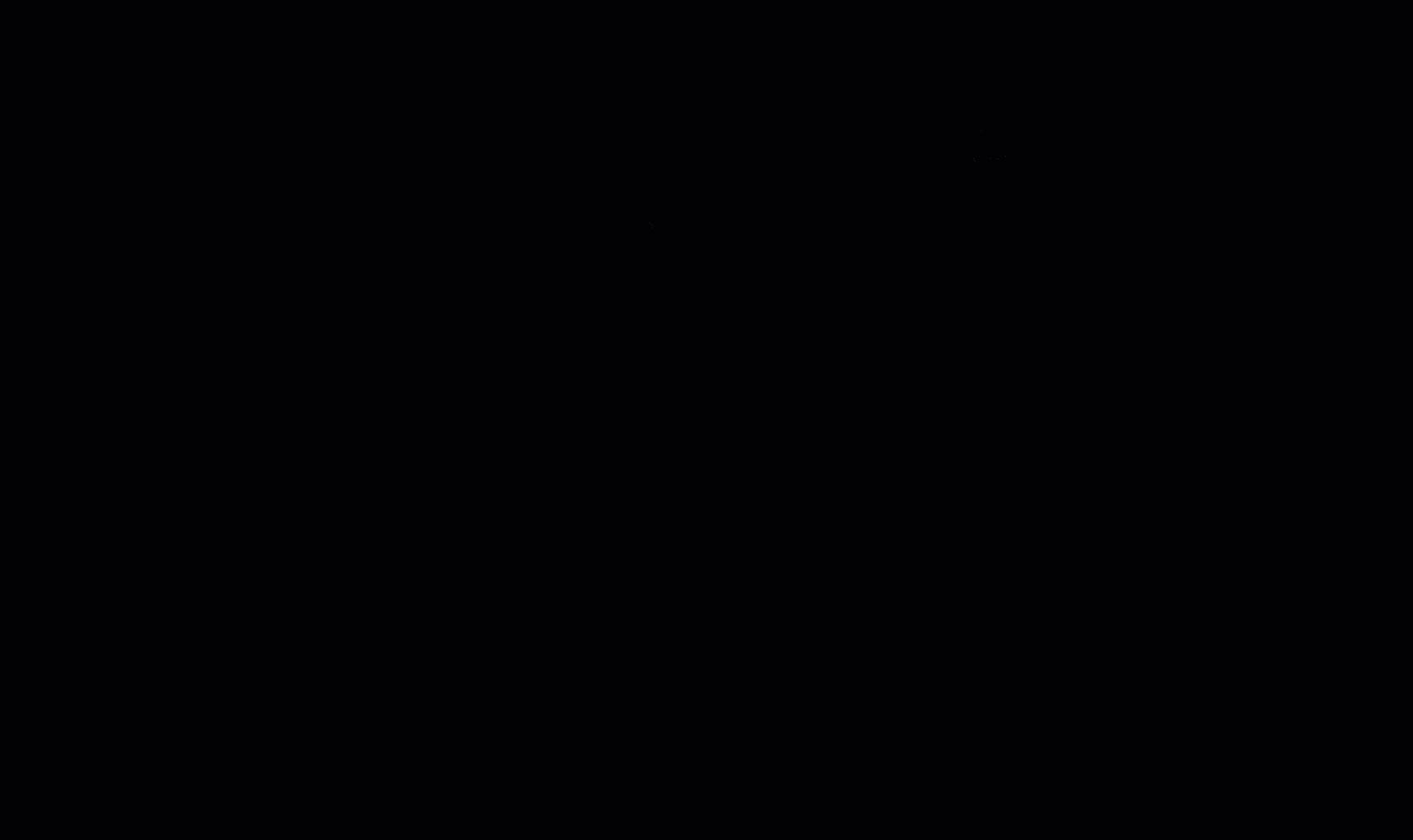
创建文本分类标注作业 (API)
要创建文本分类标注作业,请使用 SageMaker API 操作CreateLabelingJob。此 API 为所有 AWS SDK 定义了此操作。要查看此操作支持的特定于语言的 SDK 列表,请查看 CreateLabelingJob 的另请参阅部分。
请按照创建标注作业 (API)中的说明进行操作,并在配置请求时执行以下操作:
-
Pre-annotation 此任务类型的 Lambda 函数以结尾。
PRE-TextMultiClass要查找您所在地区的预注释 Lambda ARN,请参阅。PreHumanTaskLambdaArn -
Annotation-consolidation 此任务类型的 Lambda 函数以结尾。
ACS-TextMultiClass要查找您所在地区的注释合并 Lambda ARN,请参阅。AnnotationConsolidationLambdaArn
以下是一个 AWS Python SDK (Boto3) 请求
response = client.create_labeling_job( LabelingJobName='example-text-classification-labeling-job, LabelAttributeName='label', InputConfig={ 'DataSource': { 'S3DataSource': { 'ManifestS3Uri':'s3://bucket/path/manifest-with-input-data.json'} }, 'DataAttributes': { 'ContentClassifiers': ['FreeOfPersonallyIdentifiableInformation'|'FreeOfAdultContent', ] } }, OutputConfig={ 'S3OutputPath':'s3://bucket/path/file-to-store-output-data', 'KmsKeyId':'string'}, RoleArn='arn:aws:iam::*:role/*, LabelCategoryConfigS3Uri='s3://bucket/path/label-categories.json', StoppingConditions={ 'MaxHumanLabeledObjectCount':123, 'MaxPercentageOfInputDatasetLabeled':123}, HumanTaskConfig={ 'WorkteamArn':'arn:aws:sagemaker:region:*:workteam/private-crowd/*', 'UiConfig': { 'UiTemplateS3Uri':'s3://bucket/path/worker-task-template.html'}, 'PreHumanTaskLambdaArn': 'arn:aws:lambda:us-east-1:432418664414:function:PRE-TextMultiClass, 'TaskKeywords': [Text classification', ], 'TaskTitle':Text classification task', 'TaskDescription':'Carefully read and classify this text using the categories provided.', 'NumberOfHumanWorkersPerDataObject':123, 'TaskTimeLimitInSeconds':123, 'TaskAvailabilityLifetimeInSeconds':123, 'MaxConcurrentTaskCount':123, 'AnnotationConsolidationConfig': { 'AnnotationConsolidationLambdaArn': 'arn:aws:lambda:us-east-1:432418664414:function:ACS-TextMultiClass' }, Tags=[ { 'Key':'string', 'Value':'string'}, ] )
为文本分类标注作业提供模板
如果要使用 API 创建标注作业,必须在 UiTemplateS3Uri 中提供工作人员任务模板。复制并修改以下模板。仅修改 short-instructions、full-instructions 和 header。
将此模板上传到 S3,并在 UiTemplateS3Uri 中为此文件提供 S3 URI。
<script src="https://assets.crowd.aws/crowd-html-elements.js"></script> <crowd-form> <crowd-classifier name="crowd-classifier" categories="{{ task.input.labels | to_json | escape }}" header="classify text" > <classification-target style="white-space: pre-wrap"> {{ task.input.taskObject }} </classification-target> <full-instructions header="Classifier instructions"> <ol><li><strong>Read</strong> the text carefully.</li> <li><strong>Read</strong> the examples to understand more about the options.</li> <li><strong>Choose</strong> the appropriate labels that best suit the text.</li></ol> </full-instructions> <short-instructions> <p>Enter description of the labels that workers have to choose from</p> <p><br></p><p><br></p><p>Add examples to help workers understand the label</p> <p><br></p><p><br></p><p><br></p><p><br></p><p><br></p> </short-instructions> </crowd-classifier> </crowd-form>
文本分类输出数据
创建文本分类标注作业后,输出数据将位于使用 API 时在 S3OutputPath 参数中指定的 Amazon S3 存储桶中,或者位于控制台的作业概览部分的输出数据集位置字段中。
要了解有关 Ground Truth 生成的输出清单文件以及 Ground Truth 用来存储输出数据的文件结构的更多信息,请参阅标注作业输出数据。
要查看来自文本分类标注作业的输出清单文件示例,请参阅分类作业输出。
