本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
快速入门:创建 A SageMaker I 沙盒域以在 Studio 中启动 Amazon EMR 集群
本节将引导您完成在 Amazon SageMaker Studio 中快速设置完整测试环境的过程。您将创建一个新的 Studio 域,让用户可以直接从 Studio 启动新的 Amazon EMR 集群。这些步骤提供了一个示例笔记本,您可以将其连接到 Amazon EMR 集群以开始运行 Spark 工作负载。使用此笔记本,您将使用 Amazon EMR Spark 分布式处理 OpenSearch 和矢量数据库构建检索增强生成系统 (RAG)。
注意
要开始使用,请使用具有管理员权限的 AWS Identity and Access Management (IAM) 用户账户登录 AWS 管理控制台。有关如何注册 AWS 账户并创建具有管理权限的用户的信息,请参阅 完成 Amazon A SageMaker I 先决条件。
设置 Studio 测试环境并开始运行 Spark 工作:
第 1 步:创建用于在 Studio 中启动亚马逊 EMR 集群的 A SageMaker I 域
在以下步骤中,您将应用 AWS CloudFormation 堆栈来自动创建新的 SageMaker AI 域。堆栈还会创建用户配置文件,并配置所需的环境和权限。 SageMaker AI 域配置为允许您直接从 Studio 启动亚马逊 EMR 集群。在本示例中,Amazon EMR 集群是在与 A SageMaker I 相同的 AWS
账户中创建的,无需身份验证。你可以在 getting_start AWS CloudFormation ing_started 存储库中找到支持各种身份验证方法的其他堆栈,比如 Kerberos。
注意
SageMaker 默认情况下,AI 允许每个 AWS 账户使用 5 个 Studio 域名。 AWS 区域 在创建堆栈之前,请确保您的账户在您所在区域的域数不超过 4 个。
按照以下步骤设置用于从 Studio 启动亚马逊 EMR 集群的 Amazon EMR 集群的 A SageMaker I 域。
-
从
sagemaker-studio-emrGitHub存储库下载此AWS CloudFormation 模板的原始文件。 -
进入 AWS CloudFormation 控制台:https://console.aws.amazon.com/
cloudformation -
选择创建堆栈,并从下拉菜单中选择使用新资源(标准)。
-
在步骤 1 中:
-
在准备模板部分,选择选择现有模板。
-
在指定模板部分,选择上传模板文件。
-
上传下载的 AWS CloudFormation 模板并选择 “下一步”。
-
-
在步骤 2 中,输入堆栈名称,SageMakerDomainName然后选择 Ne xt。
-
在步骤 3 中,保留所有默认值并选择下一步。
-
在步骤 4 中,选中确认资源创建的复选框,然后选择创建堆栈。这将在您的账户和区域中创建一个 Studio 域。
步骤 2:从 Studio UI 启动新的 Amazon EMR 集群
在以下步骤中,您将从 Studio UI 创建一个新的 Amazon EMR 集群。
-
前往 SageMaker AI 控制台 https://console.aws.amazon.com/sagemaker/
,在左侧菜单中选择 “域名”。 -
点击您的域名生成器AIDomain以打开域名详情页面。
-
从用户配置文件
genai-user启动 Studio。 -
在左侧导航窗格中,转到数据然后转到 Amazon EMR 集群。
-
在 Amazon EMR 集群页面上,选择创建。选择堆栈创建的 SageMaker Studio Domain No Auth EMR 模板 AWS CloudFormation ,然后选择 “下一步”。
-
输入新 Amazon EMR 集群的名称。可选择更新其他参数,如核心节点和主节点的实例类型、空闲超时或核心节点数量。
-
选择创建资源,启动新的 Amazon EMR 集群。
创建 Amazon EMR 集群后,请查看 EMR 集群页面上的状态。当状态更改为
Running/Waiting时,您的 Amazon EMR 集群就可以在 Studio 中使用了。
第 3 步:将 JupyterLab 笔记本电脑连接到 Amazon EMR 集群
在以下步骤中 JupyterLab ,您将笔记本连接到正在运行的 Amazon EMR 集群。在本示例中,您导入了一个笔记本,允许您使用 Amazon EMR Spark 分布式处理 OpenSearch 和矢量数据库构建检索增强生成 (RAG) 系统。
-
启动 JupyterLab
在 Studio 中,启动 JupyterLab 应用程序。
-
创建专用空间
如果您尚未为 JupyterLab 应用程序创建空间,请选择创建 JupyterLab 空间。输入空间名称,并将空间保留为专用。将所有其他设置保留为默认值,然后选择创建空间。
否则,请运行您的 JupyterLab 空间来启动 JupyterLab应用程序。
-
部署 LLM 和嵌入模型进行推理
-
从顶部菜单中选择文件、新建,然后选择 终端。
-
在终端运行以下命令。
wget --no-check-certificate https://raw.githubusercontent.com/aws-samples/sagemaker-studio-foundation-models/main/lab-00-setup/Lab_0_Warm_Up_Deploy_EmbeddingModel_Llama2_on_Nvidia.ipynb mkdir AWSGuides cd AWSGuides wget --no-check-certificate https://raw.githubusercontent.com/aws-samples/sagemaker-studio-foundation-models/main/lab-03-rag/AWSGuides/AmazonSageMakerDeveloperGuide.pdf wget --no-check-certificate https://raw.githubusercontent.com/aws-samples/sagemaker-studio-foundation-models/main/lab-03-rag/AWSGuides/EC2DeveloperGuide.pdf wget --no-check-certificate https://raw.githubusercontent.com/aws-samples/sagemaker-studio-foundation-models/main/lab-03-rag/AWSGuides/S3DeveloperGuide.pdf这会将
Lab_0_Warm_Up_Deploy_EmbeddingModel_Llama2_on_Nvidia.ipynb笔记本检索到本地目录,并将三个 PDF 文件下载到本地AWSGuides文件夹。 -
打开
lab-00-setup/Lab_0_Warm_Up_Deploy_EmbeddingModel_Llama2_on_Nvidia.ipynb,保留Python 3 (ipykernel)内核,运行每个单元。警告
在 Llama 2 权限协议部分,确保在继续之前接受 Llama2 EULA。
笔记本在
ml.g5.2xlarge上部署了两个模型Llama 2和all-MiniLM-L6-v2 Models进行推理。部署模型和创建端点可能需要一些时间。
-
-
打开主笔记本
在中 JupyterLab,打开终端并运行以下命令。
cd .. wget --no-check-certificate https://raw.githubusercontent.com/aws-samples/sagemaker-studio-foundation-models/main/lab-03-rag/Lab_3_RAG_on_SageMaker_Studio_using_EMR.ipynb您应该会在的左侧面板中看到额外的
Lab_3_RAG_on_SageMaker_Studio_using_EMR.ipynb笔记本电脑 JupyterLab。 -
选择一个
PySpark内核打开
Lab_3_RAG_on_SageMaker_Studio_using_EMR.ipynb笔记本,确保正在使用SparkMagic PySpark内核。您可以在笔记本右上角切换内核。选择当前内核名称,打开内核选择模式,然后选择SparkMagic PySpark。 -
将笔记本连接到集群
-
在笔记本右上方,选择集群。此操作将打开一个模式窗口,列出您有权访问的所有正在运行的集群。
-
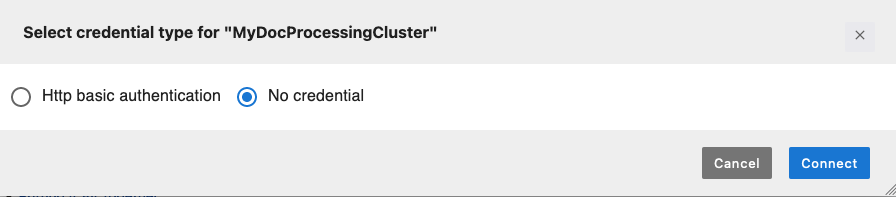
选择集群,然后选择连接。打开一个新的凭证类型选择模式窗口。
-
选择无凭证,然后选择连接。
-
笔记本单元自动填充并运行。笔记本单元会加载
sagemaker_studio_analytics_extension.magics扩展,提供连接 Amazon EMR 集群的功能。然后,它会使用%sm_analytics神奇命令启动与 Amazon EMR 集群和 Spark 应用程序的连接。注意
确保与 Amazon EMR 集群的连接字符串的身份验证类型设置为
None。下面示例中的--auth-type None值就说明了这一点。如有必要,您可以修改该字段。%load_ext sagemaker_studio_analytics_extension.magics %sm_analytics emr connect --verify-certificate False --cluster-idyour-cluster-id--auth-typeNone--language python -
成功建立连接后,您的连接单元输出消息应显示您的
SparkSession详细信息,包括您的集群 ID、YARN应用程序 ID 以及指向集群 ID 的链接 Spark 用于监控您的 UI Spark 工作。
-
您可以使用 Lab_3_RAG_on_SageMaker_Studio_using_EMR.ipynb 笔记本了。此示例笔记本运行分布式 PySpark 工作负载,用于使用 LangChain 和 OpenSearch构建 RAG 系统。
第 4 步:清理 AWS CloudFormation 堆栈
完成后,确保终止两个端点并删除 AWS CloudFormation 栈,以防继续收费。删除堆栈会清除堆栈供应的所有资源。
在使用完 AWS CloudFormation 堆栈后将其删除
-
进入 AWS CloudFormation 控制台:https://console.aws.amazon.com/
cloudformation -
选择要删除的堆栈。您可以按名称搜索,或在堆栈列表中查找。
-
单击删除按钮最终删除堆栈,然后再次单击删除确认将删除堆栈创建的所有资源。
等待堆栈删除完成。这可能需要几分钟时间。 AWS CloudFormation 会自动清理堆栈模板中定义的所有资源。
-
确认堆栈创建的所有资源都已删除。例如,检查是否有剩余的 Amazon EMR 集群。
要移除模型的 API 端点
-
前往 A SageMaker I 控制台:https://console.aws.amazon.com/sagemaker/
. -
在左侧导航窗格中,选择推理,然后选择端点。
-
选择端点
hf-allminil6v2-embedding-ep,然后在操作下拉列表中选择删除。对端点meta-llama2-7b-chat-tg-ep重复上述步骤。
