本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
在 Amazon A SageMaker I 中使用异构集群配置训练作业
此部分提供了有关如何使用由多种实例类型组成的异构集群运行训练作业的说明。
开始之前请注意以下事项。
-
所有实例组共享相同的 Docker 映像和训练脚本。因此,应修改训练脚本以相应地检测它所属的实例组和分叉执行。
-
异构集群功能与 SageMaker AI 本地模式不兼容。
-
异构集群训练作业的 Amazon CloudWatch 日志流未按实例组分组。您需要从日志中查明哪些节点属于哪个组。
选项 1:使用 SageMaker Python 开发工具包
按照有关如何使用 SageMaker Python SDK 为异构集群配置实例组的说明进行操作。
-
要为训练作业配置异构集群的实例组,请使用
sagemaker.instance_group.InstanceGroup类。您可以指定每个实例组的自定义名称、实例类型和每个实例组的实例数。有关更多信息,请参阅 sagemaker.instance_group。 InstanceGroup在 SageMaker AI Python SDK 文档中。 注意
有关可用实例类型以及您可以在异构集群中配置的最大实例组数量的更多信息,请参阅 InstanceGroupAPI 参考。
以下代码示例说明如何设置两个实例组,它们由两个名为
instance_group_1的ml.c5.18xlarge仅 CPU 实例和一个名为instance_group_2的ml.p3dn.24xlargeGPU 实例组成,如下图所示。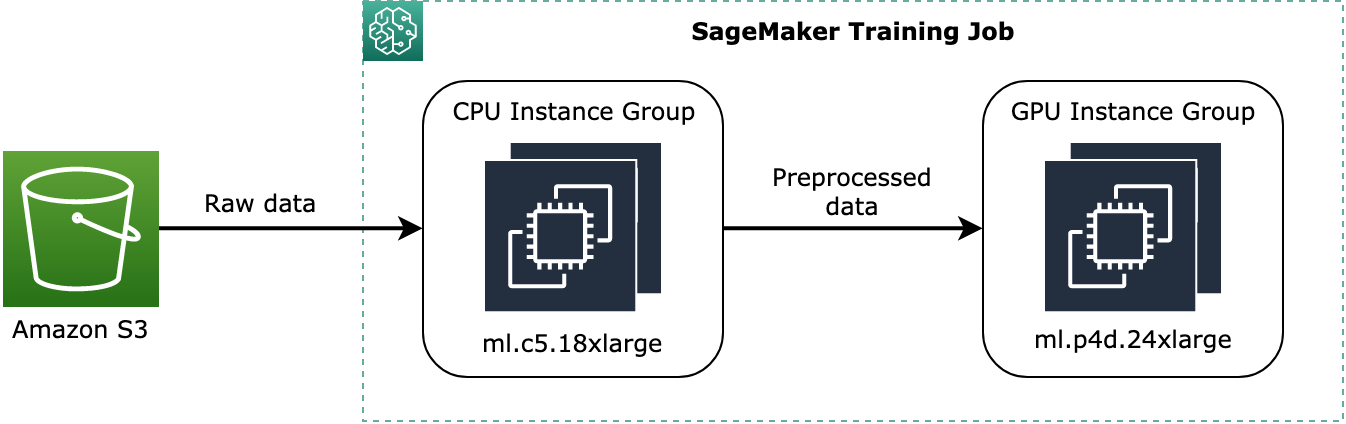
上图显示了一个概念性示例,说明如何将数据预处理等预训练过程分配给 CPU 实例组,并将预处理的数据流式传输到 GPU 实例组。
from sagemaker.instance_group import InstanceGroup instance_group_1 = InstanceGroup( "instance_group_1", "ml.c5.18xlarge",2) instance_group_2 = InstanceGroup( "instance_group_2", "ml.p3dn.24xlarge",1) -
使用实例组对象,设置训练输入通道,并通过 sagemaker.inputs 的
instance_group_names参数将实例组分配给通道。 TrainingInput班级。 instance_group_names参数接受实例组名称的字符串列表。以下示例说明如何设置两个训练输入通道并分配在上一步的示例中创建的实例组。您还可以为实例组指定
s3_data参数的 Amazon S3 存储桶路径,处理数据以供使用。from sagemaker.inputs import TrainingInput training_input_channel_1 = TrainingInput( s3_data_type='S3Prefix', # Available Options: S3Prefix | ManifestFile | AugmentedManifestFile s3_data='s3://your-training-data-storage/folder1', distribution='FullyReplicated', # Available Options: FullyReplicated | ShardedByS3Key input_mode='File', # Available Options: File | Pipe | FastFile instance_groups=["instance_group_1"] ) training_input_channel_2 = TrainingInput( s3_data_type='S3Prefix', s3_data='s3://your-training-data-storage/folder2', distribution='FullyReplicated', input_mode='File', instance_groups=["instance_group_2"] )有关
TrainingInput的参数的更多信息,请参阅以下链接。-
sagemaker.inputs。
TrainingInputSageMaker Python 软件开发工具包文档中的类 -
A DataSource I API 参考中的 S3 AP SageMaker I
-
-
使用
instance_groups参数配置 A SageMaker I 估算器,如以下代码示例所示。instance_groups参数接受InstanceGroup对象列表。注意
异构集群功能可通过 SageMaker AI PyTorch
和TensorFlow 框架估算器类获得。支持的框架是 PyTorch v1.10 或更高版本以及 TensorFlow v2.6 或更高版本。要查找可用框架容器、框架版本和 Python 版本的完整列表,请参阅 AWS 深度学习容器 GitHub 存储库中的 SageMaker AI 框架 容器。 注意
instance_type和的instance_count参数对和 SageMaker AI 估计器类的instance_groups参数是相互排斥的。对于同构集群训练,请使用instance_type和instance_count参数对。对于异构集群训练,请使用instance_groups。注意
要查找可用框架容器、框架版本和 Python 版本的完整列表,请参阅 AWS 深度学习容器 GitHub 存储库中的 SageMaker AI 框架
容器。 -
使用配置了实例组的训练输入通道配置
estimator.fit方法,然后启动训练作业。estimator.fit( inputs={ 'training':training_input_channel_1, 'dummy-input-channel':training_input_channel_2} )
选项 2:使用低级 SageMaker APIs
如果您使用 AWS Command Line Interface 或 AWS SDK for Python (Boto3) 并希望使用低级别 SageMaker APIs 来提交异构集群的训练作业请求,请参阅以下 API 参考。
