本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
SageMaker 智能筛选的工作原理
SageMaker 智能筛选的目标是在训练过程中筛选您的训练数据,并且只向模型提供信息更丰富的样本。在使用进行典型训练期间 PyTorch,数据会以迭代方式分批发送到训练循环和加速器设备(例如 GPUs 或 Trainium 芯片)。PyTorchDataLoader
下图概述了 SageMaker 智能筛选算法是如何设计的。
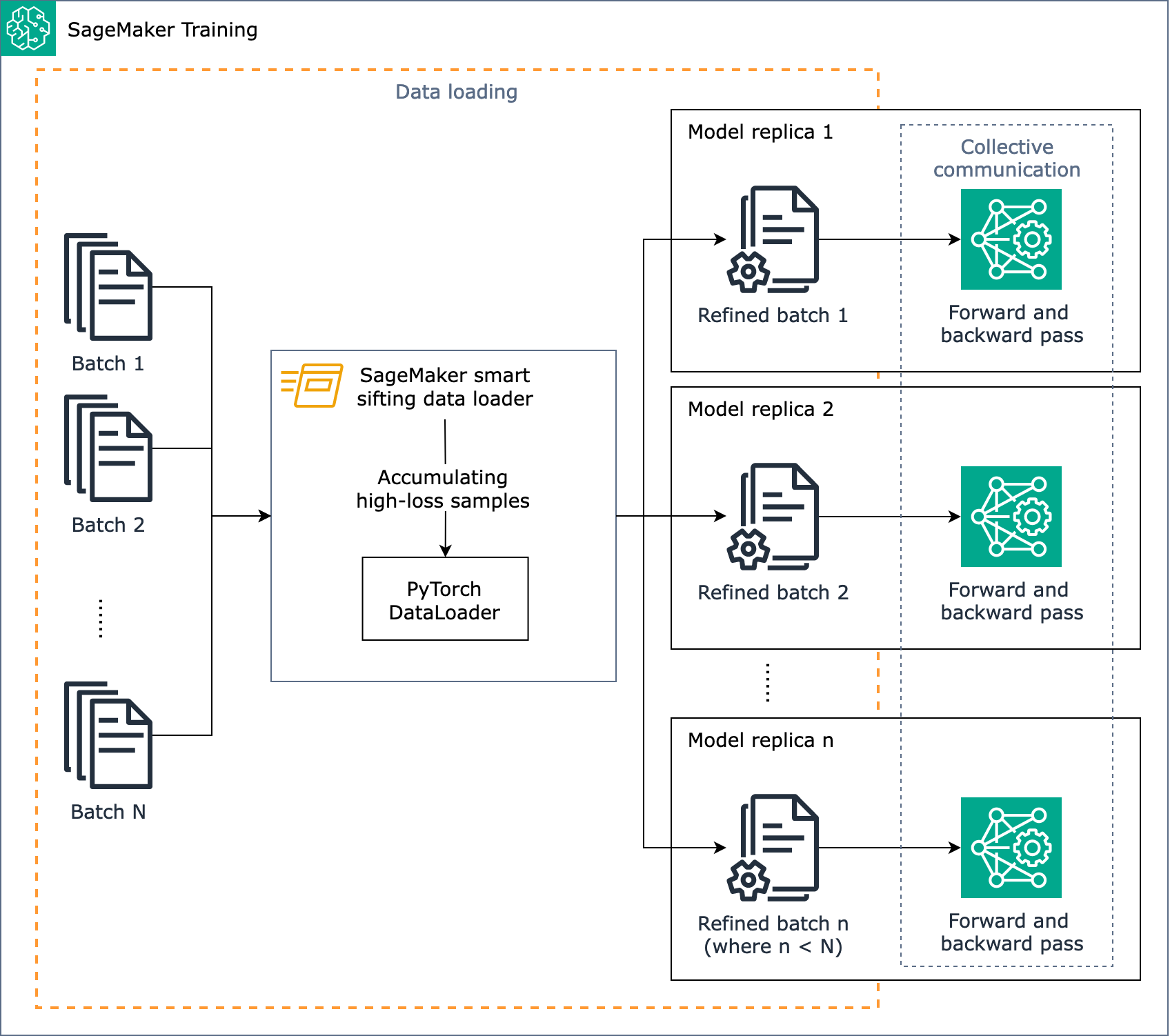
简而言之, SageMaker 智能筛选在训练期间会随着数据加载而运行。 SageMaker 智能筛选算法对批次进行损失计算,并在每次迭代向前和向后传递之前筛选出未改善的数据。然后,改进后的批次数据将用于前向和后向传递。
注意
在 SageMaker AI 上智能筛选数据可使用额外的正向传球来分析和筛选训练数据。反过来,由于从训练作业中排除影响力较小的数据,因此后向传递的次数也减少了。因此,使用智能筛选时,后向通过时间长或成本高的模型能获得最大的效率提升。同时,如果您的模型前向传递的时间比后向传递的时间长,开销可能会增加总的训练时间。要测量每次传递所花费的时间,您可以运行试点训练作业并收集记录进程时间的日志。还可以考虑使用提供性能分析工具和用户界面应用程序的 P SageMaker rofiler。要了解更多信息,请参阅 Amazon P SageMaker rofiler。
SageMaker 智能筛选适用于具有经典分布式数据并行性的 PyTorch基于训练作业,它可以在每个 GPU 工作器上生成模型副本并执行。AllReduce它可与 PyTorch DDP 和 SageMaker AI 分布式数据并行库配合使用。
