本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
创建自定义语言模型
在创建自定义语言模型之前,您必须:
-
准备数据。数据必须以纯文本格式保存,不能包含任何特殊字符。
-
将您的数据上传到Amazon S3存储桶中。建议为训练和调整数据创建单独的文件夹。
-
确保Amazon Transcribe有权访问您的Amazon S3存储桶。您必须指定具有访问权限的IAM角色才能使用您的数据。
准备数据
您可以将所有数据编译到一个文件中,也可以将其保存为多个文件。请注意,如果您选择包含调整数据,则必须将其与训练数据保存在单独的文件中。
您使用多少文本文件作为训练或调整数据都无关紧要。上传一个包含 100,000 个字的文件与上传 10 个包含 10,000 个字的文件产生的结果相同。以最方便的方式准备文本数据。
确保您的所有数据文件符合以下标准:
-
它们都与你要创建的模型使用相同的语言。例如,如果您想创建一个用美国英语 (
en-US) 转录音频的自定义语言模型,则所有文本数据都必须是美国英语。 -
它们采用纯文本格式,采用 UTF-8 编码。
-
它们不包含任何特殊字符或格式,例如 HTML 标签。
-
它们相当于训练数据的最大总大小为 2 GB,调整数据的最大总大小为 200 MB。
如果未满足其中任何条件,您的模型将失败。
上传您的数据
在上传数据之前,请为训练数据创建一个新文件夹。如果使用调整数据,请创建另一个单独的文件夹。
您的存储桶的 URI 可能如下所示:
-
s3://DOC-EXAMPLE-BUCKET/my-model-training-data/ -
s3://DOC-EXAMPLE-BUCKET/my-model-tuning-data/
将您的训练和调整数据上传到相应的存储分区中。
您可以稍后向这些存储桶添加更多数据。但是,如果您这样做,则需要使用新数据重新创建模型。无法使用新数据更新现有模型。
允许访问您的数据
要创建自定义语言模型,必须指定有权访问您的Amazon S3存储桶的IAM角色。如果您还没有有权访问放置训练数据的Amazon S3存储桶的角色,则必须创建一个。您创建角色后,您可以附加策略以授予该角色权限的策略来授予该角色权限。不要将策略附加到用户。
有关示例策略,请参阅 Amazon Transcribe 基于身份的策略示例。
要了解如何创建新IAM身份,请参阅IAM身份(用户、用户组和角色)。
要了解有关策略的更多信息,请参阅:
创建您的自定义语言模型
创建自定义语言模型时,必须选择基础模型。有两个基本模型选项:
-
NarrowBand:将此选项用于采样率低于 16,000 Hz 的音频。此模型类型通常用于以 8,000 Hz 录制的电话通话。 -
WideBand:将此选项用于采样率大于或等于 16,000 Hz 的音频。
您可以使用AWS Management Console、AWS CLI或 AWS SDK 创建自定义语言模型。参见以下示例:
-
在导航窗格中,选择 Cstom 语言模型)。这将打开自定义语言模型页面,您可以在其中查看现有的自定义语言模型或训练新的自定义语言模型。
-
要训练新模型,请选择训练模型。
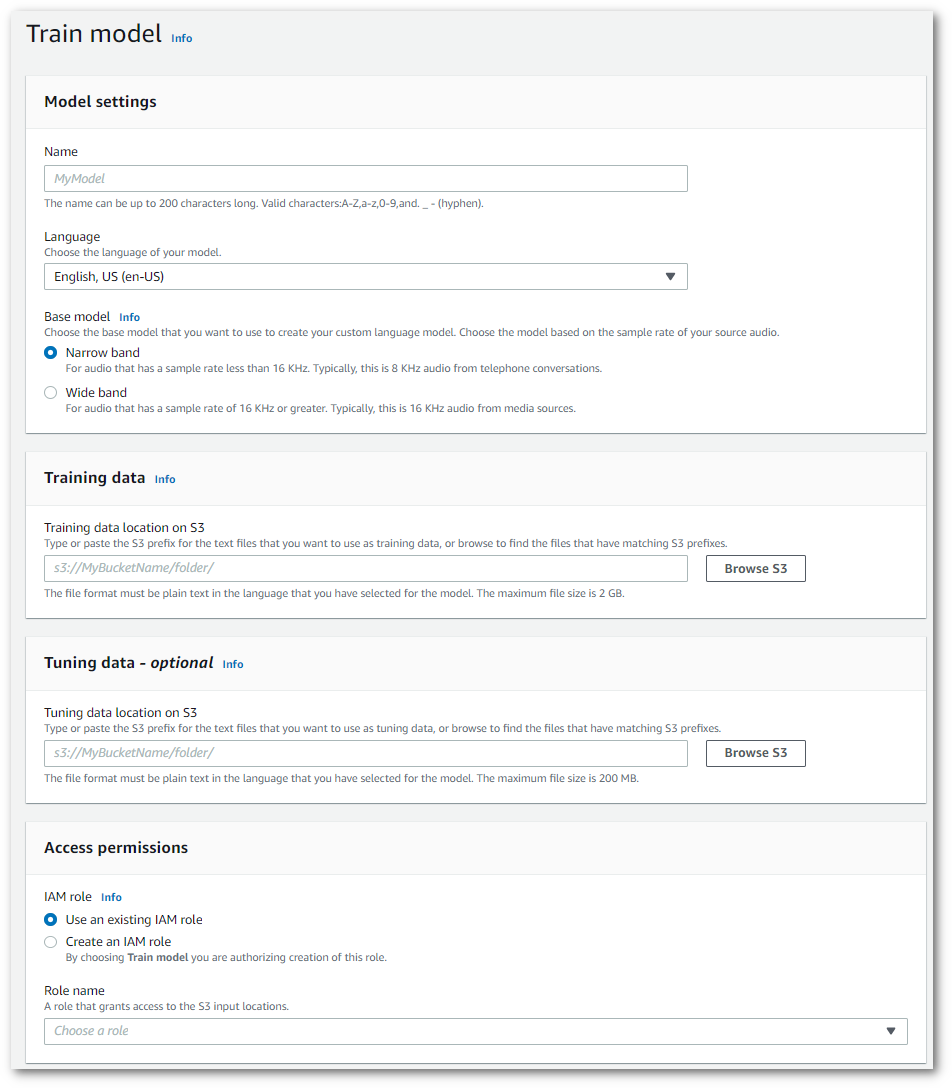
这将带您进入火车模型页面。添加名称,指定语言,然后为模型选择所需的基本模型。然后,添加训练路径,也可以添加调整数据。您必须包含有权访问您的数据的IAM角色。
-
完成所有字段后,选择页面底部的 T rain model。
此示例使用create-language-modelCreateLanguageModel 和 LanguageModel。
aws transcribe create-language-model \ --base-model-nameNarrowBand\ --model-namemy-first-language-model\ --input-data-config S3Uri=s3://DOC-EXAMPLE-BUCKET/my-clm-training-data/,TuningDataS3Uri=s3://DOC-EXAMPLE-BUCKET/my-clm-tuning-data/,DataAccessRoleArn=arn:aws:iam::111122223333:role/ExampleRole\ --language-codeen-US
这是使用create-language-model
aws transcribe create-language-model \ --cli-input-json file://filepath/my-first-language-model.json
my-first-language-model.json 文件包含以下请求正文。
{ "BaseModelName": "NarrowBand", "ModelName": "my-first-language-model", "InputDataConfig": { "S3Uri": "s3://DOC-EXAMPLE-BUCKET/my-clm-training-data/", "TuningDataS3Uri"="s3://DOC-EXAMPLE-BUCKET/my-clm-tuning-data/", "DataAccessRoleArn": "arn:aws:iam::111122223333:role/ExampleRole" }, "LanguageCode": "en-US" }
此示例使用使用 create_l AWS SDK for Python (Boto3) anguag e_model 方法创建CreateLanguageModel 和 LanguageModel。
有关使用 AWS SDK 的其他示例,包括特定功能、场景和跨服务示例,请参阅本章。使用 Amazon Transcribe 的代码示例 AWS SDKs
from __future__ import print_function import time import boto3 transcribe = boto3.client('transcribe', 'us-west-2') model_name = 'my-first-language-model', transcribe.create_language_model( LanguageCode = 'en-US', BaseModelName = 'NarrowBand', ModelName = model_name, InputDataConfig = { 'S3Uri':'s3://DOC-EXAMPLE-BUCKET/my-clm-training-data/', 'TuningDataS3Uri':'s3://DOC-EXAMPLE-BUCKET/my-clm-tuning-data/', 'DataAccessRoleArn':'arn:aws:iam::111122223333:role/ExampleRole' } ) while True: status = transcribe.get_language_model(ModelName = model_name) if status['LanguageModel']['ModelStatus'] in ['COMPLETED', 'FAILED']: break print("Not ready yet...") time.sleep(5) print(status)
更新您的自定义语言模型
Amazon Transcribe不断更新可用于自定义语言模型的基本模型。为了从这些更新中受益,我们建议每 6 到 12 个月训练一次新的自定义语言模型。
要查看您的自定义语言模型是否使用最新的基础模型,DescribeLanguageModel请使用AWS CLI或 S AWS DK 运行请求,然后在响应中找到相应UpgradeAvailability字段。
如果UpgradeAvailability是true,则您的模型未运行基本模型的最新版本。要在自定义语言模型中使用最新的基础模型,必须创建新的自定义语言模型。自定义语言模型无法升级。
