本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
批量转录作业的语言识别
使用批量语言识别来自动识别媒体文件中的一种或多种语言。
如果您的媒体仅包含一种语言,则可以启用单语言识别,该功能可以识别媒体文件中使用的主导语言,并仅使用该语言创建转录。
如果您的媒体包含多种语言,则可以启用多语言识别,该功能可以识别媒体文件中使用的所有语言,并使用识别出的每种语言创建转录。请注意,这将会生成多语言转录。您可以使用其他服务,例如 Amazon Translate,来翻译您的成绩单。
有关支持的语言和相关语言代码的完整列表,请参阅支持的语言表。
为获得最佳效果,请确保您的媒体文件包含至少 30 秒的语音。
有关 AWS Management Console、 AWS CLI和 AWS Python 开发工具包的用法示例,请参阅在批量转录中使用语言识别。
识别多语言音频中的语言
多语言识别专为多语言媒体文件而设计,可为您提供反映媒体中使用的所有支持的语言的转录。这就表示,如果发言者在对话中变换语言,或者如果每个参与者说的是不同的语言,则您的转录输出会正确检测并转录每种语言。例如,如果您的媒体包含双语发言者,其交替使用美国英语 (en-US) 和印地语 (hi-IN),则多语言识别可以识别说出的美国英语并转录为 en-US,然后将说出的印地语转录为 hi-IN。
这不同于单语言识别,后者只使用一种主导语言来创建转录。在这种情况下,主导语言以外的任何语言都会被错误地转录。
注意
多语言识别目前不支持编辑和自定义语言模型。
注意
目前支持以下语言进行多语言识别:en-ab、en-au、en-GB、en-ie、en-in、en-nz、en-US、en-za、es-es、es-us、fr-ca、fr-fr、zh-tw、pt-br、pt-pt、de-pt、de-ch、de-de、a-za、ar-ae、da-dk、he-il、hi-in、id-id,fa-ir、it-it、ja-jp、ko-kr、ms-my、nl-nl、ru-ru、ta-in、te-in、te-in、th-th、tr-tr
多语言转录提供检测到的语言的摘要以及每种语言在媒体中使用的总时间。示例如下:
"results": { "transcripts": [ { "transcript": "welcome to Amazon transcribe. ये तो उदाहरण हैं क्या कैसे कर सकते हैं ।一つのファイルに複数の言語を書き写す" } ],..."language_codes": [ { "language_code": "en-US", "duration_in_seconds": 2.45 }, { "language_code": "hi-IN", "duration_in_seconds": 5.325 }, { "language_code": "ja-JP", "duration_in_seconds": 4.15 } ] }
提高语言识别的准确性
通过语言识别,您可以选择包含您认为媒体中可能存在的语言列表。包括语言选项 (LanguageOptions) 限制仅使用您在 Amazon Transcribe 将音频与正确语言匹配时指定的语言,这可以加快语言识别速度并提高与分配正确语言方言相关的准确性。
如果选择包含语言代码,则必须包含至少两个语言代码。您可以包含的语言代码数量没有限制,但为了获得最佳效率和准确性,我们建议使用两到五个语言代码。
注意
如果您在请求中包含语言代码,而您提供的语言代码均不与您的音频中标识的一个或多个语言相匹配,则请从您指定的语言代码 Amazon Transcribe 中选择最接近的语言匹配项。然后,它会生成该语言的转录。例如,如果您的媒体 Amazon Transcribe 使用的是美国英语 (en-US),并且您提供的语言代码zh-CNfr-FRde-DE、和, Amazon Transcribe 很可能会将您的媒体与德语 (de-DE) 匹配并生成德语转录。语言代码和说出的语言不匹配可能会导致转录不准确,因此我们建议在添加语言代码时要小心谨慎。
将语言识别与其它 Amazon Transcribe 特征结合使用
您可以将批量语言识别与任何其它 Amazon Transcribe 特征结合使用。如果将语言识别与其它特征结合使用,则只能使用这些特征支持的语言。例如,如果在内容编辑中使用语言识别,则只能使用美国英语 (en-US) 或美国西班牙语 (es-US),因为这是唯一可用于编辑的语言。有关更多信息,请参阅支持的语言和特定语言的特征。
重要
如果您在启用了内容编辑功能的情况下使用自动语言识别,并且您的音频包含美国英语 (en-US) 或美国西班牙语 (es-US) 以外的语言,则您的笔录中只有美国英语或美国西班牙语内容会被编辑。其它语言则无法编辑,也不会出现警告或作业失败。
自定义语言模型、自定义词汇表和自定义词汇表过滤器
如果要在语言识别请求中添加一个或多个自定义语言模型、自定义词汇表或自定义词汇表过滤器,则必须包含 LanguageIdSettings 参数。然后,您可以使用相应的自定义语言模型、自定义词汇表和自定义词汇表过滤器来指定语言代码。请注意,多语言识别不支持自定义语言模型。
为了确保识别出正确的语言方言,建议您在使用 LanguageIdSettings 时包含 LanguageOptions。例如,如果您指定了en-US自定义词汇表,但 Amazon Transcribe 确定媒体中使用的语言是en-AU,则您的自定义词汇不会应用于您的转录。如果您包含 LanguageOptions 并指定 en-US 为唯一的英语方言,则您的自定义词汇表会应用于您的转录。
有关请求中的 LanguageIdSettings 的示例,请参阅在批量转录中使用语言识别部分 AWS CLI 和 AWS SDK 下拉面板中的选项 2。
在批量转录中使用语言识别
您可以通过 AWS Management Console、AWS CLI 或AWS SDK 在批量转录作业中使用自动语言识别;有关示例,请参阅以下内容:
-
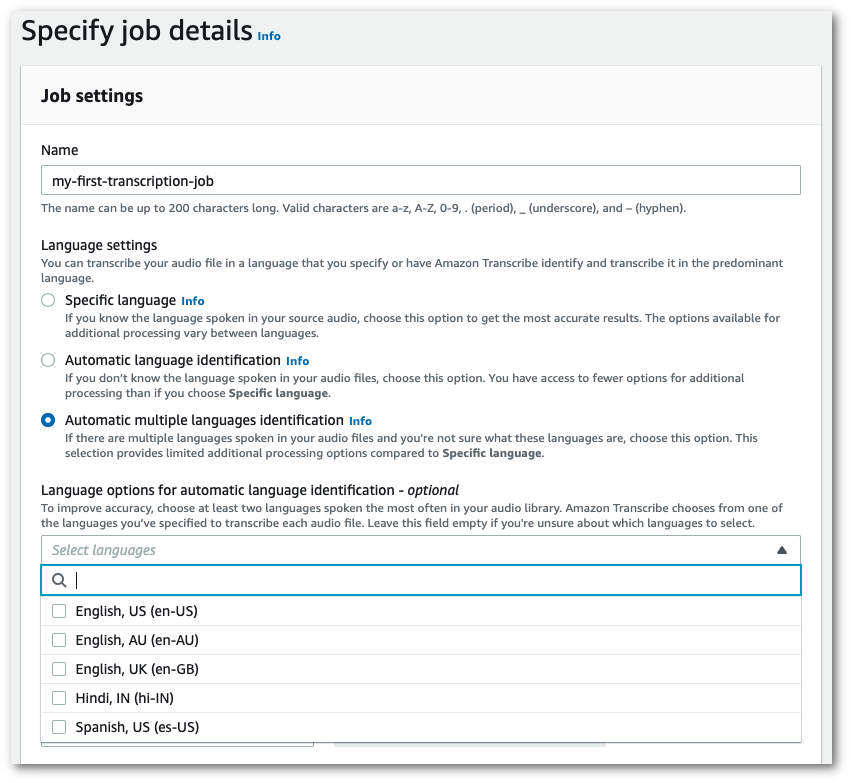
在导航窗格中,选择转录作业,然后选择创建作业(右上角)。这将打开指定作业详细信息页面。
-
在作业设置面板中,找到语言设置部分,然后选择自动语言识别或自动多语言识别。
如果您知道音频文件中存在哪些语言,则可以选择多种语言选项(从选择语言下拉框中)。提供语言选项可以提高准确性,但不会要求这么做。
-
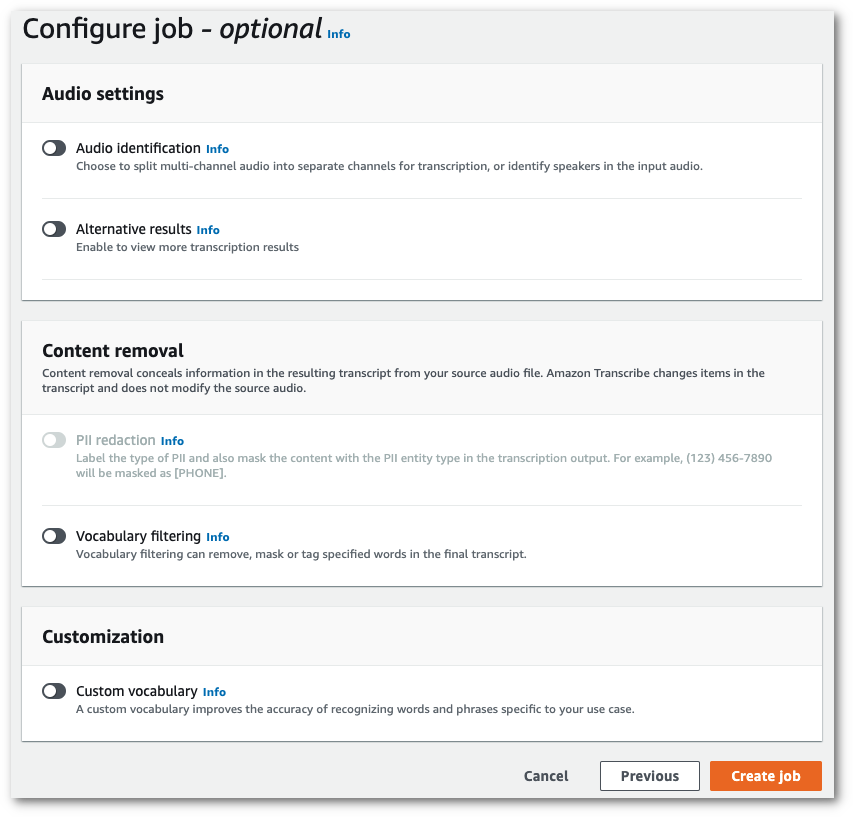
在指定作业详细信息页面上填写要包含的任何其它字段,然后选择下一步。此时您将会看到配置作业 - 可选页面。
-
选择创建作业以运行您的转录作业。
此示例使用start-transcription-jobIdentifyLanguage参数。有关更多信息,请参阅 StartTranscriptionJob 和 LanguageIdSettings。
选项 1:不使用 language-id-settings 参数。如果您未在请求中包含自定义语言模型、自定义词汇表或自定义词汇表过滤器,请使用此选项。虽然 language-options 为可选项,我们还是建议使用该选项。
aws transcribe start-transcription-job \ --regionus-west-2\ --transcription-job-namemy-first-transcription-job\ --media MediaFileUri=s3://DOC-EXAMPLE-BUCKET/my-input-files/my-media-file.flac\ --output-bucket-nameDOC-EXAMPLE-BUCKET\ --output-keymy-output-files/ \ --identify-language \ (or --identify-multiple-languages) \ --language-options "en-US" "hi-IN"
选项 2:使用 language-id-settings 参数。如果您在请求中包含了自定义语言模型、自定义词汇表或自定义词汇表过滤器,请使用此选项。
aws transcribe start-transcription-job \ --regionus-west-2\ --transcription-job-namemy-first-transcription-job\ --media MediaFileUri=s3://DOC-EXAMPLE-BUCKET/my-input-files/my-media-file.flac\ --output-bucket-nameDOC-EXAMPLE-BUCKET\ --output-keymy-output-files/ \ --identify-language \ (or --identify-multiple-languages) --language-options "en-US" "hi-IN" \ --language-id-settingsen-US=VocabularyName=my-en-US-vocabulary,en-US=VocabularyFilterName=my-en-US-vocabulary-filter,en-US=LanguageModelName=my-en-US-language-model,hi-IN=VocabularyName=my-hi-IN-vocabulary,hi-IN=VocabularyFilterName=my-hi-IN-vocabulary-filter
以下是另一个使用start-transcription-job
aws transcribe start-transcription-job \ --regionus-west-2\ --cli-input-json file://filepath/my-first-language-id-job.json
my-first-language-id-job.json 文件包含以下请求正文。
选项 1:不使用 LanguageIdSettings 参数。如果您未在请求中包含自定义语言模型、自定义词汇表或自定义词汇表过滤器,请使用此选项。虽然 LanguageOptions 为可选项,我们还是建议使用该选项。
{ "TranscriptionJobName": "my-first-transcription-job", "Media": { "MediaFileUri": "s3://DOC-EXAMPLE-BUCKET/my-input-files/my-media-file.flac" }, "OutputBucketName": "DOC-EXAMPLE-BUCKET", "OutputKey": "my-output-files/", "IdentifyLanguage":true, (or "IdentifyMultipleLanguages":true), "LanguageOptions": [ "en-US", "hi-IN" ] }
选项 2:使用 LanguageIdSettings 参数。如果您在请求中包含了自定义语言模型、自定义词汇表或自定义词汇表过滤器,请使用此选项。
{ "TranscriptionJobName": "my-first-transcription-job", "Media": { "MediaFileUri": "s3://DOC-EXAMPLE-BUCKET/my-input-files/my-media-file.flac" }, "OutputBucketName": "DOC-EXAMPLE-BUCKET", "OutputKey": "my-output-files/", "IdentifyLanguage":true, (or "IdentifyMultipleLanguages":true) "LanguageOptions": [ "en-US", "hi-IN" ], "LanguageIdSettings": { "en-US" : { "LanguageModelName": "my-en-US-language-model", "VocabularyFilterName": "my-en-US-vocabulary-filter", "VocabularyName": "my-en-US-vocabulary" }, "hi-IN": { "VocabularyName": "my-hi-IN-vocabulary", "VocabularyFilterName": "my-hi-IN-vocabulary-filter" } } }
此示例使用 start_transcription_IdentifyLanguage参数来标识文件的语言。 AWS SDK for Python (Boto3) 有关更多信息,请参阅 StartTranscriptionJob 和 LanguageIdSettings。
有关使用 AWS 软件开发工具包的其他示例,包括特定功能、场景和跨服务示例,请参阅本章。使用 Amazon Transcribe 的代码示例 AWS SDKs
选项 1:不使用 LanguageIdSettings 参数。如果您未在请求中包含自定义语言模型、自定义词汇表或自定义词汇表过滤器,请使用此选项。虽然 LanguageOptions 为可选项,我们还是建议使用该选项。
from __future__ import print_function import time import boto3 transcribe = boto3.client('transcribe', 'us-west-2') job_name = "my-first-transcription-job" job_uri = "s3://DOC-EXAMPLE-BUCKET/my-input-files/my-media-file.flac" transcribe.start_transcription_job( TranscriptionJobName = job_name, Media = { 'MediaFileUri': job_uri }, OutputBucketName = 'DOC-EXAMPLE-BUCKET', OutputKey = 'my-output-files/', MediaFormat = 'flac', IdentifyLanguage =True, (or IdentifyMultipleLanguages =True), LanguageOptions = [ 'en-US', 'hi-IN' ] ) while True: status = transcribe.get_transcription_job(TranscriptionJobName = job_name) if status['TranscriptionJob']['TranscriptionJobStatus'] in ['COMPLETED', 'FAILED']: break print("Not ready yet...") time.sleep(5) print(status)
选项 2:使用 LanguageIdSettings 参数。如果您在请求中包含了自定义语言模型、自定义词汇表或自定义词汇表过滤器,请使用此选项。
from __future__ import print_function import time import boto3 transcribe = boto3.client('transcribe') job_name = "my-first-transcription-job" job_uri = "s3://DOC-EXAMPLE-BUCKET/my-input-files/my-media-file.flac" transcribe.start_transcription_job( TranscriptionJobName = job_name, Media = { 'MediaFileUri': job_uri }, OutputBucketName = 'DOC-EXAMPLE-BUCKET', OutputKey = 'my-output-files/', MediaFormat='flac', IdentifyLanguage=True, (or IdentifyMultipleLanguages=True) LanguageOptions = [ 'en-US', 'hi-IN' ], LanguageIdSettings={ 'en-US': { 'VocabularyName': 'my-en-US-vocabulary', 'VocabularyFilterName': 'my-en-US-vocabulary-filter', 'LanguageModelName': 'my-en-US-language-model' }, 'hi-IN': { 'VocabularyName': 'my-hi-IN-vocabulary', 'VocabularyFilterName': 'my-hi-IN-vocabulary-filter' } } ) while True: status = transcribe.get_transcription_job(TranscriptionJobName = job_name) if status['TranscriptionJob']['TranscriptionJobStatus'] in ['COMPLETED', 'FAILED']: break print("Not ready yet...") time.sleep(5) print(status)
