本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
创建词汇过滤器
有两个选项可用于创建自定义词汇表:
-
使用 UTF-8 编码将行分隔的单词列表保存为纯文本文件。
您可以将此方法与AWS Management ConsoleAWS CLI、或AWS SDK 一起使用。
如果使用AWS Management Console,则可以为自定义词汇文件提供本地路径或Amazon S3 URI。
如果使用AWS CLI或AWS SDK,则必须将自定义词汇文件上传到Amazon S3存储桶并在请求中包含Amazon S3 URI。
-
直接在您的 API 请求中包含以逗号分隔的单词列表。
-
您可以使用此方法将此方法与使用
Words参数的AWS CLI或AWS SDK 一起使用。
-
有关每种方法的示例,请参阅创建自定义词汇过滤器
创建自定义词汇过滤器时需要注意的事项:
-
单词不区分大小写。例如,“诅咒” 和 “诅咒” 的待遇相同。
-
仅筛选完全匹配的单词。例如,如果您的过滤器包含 “发誓”,但您的媒体包含 “发誓” 或 “发誓” 一词,则不会对其进行过滤。只有 “发誓” 的实例才会被过滤。因此,您必须包括要过滤的单词的所有变体。
-
过滤器不适用于换句话中包含的单词。例如,如果自定义词汇过滤器包含 “海军陆战队” 而不包含 “潜艇”,则笔录中的 “潜艇” 不会被更改。
-
每个条目只能包含一个单词(无空格)。
-
如果您将自定义词汇过滤器另存为文本文件,则它必须采用 UTF-8 编码的纯文本格式。
-
每个过滤器最多可以有 100 个自定义词汇过滤器AWS 账户,每个过滤器的大小可达 50 Kb。
-
您只能使用您的语言支持的字符。有关详细信息,请参阅您的语言的字符集。
创建自定义词汇过滤器
要处理自定义词汇过滤器以供使用Amazon Transcribe,请参阅以下示例:
在继续之前,请将您的自定义词汇过滤器另存为文本 (*.txt) 文件。您可以选择将文件上传到Amazon S3存储桶。
-
在导航窗格中,选择 Vocabulary filtering (词汇筛选)。这将打开词汇过滤器页面,您可以在其中查看现有的自定义词汇过滤器或创建新的词汇过滤器。
-
选择 “创建词汇过滤器”。
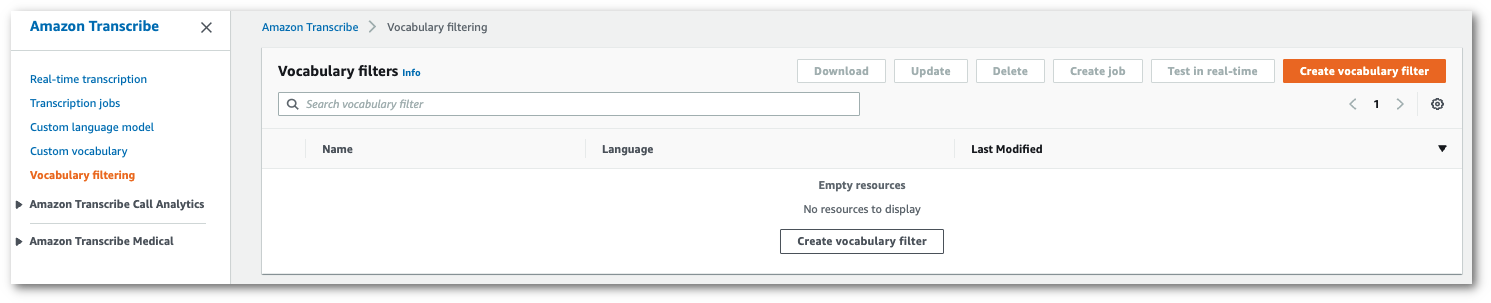
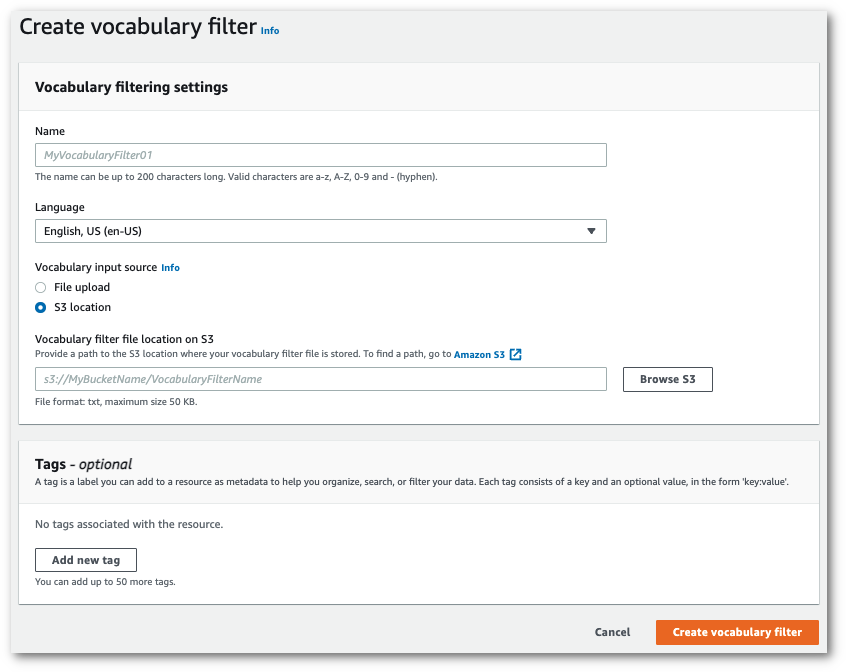
这将带您进入创建词汇过滤器页面。为新的自定义词汇过滤器输入名称。
在词汇输入源下选择文件上传或 S3 位置选项。然后指定您的自定义词汇文件的位置。
-
(可选)向您的自定义词汇过滤器添加标签。完成所有字段后,选择页面底部的创建词汇过滤器。如果在处理文件时没有错误,这会将你带回词汇过滤器页面。
现在您的自定义词汇过滤器已准备好使用。
此示例使用create-vocabulary-filter命令将单词列表处理成可用的自定义词汇过滤器。有关更多信息,请参阅CreateVocabularyFilter:
选项 1:您可以使用words参数将单词列表包含在请求中。
aws transcribe create-vocabulary-filter \ --vocabulary-filter-namemy-first-vocabulary-filter\ --language-codeen-US\ --wordsprofane,offensive,Amazon,Transcribe
选项 2:您可以将单词列表保存为文本文件并将其上传到Amazon S3存储桶,然后使用vocabulary-filter-file-uri参数将文件的 URI 包含在您的请求中。
aws transcribe create-vocabulary-filter \ --vocabulary-filter-namemy-first-vocabulary-filter\ --language-codeen-US\ --vocabulary-filter-file-uri s3://DOC-EXAMPLE-BUCKET/my-vocabulary-filters/my-vocabulary-filter.txt
这是使用create-vocabulary-filter命令的另一个示例,以及一个创建自定义词汇过滤器的请求正文。
aws transcribe create-vocabulary-filter \ --cli-input-json file://filepath/my-first-vocab-filter.json
my-first-vocab-filter.json 文件包含以下请求正文。
选项 1:您可以使用Words参数将单词列表包含在请求中。
{ "VocabularyFilterName": "my-first-vocabulary-filter", "LanguageCode": "en-US", "Words": [ "profane","offensive","Amazon","Transcribe" ] }
选项 2:您可以将单词列表保存为文本文件并将其上传到Amazon S3存储桶,然后使用VocabularyFilterFileUri参数将文件的 URI 包含在您的请求中。
{ "VocabularyFilterName": "my-first-vocabulary-filter", "LanguageCode": "en-US", "VocabularyFilterFileUri": "s3://DOC-EXAMPLE-BUCKET/my-vocabulary-filters/my-vocabulary-filter.txt" }
注意
如果您在请求VocabularyFilterFileUri中包含,则无法使用Words;必须选择其中一个。
此示例使用 create_vocqual ary_filter 方法创建自定义词汇过滤器CreateVocabularyFilter:
有关使用AWS软件开发工具包的其他示例,包括特定功能、场景和跨服务示例,请参阅本使用 Amazon Transcribe 的代码示例 AWS SDKs章。
选项 1:您可以使用Words参数将单词列表包含在请求中。
from __future__ import print_function import time import boto3 transcribe = boto3.client('transcribe', 'us-west-2') vocab_name = "my-first-vocabulary-filter" response = transcribe.create_vocabulary_filter( LanguageCode = 'en-US', VocabularyFilterName = vocab_name, Words = [ 'profane','offensive','Amazon','Transcribe' ] )
选项 2:您可以将单词列表保存为文本文件并将其上传到Amazon S3存储桶,然后使用VocabularyFilterFileUri参数将文件的 URI 包含在您的请求中。
from __future__ import print_function import time import boto3 transcribe = boto3.client('transcribe', 'us-west-2') vocab_name = "my-first-vocabulary-filter" response = transcribe.create_vocabulary_filter( LanguageCode = 'en-US', VocabularyFilterName = vocab_name, VocabularyFilterFileUri = 's3://DOC-EXAMPLE-BUCKET/my-vocabulary-filters/my-vocabulary-filter.txt' )
注意
如果您在请求VocabularyFilterFileUri中包含,则无法使用Words;必须选择其中一个。
注意
如果您为自定义词汇筛选文件创建新的Amazon S3存储桶,请确保CreateVocabularyFilter发出请求的IAM角色有权访问此存储桶。如果该角色没有正确的权限,则您的请求将失败。您可以选择通过添加DataAccessRoleArn参数在请求中指定IAM角色。有关中的IAM角色和策略的更多信息Amazon Transcribe,请参阅Amazon Transcribe 基于身份的策略示例。
