本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
分布式数据管理
在传统应用程序中,所有组件通常共享一个数据库。相比之下,基于微服务的应用程序的每个组件都维护自己的数据,从而促进了独立性和去中心化。这种被称为分布式数据管理的方法带来了新的挑战。
其中一个挑战来自分布式系统中一致性和性能之间的权衡。接受数据更新中的轻微延迟(最终一致性)通常比坚持即时更新(即时一致性)更为实用。
有时,业务运营需要多个微服务才能协同工作。如果一个部件出现故障,则可能需要撤消一些已完成的任务。S aga模式通过协调一系列补偿措施来帮助管理这种情况。
为了帮助微服务保持同步,可以使用集中式数据存储。这家商店使用 AWS Lambda AWS Step Functions、和 Amazon 等工具进行管理 EventBridge,可以帮助清理和删除重复数据。
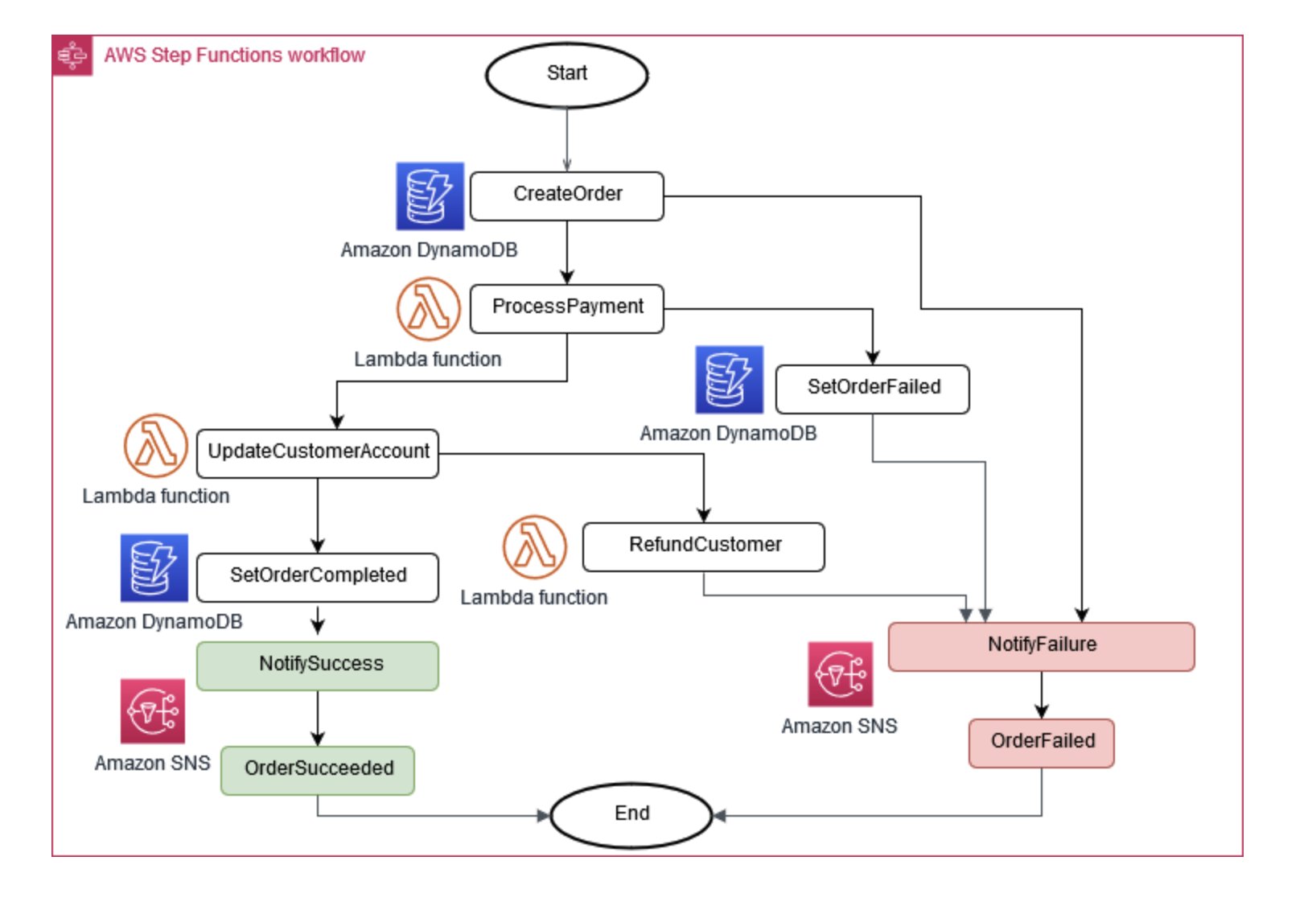
图 6:Saga 执行协调器
管理跨微服务变更的一种常见方法是事件来源。应用程序中的每一次更改都记录为事件,从而创建系统状态的时间表。这种方法不仅有助于调试和审计,还允许应用程序的不同部分对相同的事件做出反应。
事件来源通常 hand-in-hand使用命令查询责任分离 (CQRS) 模式,该模式将数据修改和数据查询分成不同的模块,以提高性能和安全性。
在上 AWS,您可以使用服务组合来实现这些模式。如图 7 所示,Amazon Kinesis Data Streams 可以用作您的中央事件存储,而 Amazon S3 可为所有事件记录提供持久存储。 AWS Lambda、Amazon DynamoDB 和 A API mazon Gateway 共同处理和处理这些事件。
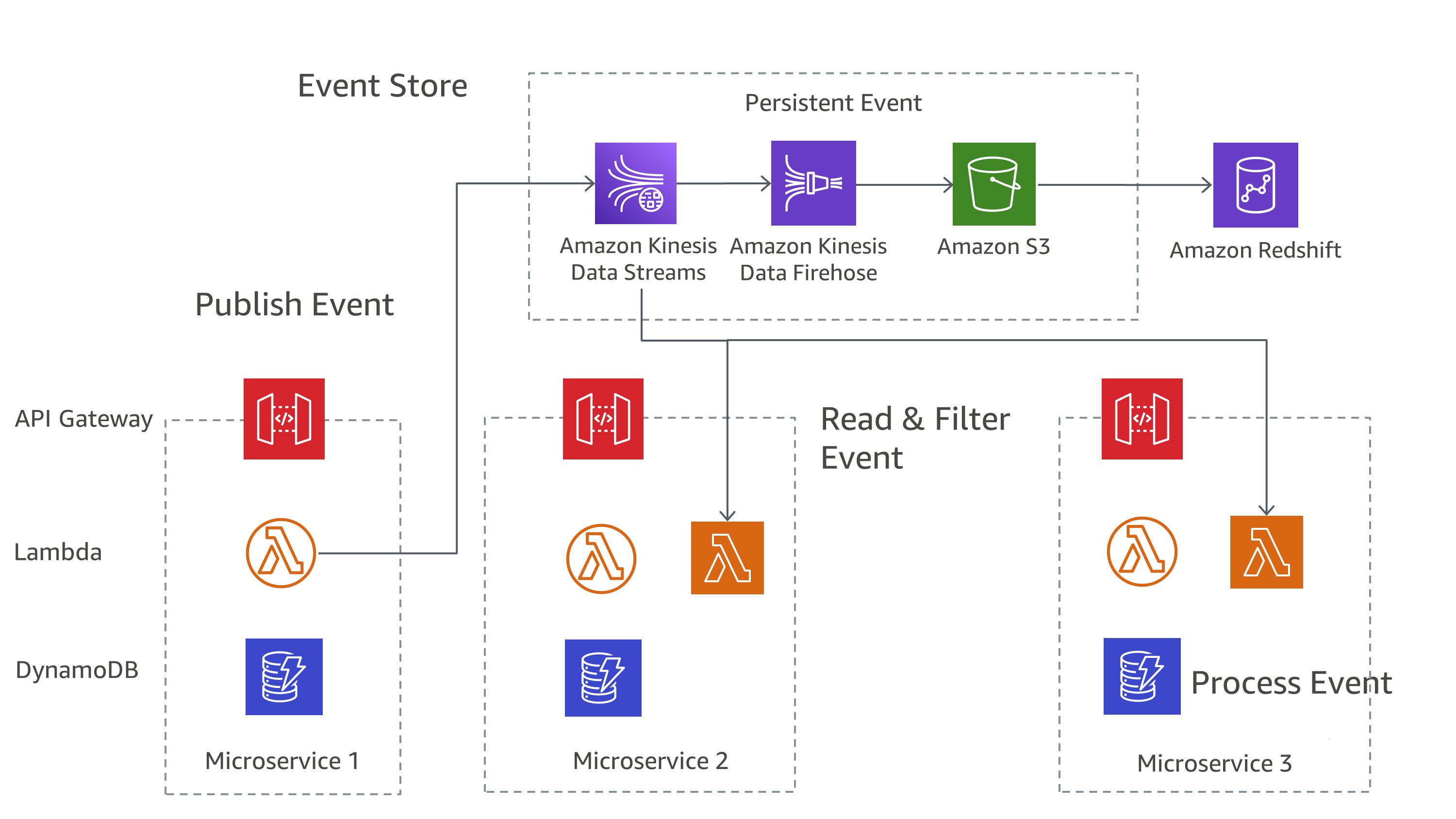
图 7:活动来源模式开启 AWS
请记住,在分布式系统中,由于重试,事件可能会被多次传送,因此设计应用程序来处理这个问题非常重要。
