本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
搭配 Valkey 和 Redis OSS 使用異地同步備份,將 ElastiCache 中的停機時間降至最低
有些執行個體 ElastiCache for Valkey 和 Redis OSS 可能需要取代主節點;這些包括特定類型的計劃維護,以及不太可能發生的主節點或可用區域故障。
此取代會導致叢集出現一些停機情況,但如果啟用異地同步備份,停機時間可降至最低。主節點的角色會自動容錯移轉到其中一個僅供讀取複本。不需要建立和佈建新的主節點,因為 ElastiCache 會透明地處理這個問題。此容錯移轉及複本提升可確保您能在提升完成時立即繼續寫入新的主要節點。
ElastiCache 也會傳播所提升複本的網域名稱服務 (DNS)。它會執行這項操作的原因在於,若您的應用程式正在寫入主要端點,您的應用程式中便不需要變更任何端點。如果您是從個別端點讀取,則請確保將提升至主要端點的複本讀取端點變更為新複本的端點。
如果是計劃的節點替換,這些替換因維護更新或自助式更新而啟動,請留意以下事項:
對於 Valkey 和 Redis OSS 叢集,計劃的節點替換會在叢集提供傳入寫入請求時完成。
對於在 5.0.6 或更新版本引擎上執行且已啟用異地同步備份的停用 Valkey 和 Redis OSS 叢集模式叢集,計劃的節點替換會在叢集提供傳入寫入請求時完成。
對於已啟用異地同步備份且在 4.0.10 或更早的引擎上執行的停用 Valkey 和 Redis OSS 叢集模式的叢集,您可能會注意到與 DNS 更新相關的短暫寫入中斷。此中斷最多可能需要幾秒鐘的時間。此程序的速度比重新建立及佈建新的主節點更快 (也就是沒有啟用異地同步備份時發生的程序)。
您可以使用 ElastiCache 管理主控台、 AWS CLI或 ElastiCache API 啟用異地同步備份。
注意
啟用耐用性的叢集:對於啟用耐用性的 Valkey 9.0+ 叢集,容錯移轉行為與下列案例不同。有了耐久性,所有遞交的資料都會保留在多可用區域交易日誌中。在容錯移轉期間,同步寫入可確保零資料遺失,而非同步寫入可能會遺失長達 10 秒的未遞交資料。失敗的節點會從交易日誌還原所有遞交的資料,而不需要主要節點的完整同步。如需詳細資訊,請參閱ElastiCache 中的耐用性。
在 Valkey 或 Redis OSS 叢集 (在 API 和 CLI 中,複寫群組) 上啟用 ElastiCache 異地同步備份可改善容錯能力。當您的叢集的讀取/寫入主要叢集因任何原因變得無法連線或失敗的情況下,這特別有用。只有在每個碎片中具有多個節點的 Valkey 和 Redis OSS 叢集才支援異地同步備份。
啟用多個可用區
您可以在使用 ElastiCache 主控台或 ElastiCache API 建立或修改叢集 (API 或 CLI AWS CLI、複寫群組) 時啟用異地同步備份。
您只能在至少有一個可用僅供讀取複本的 Valkey 或 Redis OSS (停用叢集模式) 叢集上啟用異地同步備份。沒有僅供讀取複本的叢集無法提供高度可用性或容錯能力。如需建立附帶複寫叢集的資訊,請參閱建立 Valkey 或 Redis OSS 複寫群組。如需將僅供讀取複本新增到附帶複寫叢集的資訊,請參閱新增 Valkey 或 Redis OSS 的僅供讀取複本 (停用叢集模式)。
啟用異地同步備份 (主控台)
您可以在建立新的 Valkey 或 Redis OSS 叢集或修改具有複寫的現有叢集時,使用 ElastiCache 主控台啟用異地同步備份。
根據預設,Valkey 或 Redis OSS (啟用叢集模式) 叢集上會啟用異地同步備份。
重要
只有當叢集的所有碎片中至少有一個複本的可用區域與主節點不同時,ElastiCache 才會自動啟用異地同步備份。
使用 ElastiCache 主控台建立叢集時啟用異地同步備份
如需此程序的詳細資訊,請參閱建立 Valkey (停用叢集模式) 叢集 (主控台)。請務必確保您有一或多個複本,並啟用多個可用區。
在現有叢集上啟用異地同步備份 (主控台)
如需此程序的詳細資訊,請參閱使用 ElastiCache AWS Management Console修改叢集。
啟用異地同步備份 (AWS CLI)
下列程式碼範例使用 AWS CLI 為複寫群組 啟用異地同步備份redis12。
重要
複寫群組 redis12 必須已存在,並且其中必須至少要有一個可用的僅供讀取複本。
針對 Linux、macOS 或 Unix:
aws elasticache modify-replication-group \ --replication-group-idredis12\ --automatic-failover-enabled \ --multi-az-enabled \ --apply-immediately
針對 Windows:
aws elasticache modify-replication-group ^ --replication-group-idredis12^ --automatic-failover-enabled ^ --multi-az-enabled ^ --apply-immediately
此命令的 JSON 輸出看起來會與以下內容相似。
{
"ReplicationGroup": {
"Status": "modifying",
"Description": "One shard, two nodes",
"NodeGroups": [
{
"Status": "modifying",
"NodeGroupMembers": [
{
"CurrentRole": "primary",
"PreferredAvailabilityZone": "us-west-2b",
"CacheNodeId": "0001",
"ReadEndpoint": {
"Port": 6379,
"Address": "redis12-001.v5r9dc.0001.usw2.cache.amazonaws.com"
},
"CacheClusterId": "redis12-001"
},
{
"CurrentRole": "replica",
"PreferredAvailabilityZone": "us-west-2a",
"CacheNodeId": "0001",
"ReadEndpoint": {
"Port": 6379,
"Address": "redis12-002.v5r9dc.0001.usw2.cache.amazonaws.com"
},
"CacheClusterId": "redis12-002"
}
],
"NodeGroupId": "0001",
"PrimaryEndpoint": {
"Port": 6379,
"Address": "redis12.v5r9dc.ng.0001.usw2.cache.amazonaws.com"
}
}
],
"ReplicationGroupId": "redis12",
"SnapshotRetentionLimit": 1,
"AutomaticFailover": "enabling",
"MultiAZ": "enabled",
"SnapshotWindow": "07:00-08:00",
"SnapshottingClusterId": "redis12-002",
"MemberClusters": [
"redis12-001",
"redis12-002"
],
"PendingModifiedValues": {}
}
}如需詳細資訊,請參閱 AWS CLI 命令參考中的下列主題:
-
AWS CLI 命令參考中的 modify-replication-group。
啟用異地同步備份 (ElastiCache API)
下列程式碼範例使用 ElastiCache API 為複寫群組 redis12 啟用異地同步備份。
注意
若要使用此範例,複寫群組 redis12 必須已存在,並且其中必須至少要有一個可用的僅供讀取複本。
https://elasticache.us-west-2.amazonaws.com/ ?Action=ModifyReplicationGroup &ApplyImmediately=true &AutoFailover=true &MultiAZEnabled=true &ReplicationGroupId=redis12 &Version=2015-02-02 &SignatureVersion=4 &SignatureMethod=HmacSHA256 &Timestamp=20140401T192317Z &X-Amz-Credential=<credential>
如需詳細資訊,請參閱 ElastiCache API 參考中的下列主題:
具有異地同步備份回應的故障案例
在引入異地同步備份之前,ElastiCache 是透過重新建立及重新佈建故障的節點,來偵測並取代叢集中故障的節點。如果啟用多個可用區,故障的主要節點會容錯移轉至複寫延遲最短的複本。選取的複本會自動提升為主要節點,這比建立並重新佈建新的主要節點更快。此程序通常只需要幾秒鐘,您便能再次寫入叢集。
啟用異地同步備份時,ElastiCache 會持續監控主節點的狀態。若主要節點故障,便會根據故障的類型執行以下其中一個動作。
只有主節點故障的故障案例
若只有主要節點故障,複寫延遲最短的僅供讀取複本便會提升至主要叢集。接著會在與故障的主要節點相同的可用區域中建立並佈建遭取代的僅供讀取複本。
只有主節點故障時,ElastiCache 異地同步備份會執行下列作業:
失敗的主要節點會離線。
複寫延隔最少的僅供讀取複本會提升為主要節點。
寫入通常可以在提升程序完成時繼續,這通常僅需要數秒鐘。若您的應用程式正在寫入主要端點,便不需要針對寫入或讀取變更端點。ElastiCache 會傳播提升複本的 DNS 名稱。
啟動及佈建替換用的僅供讀取複本。
替換用的僅供讀取複本會在失敗主要節點所在的可用區域內啟動,維持節點的分佈。
複本會與新的主要節點同步。
新複本可供使用之後,請注意下列效果:
-
主要端點 - 您不需要對應用程式進行任何變更,因為新主節點的 DNS 名稱會傳播到主要端點。
-
讀取端點 - 讀取者端點會自動更新,以指向新的複本節點。
如需尋找叢集端點的資訊,請參閱下列主題:
主節點和某些僅供讀取複本故障的故障案例
若主要節點及至少一個僅供讀取複本失敗時,複寫延隔最少的可用複本會提升至主要叢集。新的僅供讀取複本也會在失敗節點及提升為主要節點複本的相同可用區域內建立及佈建。
主節點和一部分僅供讀取複本故障時,ElastiCache 異地同步備份會執行下列作業:
失敗的主要節點和失敗的僅供讀取複本會離線。
複寫延隔最少的可用複本會提升為主要節點。
寫入通常可以在提升程序完成時繼續,這通常僅需要數秒鐘。若您的應用程式正在寫入主要端點,便不需要針對寫入變更端點。ElastiCache 會傳播提升複本的 DNS 名稱。
建立及佈建替換用的複本。
替換用的複本會在失敗節點所在的可用區域內建立,維持節點的分佈。
所有叢集都會和新的主要節點同步。
在新節點可用之後,請對應用程式進行以下變更:
-
主要端點 - 不要對應用程式做任何變更。新主要節點的 DNS 名稱會傳播到主要端點。
-
讀取端點 - 讀取端點會自動更新,以指向新的複本節點。
如需尋找複寫群組端點的資訊,請參閱下列主題:
整個叢集故障的故障案例
若所有項目都失敗,便會在原始節點的相同可用區域內重新建立及佈建所有節點。
在此案例中,叢集內的所有資料都會因為叢集內的每個節點都發生故障而遺失。這種情況相當罕見。
整個叢集故障時,ElastiCache 異地同步備份會執行下列作業:
失敗的主要節點和僅供讀取複本會離線。
建立及佈建替換用的主要節點。
建立及佈建替換用的複本。
替代項目會在失敗節點所在的可用區域內建立,維持節點的分佈。
因為整個叢集失敗,資料會遺失,並且所有新的節點都會從零開始。
因為每個替換用節點都會具備與欲取代節點相同的端點,因此您不需要在應用程式內對任何端點進行變更。
如需尋找複寫群組端點的資訊,請參閱下列主題:
我們建議您在不同可用區域內建立主要節點和僅供讀取複本,以提升您的容錯能力層級。
測試自動容錯移轉
啟用自動容錯移轉之後,您可以使用 ElastiCache 主控台、 AWS CLI和 ElastiCache API 來進行測試。
在測試時,請注意下列事項:
-
您可以使用此操作,在任何滾動的 24 小時期間內測試最多 15 個碎片 (在 ElastiCache API 和 中稱為節點群組 AWS CLI) 的自動容錯移轉。
-
若您在不同叢集 (在 API 和 CLI 中稱為複寫群組) 內的碎片上呼叫此操作,您可以同時進行呼叫。
-
在某些情況下,您可以在相同 Valkey 或 Redis OSS (啟用叢集模式) 複寫群組的不同碎片上多次呼叫此操作。在這種情況下,必須先完成第一個節點取代,才能夠執行後續呼叫。
-
若要判斷節點替換是否已完成,請使用 Amazon ElastiCache 主控台 AWS CLI、 或 ElastiCache API 檢查事件。尋找與自動容錯移轉相關的以下事件 (根據可能發生的順序列出):
-
複寫群組訊息:
Test Failover API called for node group <node-group-id> -
快取叢集訊息:
Failover from primary node <primary-node-id> to replica node <node-id> completed -
複寫群組訊息:
Failover from primary node <primary-node-id> to replica node <node-id> completed -
快取叢集訊息:
Recovering cache nodes <node-id> -
快取叢集訊息:
Finished recovery for cache nodes <node-id>
如需詳細資訊,請參閱下列內容:
-
ElastiCache 使用者指南中的「檢視 ElastiCache 事件」
-
ElastiCache API 參考中的 DescribeEvents
-
AWS CLI 命令參考中的 describe-events。
-
此 API 旨在測試您的應用程式在 ElastiCache 容錯移轉情況下的行為。並非設計成啟動容錯移轉以解決叢集問題的操作工具。此外,在某些情況下,例如大規模操作事件, AWS 可能會封鎖此 API。
使用 測試自動容錯移轉 AWS Management Console
使用下列程序,透過主控台測試自動容錯移轉。
測試自動容錯移轉
-
登入 AWS Management Console 並開啟位於 https://https://console.aws.amazon.com/elasticache/
的 ElastiCache 主控台。 -
在導覽窗格中,選擇 Valkey 或 Redis OSS。
-
從叢集清單中,選擇您要測試之叢集左側的方塊。此叢集至少需要有一個僅供讀取複本節點。
-
在 Details (詳細資訊) 區域中,確認此叢集已啟用異地同步備份。若叢集尚未啟用多個可用區,請選擇不同叢集,或是修改此叢集以啟用多個可用區。如需詳細資訊,請參閱使用 ElastiCache AWS Management Console。
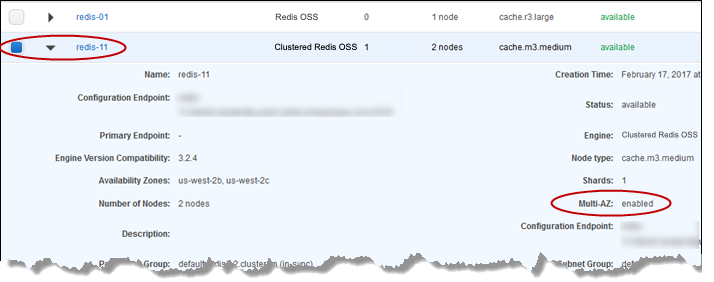
針對 Valkey 或 Redis OSS (停用叢集模式),選擇叢集的名稱。
針對 Valkey 或 Redis OSS (啟用叢集模式),請執行下列動作:
-
選擇叢集名稱。
-
在 Shards (碎片) 頁面上,針對您希望測試容錯移轉的碎片 (API 和 CLI 中稱為節點群組),選擇碎片名稱。
-
-
在 Nodes (節點) 頁面上,選擇 Failover Primary (容錯移轉主要節點)。
-
選擇 Continue (繼續) 來容錯移轉主要節點,或是 Cancel (取消) 來取消操作而不容錯移轉主要節點。
在容錯移轉程序期間,主控台會繼續將節點的狀態顯示為「可用」。若要追蹤容錯移轉測試的進度,請從主控台導覽窗格選擇 Events (事件)。在 Events (事件) 標籤上,觀察指出您容錯移轉已啟動的事件 (
Test Failover API called) 並完成 (Recovery completed)。
使用 測試自動容錯移轉 AWS CLI
您可以使用 AWS CLI 操作,在任何啟用異地同步備份的叢集上測試自動容錯移轉test-failover。
Parameters
-
--replication-group-id- 必要。要測試的複寫群組 (在主控台上為叢集)。 -
--node-group-id- 必要項目。您欲測試自動容錯移轉的節點群組名稱。在連續 24 小時期間內,您最多可以測試 15 個節點群組。
下列範例使用 AWS CLI 在 Valkey 或 Redis OSS (啟用叢集模式) 叢集 redis00-0003 中的節點群組上測試自動容錯移轉redis00。
範例測試自動容錯移轉
針對 Linux、macOS 或 Unix:
aws elasticache test-failover \ --replication-group-idredis00\ --node-group-idredis00-0003
針對 Windows:
aws elasticache test-failover ^ --replication-group-idredis00^ --node-group-idredis00-0003
上述命令的輸出會與以下內容相似。
{
"ReplicationGroup": {
"Status": "available",
"Description": "1 shard, 3 nodes (1 + 2 replicas)",
"NodeGroups": [
{
"Status": "available",
"NodeGroupMembers": [
{
"CurrentRole": "primary",
"PreferredAvailabilityZone": "us-west-2c",
"CacheNodeId": "0001",
"ReadEndpoint": {
"Port": 6379,
"Address": "redis1x3-001.7ekv3t.0001.usw2.cache.amazonaws.com"
},
"CacheClusterId": "redis1x3-001"
},
{
"CurrentRole": "replica",
"PreferredAvailabilityZone": "us-west-2a",
"CacheNodeId": "0001",
"ReadEndpoint": {
"Port": 6379,
"Address": "redis1x3-002.7ekv3t.0001.usw2.cache.amazonaws.com"
},
"CacheClusterId": "redis1x3-002"
},
{
"CurrentRole": "replica",
"PreferredAvailabilityZone": "us-west-2b",
"CacheNodeId": "0001",
"ReadEndpoint": {
"Port": 6379,
"Address": "redis1x3-003.7ekv3t.0001.usw2.cache.amazonaws.com"
},
"CacheClusterId": "redis1x3-003"
}
],
"NodeGroupId": "0001",
"PrimaryEndpoint": {
"Port": 6379,
"Address": "redis1x3.7ekv3t.ng.0001.usw2.cache.amazonaws.com"
}
}
],
"ClusterEnabled": false,
"ReplicationGroupId": "redis1x3",
"SnapshotRetentionLimit": 1,
"AutomaticFailover": "enabled",
"MultiAZ": "enabled",
"SnapshotWindow": "11:30-12:30",
"SnapshottingClusterId": "redis1x3-002",
"MemberClusters": [
"redis1x3-001",
"redis1x3-002",
"redis1x3-003"
],
"CacheNodeType": "cache.m3.medium",
"DataTiering": "disabled",
"PendingModifiedValues": {}
}
}若要追蹤容錯移轉的進度,請使用 AWS CLI describe-events操作。
如需詳細資訊,請參閱下列內容:
-
AWS CLI 命令參考中的 test-failover。
-
AWS CLI 命令參考中的 describe-events。
使用 ElastiCache API 測試自動容錯移轉
您可以在任何啟用異地同步備份的叢集上,使用 ElastiCache API 作業 TestFailover 來測試自動容錯移轉。
Parameters
-
ReplicationGroupId- 必要項目。要測試的複寫群組 (在主控台上為叢集)。 -
NodeGroupId- 必要項目。您欲測試自動容錯移轉的節點群組名稱。在連續 24 小時期間內,您最多可以測試 15 個節點群組。
以下範例會在複寫群組 (主控台上為叢集) redis00 中的節點群組 redis00-0003 上測試自動容錯移轉。
範例測試自動容錯移轉
https://elasticache.us-west-2.amazonaws.com/ ?Action=TestFailover &NodeGroupId=redis00-0003 &ReplicationGroupId=redis00 &Version=2015-02-02 &SignatureVersion=4 &SignatureMethod=HmacSHA256 &Timestamp=20140401T192317Z &X-Amz-Credential=<credential>
若要追蹤您容錯移轉的進度,請使用 ElastiCache DescribeEvents API 作業。
如需詳細資訊,請參閱下列內容:
-
ElastiCache API 參考中的 TestFailover
-
ElastiCache API 參考中的 DescribeEvents
多可用區的限制
請注意異地同步備份的下列限制:
-
Valkey 和 Redis OSS 2.8.6 版及更新版本支援異地同步備份。
-
T1 節點類型不支援異地同步備份。
-
Valkey 和 Redis OSS 複寫是非同步的。因此,當主要節點容錯移轉至複本時,可能會因複寫延遲而導致一小部分的資料遺失。對於啟用耐久性的叢集,此限制不適用 — 所有遞交的資料都會從多可用區域交易日誌還原。
選擇要提升為主要複本的複本時,ElastiCache 會選擇具有最小複寫延遲的複本。換句話說,它會選擇最新的複本。這麼做有助於減少遺失的資料量。具有最少複寫延遲的複本可以和失敗的主要節點位於相同可用區域或不同可用區域中。
-
當您在停用叢集模式的 Valkey 或 Redis OSS 叢集上,手動將僅供讀取複本提升為主要叢集時,您只能在停用異地同步備份和自動容錯移轉時執行此操作。若要將僅供讀取複本節點提升為主要節點,請採取下列步驟:
-
停用叢集上的多個可用區。
-
停用叢集上的自動容錯移轉。您可以透過主控台清除複寫群組的自動容錯移轉核取方塊來執行此操作。您也可以在呼叫
ModifyReplicationGroup操作false時,將AutomaticFailoverEnabled屬性設定為 , AWS CLI 以使用 執行此操作。 -
將僅供讀取複本提升為主要節點。
-
重新啟用多個可用區。
-
-
ElastiCache for Redis OSS 多可用區和僅附加檔案 (AOF) 是互斥的。若您啟用其中一項,便無法啟用另外一項。
-
節點故障很少會是因為整個可用區域失敗所造成。在此情況下,只有在可用區域已備份時,才會建立取代失敗主要節點的複本。例如,假設有一個複寫群組,其中主要節點位於 AZ-a,複本位於 AZ-b 及 AZ-c。若主要節點失敗,複寫延隔最少的複本便會提升至主要叢集。然後 ElastiCache 只會在 AZ-a 復原且重新可用時,才會在 AZ-a (即失敗主節點的所在位置) 中建立新的複本。
-
由客戶初始化的主要節點重新開機不會觸發自動容錯移轉。其他重新開機和故障會觸發自動容錯移轉。
-
主要節點重新開機時,便會在回到線上時清除資料。當僅供讀取複本看到已清除的主要叢集時,它們便會清除資料複本,造成資料遺失。
-
在提升僅供讀取複本之後,其他複本便會和新的主要節點同步。初始化同步後,複本的內容會被刪除,而且它們會從新的主要節點同步資料。此同步程序會造成短暫的中斷,在此期間無法存取複本。此同步程序也會在與複本進行同步時,於主要節點上造成暫時性的負載增加。此行為是 Valkey 和 Redis OSS 的原生行為,對 ElastiCache Multi-AZ 而言並非唯一行為。如需此行為的詳細資訊,請參閱 Valkey 網站上的複寫
。對於啟用耐久性的叢集,複本會從交易日誌獨立還原,而不會對主要日誌施加負載。
重要
對於 Valkey 7.2.6 和更新版本或 Redis OSS 2.8.22 和更新版本,您無法建立外部複本。
對於 2.8.22 之前的 Redis OSS 版本,建議您不要將外部複本連接到已啟用異地同步備份的 ElastiCache 叢集。這是不受支援的組態,可能會造成問題,導致 ElastiCache 無法正常執行容錯移轉與復原。若要將外部複本連線至 ElastiCache 叢集,請確定在進行連線之前未啟用異地同步備份。
