本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
調整 Aurora PostgreSQL 的記憶體參數
在 Amazon Aurora PostgreSQL 中,您可以使用數個參數來控制用於各種處理任務的記憶體容量。如果工作佔用的記憶體超過為指定參數設定的量,Aurora PostgreSQL 會使用其他資源進行處理,例如寫入磁碟。這可能會導致您的 Aurora PostgreSQL 資料庫叢集變慢或可能停止,並發生記憶體不足錯誤。
每個記憶體參數的預設設定通常可以處理其預期的處理工作。然而,您也可以調整 Aurora PostgreSQL 資料庫叢集 的記憶體相關參數。您可以執行此調整,以確保為處理特定工作負載配置了足夠的記憶體。
您可以在下方找到有關控制記憶體管理的參數的資訊。您也可以了解如何評估記憶體使用率。
檢查和設定參數值
您可以設定用來管理記憶體和評估 Aurora PostgreSQL 資料庫叢集記憶體使用量的參數如下:
work_mem– 指定 Aurora PostgreSQL 資料庫叢集在寫入暫存磁碟檔案之前,用於內部排序操作和雜湊表的記憶體數量。log_temp_files– 記錄臨時檔案建立、檔案名稱和大小。此參數開啟時,會為建立的每個暫存檔儲存一個日誌項目。開啟此選項可查看您的 Aurora PostgreSQL 資料庫叢集需要寫入磁碟有多頻繁。收集有關 Aurora PostgreSQL 資料庫叢集產生暫存檔的資訊後,請再次將其關閉,以避免過度記錄。logical_decoding_work_mem– 指定每個內部重新排序緩衝區在溢出到磁碟之前要使用的記憶體量 (以 KB 為單位)。此記憶體用於邏輯解碼,這是用來建立複本的程序。它會藉由將資料從預寫日誌 (WAL) 檔案轉換為目標所需的邏輯串流輸出來完成。此參數的值會為每個複寫連線建立指定大小的單一緩衝區。根據預設,其為 65536 KB。此緩衝區填滿後,多餘的內容會以檔案的形式寫入磁碟。若要將磁碟活動最小化,您可以將此參數的值設定為遠遠高於
work_mem。
這些都是動態參數,因此您可以針對目前工作階段變更它們。若要這麼做,請使用 psql 連線到 Aurora PostgreSQL 資料庫叢集 ,並使用 SET 陳述式,如下所示。
SET parameter_name TO parameter_value;工作階段設定僅限工作階段期間內有效。工作階段結束時,參數會回復為資料庫叢集參數群組中的設定。 (資料庫參數群組) 在變更任何參數之前,請先查詢 pg_settings 資料表,檢查目前的值,如下所示。
SELECT unit, setting, max_val FROM pg_settings WHERE name='parameter_name';
例如,若要尋找 work_mem 參數的值,請連線至 Aurora PostgreSQL 資料庫叢集的寫入器執行個體,然後執行下列查詢。
SELECT unit, setting, max_val, pg_size_pretty(max_val::numeric) FROM pg_settings WHERE name='work_mem';unit | setting | max_val | pg_size_pretty ------+----------+-----------+---------------- kB | 1024 | 2147483647| 2048 MB (1 row)
變更參數設定,使其持續需要使用自訂資料庫叢集參數群組。 (資料庫參數群組) 以這些參數不同的值使用 SET 陳述式來訓練您的 Aurora PostgreSQL 資料庫叢集 後,您可以建立自訂參數群組,並套用至您的 Aurora PostgreSQL 資料庫叢集。如需詳細資訊,請參閱Amazon Aurora 的參數群組。
了解工作記憶參數
工作記憶參數 (work_mem) 指定 Aurora PostgreSQL 可用來處理複雜查詢的最大記憶體容量。複雜的查詢包括涉及排序或分組作業的查詢 - 換句話說,使用下列子句的查詢:
ORDER BY
DISTINCT
GROUP BY
JOIN (MERGE 和 HASH)
查詢規劃工具會間接影響您的 Aurora PostgreSQL 資料庫叢集使用工作記憶體的方式。查詢規劃程式會產生處理 SQL 陳述式的執行計劃。給定的計劃可能會將複雜的查詢分解為可以平行運行的多個工作單元。如果可能的話,Aurora PostgreSQL 在每個平行程序寫入磁碟之前,會使用在 work_mem 參數中為每個工作階段指定的記憶體的量。
多個資料庫使用者同時執行多項作業,且平行產生多個工作單位,可能會耗盡 Aurora PostgreSQL 資料庫叢集分配的工作記憶體。這可能會導致建立的暫存檔和磁碟 I/O 過多,或者更糟糕的是,可能導致記憶體不足錯誤。
識別暫存檔案的使用
當處理查詢所需的記憶體超過 work_mem 參數中指定的值,工作資料會卸載到磁碟中的暫存檔。您可以開啟 log_temp_files 參數,以查看發生這種情況的頻率。此參數預設會被關閉 (被設定為 -1)。若要擷取所有暫存檔資訊,請將此參數設定為 0。將 log_temp_files 設定為任何其他正整數,以擷取資料量等於或大於該值之檔案 (以 KB 為單位) 的暫存檔資訊。在下圖中,您可以看到來自 的範例 AWS 管理主控台。
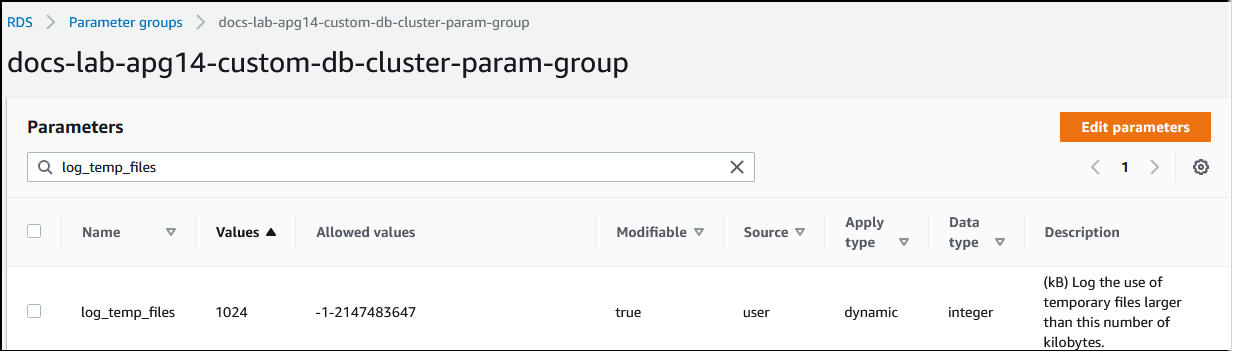
設定暫存檔記錄功能後,您可以使用自己的工作負載進行測試,以查看工作記憶體設定是否足夠。您也可以使用 pgbench (PostgreSQL 社群提供的簡單基準測試應用程式) 來模擬工作負載。
以下範例會建立運行測試所需的資料表和資料列,以初始化 (-i) pgbench。在此範例中,擴展係數 (-s 50) 會在 pgbench_branches 資料表中建立 50 個資料列,在 pgbench_tellers 中建立 500 個資料列,以及在 labdb 資料庫的 pgbench_accounts 資料表中建立 5,000,000 資料列。
pgbench -U postgres -h your-cluster-instance-1.111122223333.aws-regionrds.amazonaws.com -p 5432 -i -s 50 labdb
Password:
dropping old tables...
NOTICE: table "pgbench_accounts" does not exist, skipping
NOTICE: table "pgbench_branches" does not exist, skipping
NOTICE: table "pgbench_history" does not exist, skipping
NOTICE: table "pgbench_tellers" does not exist, skipping
creating tables...
generating data (client-side)...
5000000 of 5000000 tuples (100%) done (elapsed 15.46 s, remaining 0.00 s)
vacuuming...
creating primary keys...
done in 61.13 s (drop tables 0.08 s, create tables 0.39 s, client-side generate 54.85 s, vacuum 2.30 s, primary keys 3.51 s)初始化環境後,您可以針對特定時間 (-T) 和用戶端數量 (-c) 執行基準測試。此範例還會使用當 Aurora PostgreSQL 資料庫叢集處理交易時輸出除錯資訊的 -d 選項。
pgbench -h -U postgresyour-cluster-instance-1.111122223333.aws-regionrds.amazonaws.com -p 5432 -d -T 60 -c 10labdbPassword:*******pgbench (14.3) starting vacuum...end. transaction type: <builtin: TPC-B (sort of)> scaling factor: 50 query mode: simple number of clients: 10 number of threads: 1 duration: 60 s number of transactions actually processed: 1408 latency average = 398.467 ms initial connection time = 4280.846 ms tps = 25.096201 (without initial connection time)
如需 pg_upgrade 的詳細資訊,請參閱 PostgreSQL 文件中的 pgbench
您可以使用 psql 元資料命令 (\d) 列出 pgbench 建立的關聯,例如資料表、檢視和索引。
labdb=>\d pgbench_accountsTable "public.pgbench_accounts" Column | Type | Collation | Nullable | Default ----------+---------------+-----------+----------+--------- aid | integer | | not null | bid | integer | | | abalance | integer | | | filler | character(84) | | | Indexes: "pgbench_accounts_pkey" PRIMARY KEY, btree (aid)
如輸出所示,pgbench_accounts 資料表的 aid 資料欄建立了索引。若要確保下一個查詢使用工作記憶體,請查詢任何非索引資料欄,例如下列範例中所示。
postgres=>SELECT * FROM pgbench_accounts ORDER BY bid;
檢查臨時檔案的日誌。若要這樣做,請開啟 AWS 管理主控台,選擇 Aurora PostgreSQL 資料庫叢集執行個體,然後選擇日誌與事件索引標籤。在主控台中檢視日誌,或下載以供進一步分析。如下圖所示,處理查詢所需的暫存檔大小表示您應該考慮增加針對 work_mem 參數指定的量。
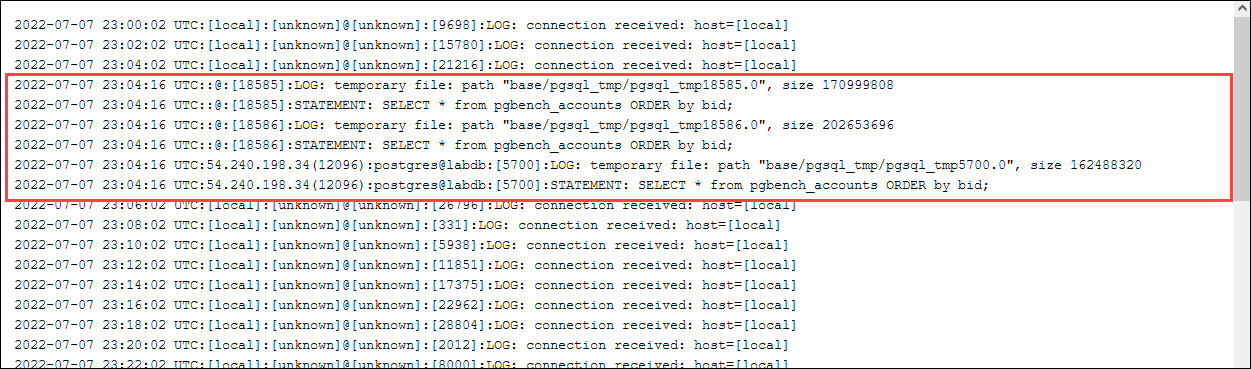
您可以根據您的營運需求,針對個人和群組以不同的方式設定此參數。例如,您可以針對名為 dev_team 的角色將 work_mem 參數設定為 8 GB。
postgres=>ALTER ROLEdev_teamSET work_mem=‘8GB';
使用此一 work_mem 的設定,屬於 dev_team 角色成員的任何角色都會分配到 8 GB 的工作內存。
使用索引加快回應時間
如果您的查詢傳回結果花費的時間太長,您可以驗證索引是否如預期般使用。首先,請啟用 \timing,psql 元命令,如下所示。
postgres=>\timing on
開啟計時後,請使用簡單的 SELECT 陳述式。
postgres=>SELECT COUNT(*) FROM (SELECT * FROM pgbench_accounts ORDER BY bid) AS accounts;count ------- 5000000 (1 row) Time: 3119.049 ms (00:03.119)
如輸出所示,此查詢需要 3 秒以上才能完成。若要縮短回應時間,請針對 pgbench_accounts 建立索引,如下所示。
postgres=>CREATE INDEX ON pgbench_accounts(bid);CREATE INDEX
重新執行查詢,並注意回應時間較快。在這個範例中,完成查詢大約需要半秒鐘,快了大約 5 倍。
postgres=>SELECT COUNT(*) FROM (SELECT * FROM pgbench_accounts ORDER BY bid) AS accounts;count ------- 5000000 (1 row) Time: 567.095 ms
調整邏輯解碼的工作記憶體
邏輯複製自從在 PostgreSQL 第 10 版引入以來,已在 Aurora PostgreSQL 的所有版本中使用。設定邏輯複製時,您也可以設定 logical_decoding_work_mem 參數,指定邏輯解碼程序可用於解碼和串流處理程序的記憶體數量。
在邏輯解碼期間,預寫日誌 (WAL) 記錄會轉換為 SQL 陳述式,接著會傳送至另一個目標以進行邏輯複寫或其他工作。當交易寫入 WAL 然後進行轉換時,整個交易必須符合針對 logical_decoding_work_mem 指定的值。此參數預設為 65536 KB。任何溢出都會寫入磁碟。這意味著必須先從磁碟重新讀取,然後才能傳送到目的地,這樣會減緩整個過程。
您可以使用 aurora_stat_file 函數評估目前工作負載在特定時間點的交易溢出量,如以下範例所示。
SELECT split_part (filename, '/', 2) AS slot_name, count(1) AS num_spill_files, sum(used_bytes) AS slot_total_bytes, pg_size_pretty(sum(used_bytes)) AS slot_total_size FROM aurora_stat_file() WHERE filename like '%spill%' GROUP BY 1;slot_name | num_spill_files | slot_total_bytes | slot_total_size ------------+-----------------+------------------+----------------- slot_name | 590 | 411600000 | 393 MB (1 row)
呼叫查詢時,此查詢會傳回 Aurora PostgreSQL 資料庫叢集上溢出檔案的計數和大小。執行時間較長的工作負載在磁碟上可能沒有任何溢出檔案。若要針對長時間執行的工作負載進行效能分析,建議您建立一個資料表,以便在工作負載執行時擷取溢出檔案資訊。您可以建立資料表,如下所示。
CREATE TABLE spill_file_tracking AS SELECT now() AS spill_time,* FROM aurora_stat_file() WHERE filename LIKE '%spill%';
若要查看邏輯複寫期間如何使用溢出檔案,請設定發布者和訂閱者,然後啟動簡單複寫。如需詳細資訊,請參閱針對 Aurora PostgreSQL 資料庫叢集設定邏輯複寫。進行複寫時,您可以建立一項工作,從 aurora_stat_file() 溢出檔函數擷取結果集,如下所示。
INSERT INTO spill_file_tracking SELECT now(),* FROM aurora_stat_file() WHERE filename LIKE '%spill%';
使用以下 psql 命令每秒運行一次作業。
\watch 0.5
工作執行時,從另一個 psql 工作階段連線到寫入器執行個體。使用以下一系列陳述式來執行超出記憶體組態的工作負載,並讓 Aurora PostgreSQL 建立溢出檔案。
labdb=>CREATE TABLE my_table (a int PRIMARY KEY, b int);CREATE TABLElabdb=>INSERT INTO my_table SELECT x,x FROM generate_series(0,10000000) x;INSERT 0 10000001labdb=>UPDATE my_table SET b=b+1;UPDATE 10000001
這些陳述式需要幾分鐘的時間來完成。完成後,同時按 Ctrl 鍵和 C 鍵停止監視功能。然後使用下列命令建立資料表,以保存 Aurora PostgreSQL 資料庫叢集溢出檔案使用情況的相關資訊。
SELECT spill_time, split_part (filename, '/', 2) AS slot_name, count(1) AS spills, sum(used_bytes) AS slot_total_bytes, pg_size_pretty(sum(used_bytes)) AS slot_total_size FROM spill_file_tracking GROUP BY 1,2 ORDER BY 1;spill_time | slot_name | spills | slot_total_bytes | slot_total_size ------------------------------+-----------------------+--------+------------------+----------------- 2022-04-15 13:42:52.528272+00 | replication_slot_name | 1 | 142352280 | 136 MB 2022-04-15 14:11:33.962216+00 | replication_slot_name | 4 | 467637996 | 446 MB 2022-04-15 14:12:00.997636+00 | replication_slot_name | 4 | 569409176 | 543 MB 2022-04-15 14:12:03.030245+00 | replication_slot_name | 4 | 569409176 | 543 MB 2022-04-15 14:12:05.059761+00 | replication_slot_name | 5 | 618410996 | 590 MB 2022-04-15 14:12:07.22905+00 | replication_slot_name | 5 | 640585316 | 611 MB (6 rows)
輸出顯示執行範例會建立五個使用 611 MB 記憶體的溢出檔案。若要避免寫入磁碟,建議將 logical_decoding_work_mem 參數設定為下一個最高記憶體大小,亦即 1024。
