本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
將ETL處理程序轉換 AWS Glue 為 AWS Schema Conversion Tool
接下來,您可以找到將ETL指令碼轉換為 AWS Glue 使用的程序大綱 AWS SCT。在此範例中,我們將 Oracle 資料庫轉換為 Amazon Redshift,以及與來源資料庫和資料倉儲搭配使用的ETL程序。
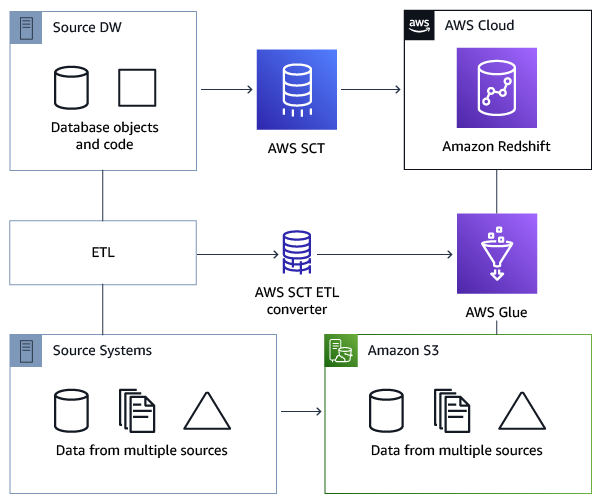
下列架構圖顯示範例資料庫移轉專案,其中包含將ETL指令碼轉換為 AWS Glue。
必要條件
開始之前,請執行以下動作:
-
移轉您要移轉至的任何來源資料庫 AWS。
-
將目標資料倉儲移轉至 AWS。
-
收集處理程序中涉及的所有ETL程式碼清單。
-
收集每個資料庫所有必要連線資訊的清單。
此外,還 AWS Glue 需要權限才能代表您存取其他 AWS 資源。您可以使用 AWS Identity and Access Management (IAM) 提供這些權限。請確定您已建立的IAM策略 AWS Glue。如需詳細資訊,請參閱開發人員指南中的為 AWS Glueservice 建立IAM政策。AWS Glue
瞭解資 AWS Glue 料目錄
作為轉換過程的一部分, AWS Glue 載入有關來源和目標資料庫的資訊。它會將此資訊組織成一種稱為樹狀結構的品類。結構包含以下項目:
-
連接 — 連接參數
-
搜尋器 — 檢索器的清單,每個結構描述一個爬行程式
-
資料庫 — 保存資料表的容器
-
表格 — 代表表格中資料的中繼資料定義
-
ETL工作 — 執行ETL工作的業務邏輯
-
觸發程式 — 控制ETL工作執行時間的邏輯 AWS Glue (無論是按需要、按排程還是由工作事件觸發)
AWS Glue 資料目錄是資料的位置、結構描述及執行時間指標的索引。當您使用 AWS Glue 和時 AWS SCT,「 AWS Glue 資料目錄」會包含資料的參考,這些資料在中做為ETL工作的來源和目標使用 AWS Glue。若要建立資料倉儲,請編目此資料。
您可以使用資料目錄中的資訊來建立和監視ETL工作。一般而言,您會執行爬蟲程式來清點資料存放區中的庫存,但仍有其他方式可將中繼資料資料表新增到資料目錄。
當您在資料目錄中定義資料表時,就會將資料表加入資料庫。資料庫用於在中組織表格 AWS Glue。
AWS SCT 搭配使用轉換的限制 AWS Glue
AWS SCT 搭配使用轉換時,適用下列限制 AWS Glue。
| Resource | 預設值限制 |
| 每個帳戶的資料庫數量 | 10,000 |
| 每個資料庫的資料表數量 | 100,000 |
| 每個資料表的分割區數量 | 1,000,000 |
| 每個資料表的資料表版本數量 | 100,000 |
| 每個帳戶的資料表數量 | 1,000,000 |
| 每個帳戶的分割區數量 | 10,000,000 |
| 每個帳戶的資料表版本數量 | 1,000,000 |
| 每個帳戶的連線數量 | 1,000 |
| 每個帳戶的爬蟲程式數量 | 25 |
| 每個帳戶的任務數量 | 25 |
| 每個帳戶的觸發數量 | 25 |
| 每個帳戶的並行執行任務數量 | 30 |
| 每個任務的並行執行任務數量 | 3 |
| 每個觸發的任務數量 | 10 |
| 每個帳戶的開發端點數量 | 5 |
| 開發端點一次使用的最大資料處理單元 (DPUs) | 5 |
| 一次DPUs由角色使用的上限 | 100 |
| 資料庫名稱長度 |
無限制 為了相容於其他中繼資料存放 (例如 Apache Hive),名稱會變為使用小寫字元。 如果您打算從 Amazon Athena 存取資料庫,請提供僅包含英數字元和底線字元的名稱。 |
| 連線名稱長度 | 無限制 |
| 爬蟲程式名稱長度 | 無限制 |
步驟 1:建立新的 專案
若要建立新專案,請執行下列高階步驟:
-
在中建立新專案 AWS SCT。如需詳細資訊,請參閱在中啟動和管理專案 AWS SCT。
-
將您的來源和目標資料庫新增至專案。如需詳細資訊,請參閱將伺服器新增至專案 AWS SCT。
請確定您已在目標資料庫連線設定 AWS Glue中選擇 [使用]。若要這麼做,請選擇索AWS Glue引標籤。在「從 AWS 設定檔複製」中,選擇您要使用的設定檔。設定檔應自動填入 AWS 存取金鑰、秘密金鑰和 Amazon S3 儲存貯體資料夾。若未自動填入,請手動輸入此資訊。選擇 「確定」 後,會 AWS Glue 分析物件並將中繼資料載入「 AWS Glue 資料目錄」。
根據您的安全設定,您可能會看到警告訊息,指出您的帳戶對於伺服器上的某些結構描述沒有足夠權限。若您可以存取正在使用的結構描述,則可以放心地忽略此訊息。
-
若要完成匯入的準備ETL,請連線至您的來源和目標資料庫。若要這麼做,請在來源或目標中繼資料樹狀結構中選擇您的資料庫,然後選擇 [Connect 到伺服器]。
AWS Glue 在來源資料庫伺服器上建立資料庫,並在目標資料庫伺服器上建立一個資料庫,以協助進行ETL轉換。目標伺服器上的資料庫包含「資 AWS Glue 料目錄」。若要尋找特定物件,請使用來源面板或目標面板上的搜尋。
若要查看特定物件的轉換方式,請尋找您要轉換的項目,然後從其內容選單中選擇 [轉換結構描述] (按一下滑鼠右鍵)。 AWS SCT 將此選取的物件轉換為腳本。
您可以從右側面板的「腳本」文件夾中查看轉換後的腳本。目前,指令碼是虛擬物件,只能做為 AWS SCT 專案的一部分使用。
若要使用轉換後的指令碼建立 AWS Glue 任務,請將指令碼上傳到 Amazon S3。若要將指令碼上傳到 Amazon S3,請選擇指令碼,然後從其內容 (按一下滑鼠右鍵) 功能表中選擇「儲存到 S3」。
步驟 2:建立 AWS Glue 工作
將指令碼儲存到 Amazon S3 後,您可以選擇該指令碼,然後選擇設定 AWS Glue Job 務以開啟精靈以設定 AWS Glue 任務。該嚮導可以更輕鬆地進行設置:
-
在精靈的第一個索引標籤「設計資料流程」上,您可以選擇執行策略以及要包含在此工作中的指令碼清單。您可以為每個指令碼選擇參數。您也可以重新安排指令碼,讓它們以正確的順序執行。
-
在第二個索引標籤上,您可以命名工作,並直接設定 AWS Glue。在此畫面上,您可以進行下列設定:
-
AWS Identity and Access Management (IAM)角色
-
指令碼檔案名稱和檔案路徑
-
使用 Amazon S3 受管金鑰 (-S3) 使用伺服器端加密指令碼加密 SSE
-
暫時目錄
-
產生的 Python 程式庫路徑
-
使用者 Python 程式庫路徑
-
相依 .jar 檔案的路徑
-
參考檔案路徑
-
每次執行DPUs的作業並行
-
最大並行數量
-
任務逾時 (以分鐘為單位)
-
延遲通知閾值 (以分鐘為單位)
-
重試次數
-
安全組態
-
伺服器端加密
-
-
在第三個步驟或標籤中,您可以選擇已設定的目標端點連線。
完成設定工作之後,它會顯示在「資 AWS Glue 料目錄」中的ETL工作下。如果您選擇任務,系統會顯示設定,以便您檢閱或編輯任務。若要在中建立新 Job AWS Glue,請從工 AWS Glue 作的前後關聯 (滑鼠右鍵) 功能表中選擇「建立工作」。這麼做適用於結構描述定義。若要重新整理顯示,請選擇內容 (按一下滑鼠右鍵) 功能表中的 Refresh from database (從資料庫重新整理)。
此時,您可以在 AWS Glue 主控台中檢視工作。若要這麼做,請登入 AWS Management Console 並在開啟主 AWS Glue 控台https://console.aws.amazon.com/glue/
您可以測試新任務是否能正確運作。若要這麼做,請先檢查來源資料表中的資料,並驗證目標資料表是否為空。執行任務,然後再檢查一次。您可以從 AWS Glue 主控台檢視錯誤記錄。
