本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
使用 將 Hadoop 工作負載遷移至 Amazon EMR AWS Schema Conversion Tool
若要遷移 Apache Hadoop 叢集,請確定您使用 1 AWS SCT .0.670 版或更新版本。此外,請熟悉 的命令列界面 (CLI) AWS SCT。如需詳細資訊,請參閱的 CLI 參考 AWS Schema Conversion Tool。
主題
遷移概觀
下圖顯示從 Apache Hadoop 遷移至 Amazon EMR 的架構圖。
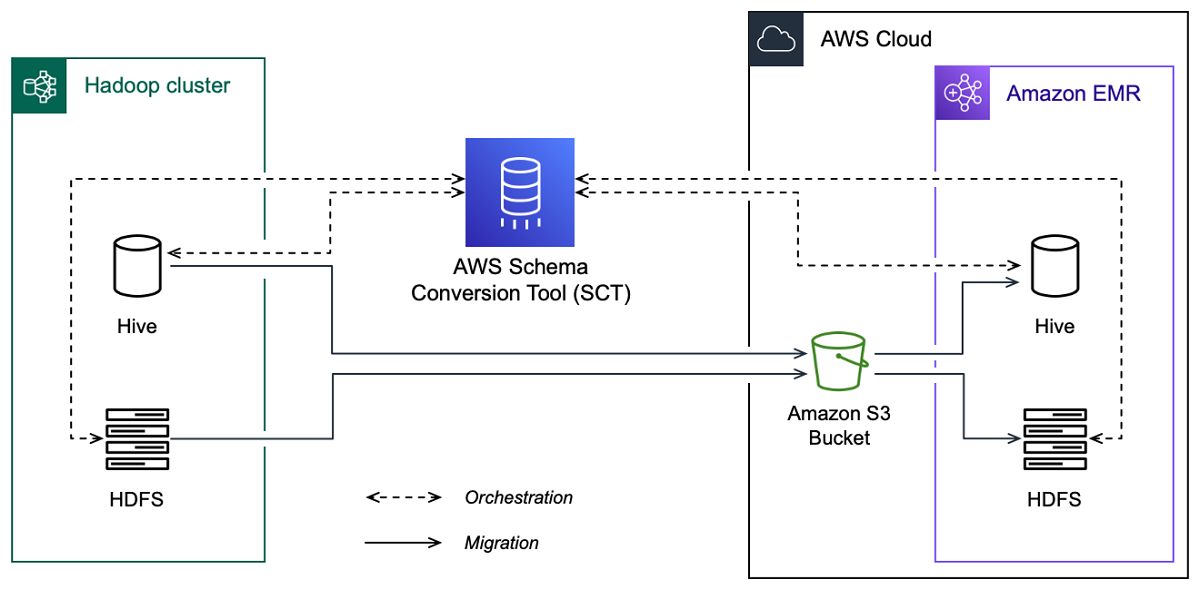
AWS SCT 會將來源 Hadoop 叢集的資料和中繼資料遷移至 Amazon S3 儲存貯體。接著, AWS SCT 使用您的來源 Hive 中繼資料,在目標 Amazon EMR Hive 服務中建立資料庫物件。或者,您可以將 Hive 設定為使用 AWS Glue Data Catalog 做為其中繼存放區。在此情況下, 會將來源 Hive 中繼資料 AWS SCT 遷移至 AWS Glue Data Catalog。
然後,您可以使用 將資料從 Amazon S3 儲存貯體 AWS SCT 遷移到目標 Amazon EMR HDFS 服務。或者,您可以將資料保留在您的 Amazon S3 儲存貯體中,並將其用作 Hadoop 工作負載的資料儲存庫。
若要開始 Hapood 遷移,您可以建立並執行 CLI AWS SCT 指令碼。此指令碼包含執行遷移的完整命令集。您可以下載和編輯 Hadoop 遷移指令碼的範本。如需詳細資訊,請參閱取得 CLI 案例。
請確定您的指令碼包含下列步驟,以便從 Apache Hadoop 執行遷移至 Amazon S3 和 Amazon EMR。
步驟 1:連線至 Hadoop 叢集
若要開始遷移 Apache Hadoop 叢集,請建立新的 AWS SCT 專案。接著,連線至您的來源和目標叢集。開始遷移之前,請務必建立和佈建目標 AWS 資源。
在此步驟中,您會使用下列 AWS SCT CLI 命令。
CreateProject– 建立新的 AWS SCT 專案。AddSourceCluster– 連接到 AWS SCT 專案中的來源 Hadoop 叢集。AddSourceClusterHive– 連接到專案中的來源 Hive 服務。AddSourceClusterHDFS– 連接到專案中的來源 HDFS 服務。AddTargetCluster– 連接到專案中的目標 Amazon EMR 叢集。AddTargetClusterS3– 將 Amazon S3 儲存貯體新增至您的專案。AddTargetClusterHive– 連接到專案中的目標 Hive 服務AddTargetClusterHDFS– 連接到專案中的目標 HDFS 服務
如需使用這些 AWS SCT CLI 命令的範例,請參閱 連線至 Apache Hadoop。
當您執行連線至來源或目標叢集的 命令時, 會 AWS SCT 嘗試建立與此叢集的連線。如果連線嘗試失敗,則 會 AWS SCT 停止從您的 CLI 指令碼執行命令,並顯示錯誤訊息。
步驟 2:設定映射規則
連線至來源和目標叢集之後,請設定映射規則。映射規則會定義來源叢集的遷移目標。請確定您已為 AWS SCT 專案中新增的所有來源叢集設定映射規則。如需映射規則的詳細資訊,請參閱 中的映射資料類型 AWS Schema Conversion Tool。
在此步驟中,您會使用 AddServerMapping命令。此命令使用兩個參數,定義來源和目標叢集。您可以使用 AddServerMapping命令搭配資料庫物件的明確路徑,或搭配物件名稱。對於第一個選項,您可以包含物件的類型及其名稱。對於第二個選項,您只包含物件名稱。
-
sourceTreePath– 來源資料庫物件的明確路徑。targetTreePath– 目標資料庫物件的明確路徑。 -
sourceNamePath– 僅包含來源物件名稱的路徑。targetNamePath– 僅包含目標物件名稱的路徑。
下列程式碼範例會使用來源 testdb Hive 資料庫和目標 EMR 叢集的明確路徑來建立映射規則。
AddServerMapping -sourceTreePath: 'Clusters.HADOOP_SOURCE.HIVE_SOURCE.Databases.testdb' -targetTreePath: 'Clusters.HADOOP_TARGET.HIVE_TARGET' /
您可以在 Windows 中使用此範例和下列範例。若要在 Linux 中執行 CLI 命令,請確定您已針對作業系統適當更新檔案路徑。
下列程式碼範例使用僅包含物件名稱的路徑來建立映射規則。
AddServerMapping -sourceNamePath: 'HADOOP_SOURCE.HIVE_SOURCE.testdb' -targetNamePath: 'HADOOP_TARGET.HIVE_TARGET' /
您可以選擇 Amazon EMR 或 Amazon S3 作為來源物件的目標。對於每個來源物件,您只能在單一 AWS SCT 專案中選擇一個目標。若要變更來源物件的遷移目標,請刪除現有的映射規則,然後建立新的映射規則。若要刪除映射規則,請使用 DeleteServerMapping命令。此命令使用下列兩個參數之一。
sourceTreePath– 來源資料庫物件的明確路徑。sourceNamePath– 僅包含來源物件名稱的路徑。
如需 AddServerMapping和 DeleteServerMapping命令的詳細資訊,請參閱 AWS Schema Conversion Tool CLI 參考
步驟 3:建立評估報告
開始遷移之前,建議您建立評估報告。此報告摘要所有遷移任務,並詳細說明遷移期間將出現的動作項目。為了確保遷移不會失敗,請檢視此報告,並在遷移之前處理動作項目。如需詳細資訊,請參閱評估報告。
在此步驟中,您會使用 CreateMigrationReport命令。此命令使用兩個參數。treePath 參數是強制性的,而 forceMigrate 參數是選用的。
treePath– 您儲存評估報告副本之來源資料庫物件的明確路徑。forceMigrate– 設為 時true,即使您的專案包含參照相同物件的 HDFS 資料夾和 Hive 資料表, 仍會 AWS SCT 繼續遷移。預設值為false。
然後,您可以將評估報告的副本儲存為 PDF 或逗號分隔值 (CSV) 檔案。若要這樣做,請使用 SaveReportPDF或 SaveReportCSV命令。
SaveReportPDF 命令會將評估報告的副本儲存為 PDF 檔案。此命令使用四個參數。file 參數為必要,其他參數則為選用。
file– PDF 檔案的路徑及其名稱。filter– 您之前建立的篩選條件名稱,以定義要遷移的來源物件範圍。treePath– 您儲存評估報告副本之來源資料庫物件的明確路徑。namePath– 僅包含您儲存評估報告副本之目標物件名稱的路徑。
SaveReportCSV 命令會將您的評估報告儲存在三個 CSV 檔案中。此命令使用四個參數。directory 參數為必要,其他參數則為選用。
directory– AWS SCT 儲存 CSV 檔案的資料夾路徑。filter– 您之前建立的篩選條件名稱,以定義要遷移的來源物件範圍。treePath– 您儲存評估報告副本之來源資料庫物件的明確路徑。namePath– 僅包含您儲存評估報告副本之目標物件名稱的路徑。
下列程式碼範例會將評估報告的副本儲存在 c:\sct\ar.pdf 檔案中。
SaveReportPDF -file:'c:\sct\ar.pdf' /
下列程式碼範例會將評估報告的副本儲存為 c:\sct 資料夾中的 CSV 檔案。
SaveReportCSV -file:'c:\sct' /
如需 SaveReportPDF和 SaveReportCSV命令的詳細資訊,請參閱 AWS Schema Conversion Tool CLI 參考
步驟 4:使用 將 Apache Hadoop 叢集遷移至 Amazon EMR AWS SCT
設定 AWS SCT 專案後,開始將內部部署 Apache Hadoop 叢集遷移至 AWS 雲端。
在此步驟中,您會使用 Migrate、 MigrationStatus和 ResumeMigration命令。
Migrate 命令會將您的來源物件遷移至目標叢集。此命令使用四個參數。請務必指定 filter或 treePath 參數。其他參數為選用。
filter– 您之前建立的篩選條件名稱,以定義要遷移的來源物件範圍。treePath– 您儲存評估報告副本之來源資料庫物件的明確路徑。forceLoad– 設定為 時true, 會在遷移期間 AWS SCT 自動載入資料庫中繼資料樹狀目錄。預設值為false。forceMigrate– 設為 時true,即使您的專案包含參照相同物件的 HDFS 資料夾和 Hive 資料表, 仍會 AWS SCT 繼續遷移。預設值為false。
MigrationStatus 命令會傳回遷移進度的相關資訊。若要執行此命令,請輸入 name 參數的遷移專案名稱。您在 CreateProject命令中指定此名稱。
ResumeMigration 命令會繼續您使用 Migrate命令啟動的中斷遷移。ResumeMigration 命令不使用參數。若要繼續遷移,您必須連線到來源和目標叢集。如需詳細資訊,請參閱管理您的遷移專案。
下列程式碼範例會將資料從來源 HDFS 服務遷移至 Amazon EMR。
Migrate -treePath: 'Clusters.HADOOP_SOURCE.HDFS_SOURCE' -forceMigrate: 'true' /
執行您的 CLI 指令碼
完成編輯 CLI AWS SCT 指令碼後,將其儲存為副.scts檔名為 的檔案。現在,您可以從 AWS SCT 安裝路徑的 app 資料夾執行指令碼。為此,請使用下列命令。
RunSCTBatch.cmd --pathtoscts "C:\script_path\hadoop.scts"
在上述範例中,使用 CLI 指令碼取代 script_path 為 檔案的路徑。如需在 中執行 CLI 指令碼的詳細資訊 AWS SCT,請參閱 指令碼模式。
管理您的大數據遷移專案
完成遷移後,您可以儲存和編輯 AWS SCT 專案以供日後使用。
若要儲存 AWS SCT 專案,請使用 SaveProject命令。此命令不使用參數。
下列程式碼範例會儲存您的 AWS SCT 專案。
SaveProject /
若要開啟 AWS SCT 專案,請使用 OpenProject命令。此命令使用一個強制性參數。針對 file 參數,輸入 AWS SCT 專案檔案的路徑及其名稱。您在 CreateProject命令中指定專案名稱。請務必將 .scts 副檔名新增至專案檔案名稱,以執行 OpenProject命令。
下列程式碼範例會從 c:\sct 資料夾開啟hadoop_emr專案。
OpenProject -file: 'c:\sct\hadoop_emr.scts' /
開啟 AWS SCT 專案之後,您不需要新增來源和目標叢集,因為您已將它們新增至專案。若要開始使用來源和目標叢集,您必須連線到它們。若要這樣做,您可以使用 ConnectSourceCluster和 ConnectTargetCluster命令。這些命令使用與 AddSourceCluster和 AddTargetCluster命令相同的參數。您可以編輯 CLI 指令碼,並取代這些命令的名稱,讓參數清單保持不變。
下列程式碼範例會連線至來源 Hadoop 叢集。
ConnectSourceCluster -name: 'HADOOP_SOURCE' -vendor: 'HADOOP' -host: 'hadoop_address' -port: '22' -user: 'hadoop_user' -password: 'hadoop_password' -useSSL: 'true' -privateKeyPath: 'c:\path\name.pem' -passPhrase: 'hadoop_passphrase' /
下列程式碼範例會連線至目標 Amazon EMR 叢集。
ConnectTargetCluster -name: 'HADOOP_TARGET' -vendor: 'AMAZON_EMR' -host: 'ec2-44-44-55-66.eu-west-1.EXAMPLE.amazonaws.com' -port: '22' -user: 'emr_user' -password: 'emr_password' -useSSL: 'true' -privateKeyPath: 'c:\path\name.pem' -passPhrase: '1234567890abcdef0!' -s3Name: 'S3_TARGET' -accessKey: 'AKIAIOSFODNN7EXAMPLE' -secretKey: 'wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY' -region: 'eu-west-1' -s3Path: 'doc-example-bucket/example-folder' /
在上述範例中,將 hadoop_address 取代為 Hadoop 叢集的 IP 地址。如有需要,請設定連接埠變數的值。接著,以 Hadoop 使用者的名稱和此使用者的密碼取代 hadoop_user 和 hadoop_password。針對 path\name,輸入來源 Hadoop 叢集的 PEM 檔案名稱和路徑。如需新增來源和目標叢集的詳細資訊,請參閱 使用 連線至 Apache Hadoop 資料庫 AWS Schema Conversion Tool。
連線至來源和目標 Hadoop 叢集之後,您必須連線至 Hive 和 HDFS 服務,以及 Amazon S3 儲存貯體。若要這樣做,您可以使用 ConnectSourceClusterHive、ConnectSourceClusterHdfs、ConnectTargetClusterHdfs、 ConnectTargetClusterHive和 ConnectTargetClusterS3命令。這些命令使用與您用來將 Hive 和 HDFS 服務以及 Amazon S3 儲存貯體新增至專案的命令相同的參數。編輯 CLI 指令碼,在命令名稱Connect中將Add字首取代為 。
