本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
Amazon Chime SDK 呼叫分析資料湖可讓您將機器學習支援的洞見和任何中繼資料從 Amazon Kinesis Data Stream 串流到 Amazon S3 儲存貯體。例如,使用資料湖來存取 URLs 以進行錄音。若要建立資料湖,您可以從 Amazon Chime SDK 主控台或以程式設計方式使用 部署一組 AWS CloudFormation 範本 AWS CLI。資料湖可讓您在 Amazon Athena 中參考 AWS Glue 資料表,以查詢通話中繼資料和語音分析資料。
先決條件
您必須具有下列項目,才能建立 Amazon Chime SDK 湖:
-
Amazon Kinesis 資料串流。如需詳細資訊,請參閱《Amazon Kinesis Streams 開發人員指南》中的透過 AWS 管理主控台建立串流。 Amazon Kinesis
-
S3 儲存貯體。如需詳細資訊,請參閱《Amazon S3 使用者指南》中的建立您的第一個 Amazon S3 儲存貯體。 Amazon S3
Data Lake 術語和概念
使用以下術語和概念來了解資料湖的運作方式。
- Amazon Kinesis Data Firehose
-
擷取、轉換和載入 (ETL) 服務,可可靠地擷取、轉換串流資料,並將資料交付至資料湖、資料存放區和分析服務。如需詳細資訊,請參閱什麼是 Amazon Kinesis Data Firehose?
- Amazon Athena
-
Amazon Athena 是一種互動式查詢服務,可讓您使用標準 SQL 分析 Amazon S3 中的資料。Athena 是無伺服器,因此您沒有要管理的基礎設施,您只需為執行的查詢付費。若要使用 Athena,請指向 Amazon S3 中的資料、定義結構描述,並使用標準 SQL 查詢。您也可以使用工作群組來將使用者分組,並控制他們在執行查詢時可存取的資源。工作群組可讓您管理查詢並行,並排定不同使用者和工作負載群組之間的查詢執行優先順序。
- Glue Data Catalog
-
在 Amazon Athena 中,資料表和資料庫包含詳細說明基礎來源資料的結構描述的中繼資料。對於每個資料集,Athena 中必須存在資料表。資料表中的中繼資料會告知 Athena Amazon S3 儲存貯體的位置。它也會指定資料結構,例如資料欄名稱、資料類型和資料表的名稱。資料庫只會保留資料集的中繼資料和結構描述資訊。
建立多個資料湖
可以透過提供唯一的 Glue 資料庫名稱來指定存放呼叫洞見的位置,來建立多個資料湖。對於指定的 AWS 帳戶,可以有數個呼叫分析組態,每個組態都有對應的資料湖。這表示資料分離可以套用至特定使用案例,例如自訂保留政策,以及資料存放方式的存取政策。可以套用不同的安全政策來存取洞見、錄音和中繼資料。
Data lake 區域可用性
Amazon Chime SDK 資料湖可在下列區域使用。
區域 |
Glue 資料表 |
Amazon QuickSight |
|---|---|---|
us-east-1 |
可用性 |
可用性 |
us-west-2 |
可用性 |
可用性 |
eu-central-1 |
可用性 |
可用性 |
資料湖架構
下圖顯示資料湖架構。圖中的數字對應於下方的編號文字。
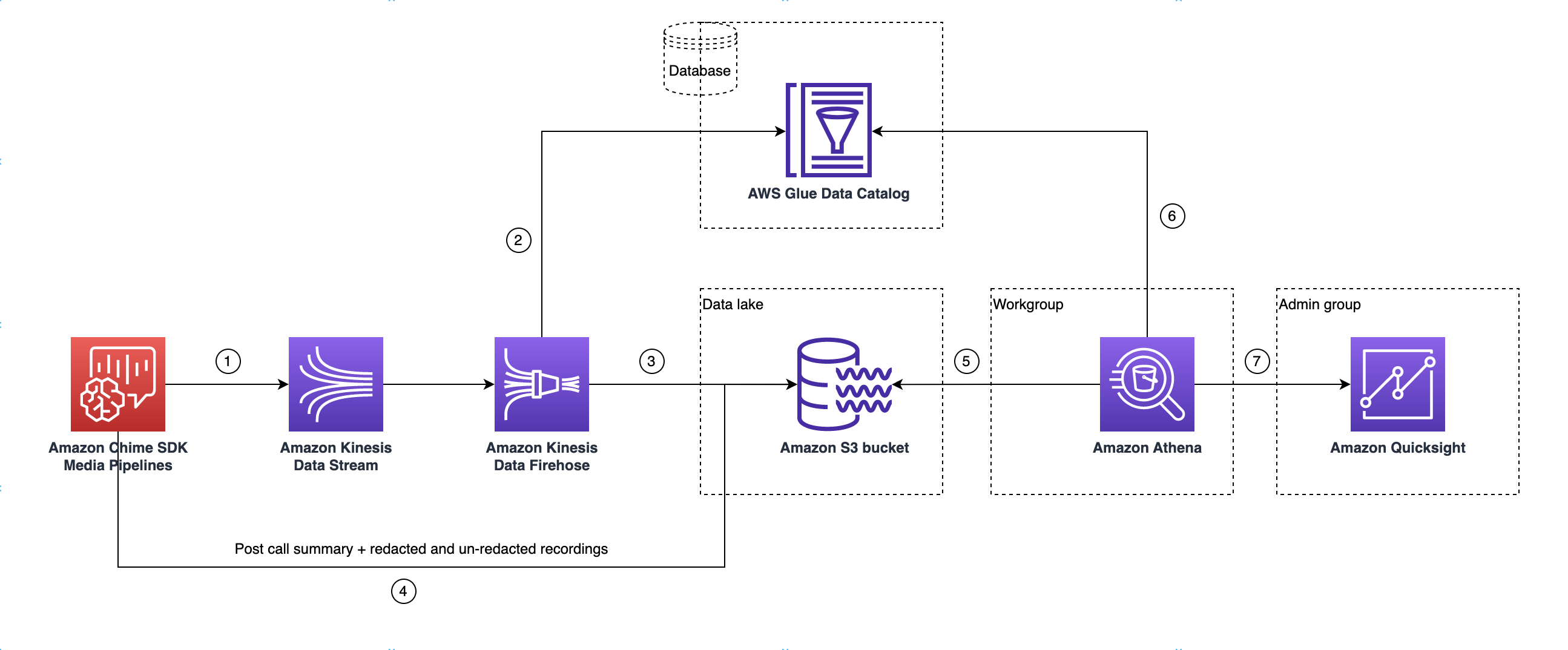
在圖表中,當您使用 AWS 主控台從媒體洞見管道組態設定工作流程部署 CloudFormation 範本時,下列資料會流向 Amazon S3 儲存貯體:
-
Amazon Chime SDK 呼叫分析將開始將即時資料串流到客戶的 Kinesis Data Stream。
-
Amazon Kinesis Firehose 會緩衝此即時資料,直到累積 128 MB 或 60 秒,以先到者為準。接著 Firehose 會使用 Glue Data Catalog
amazon_chime_sdk_call_analytics_firehose_schema中的 來壓縮資料,並將 JSON 記錄轉換為 Parquet 檔案。 -
parquet 檔案以分割格式存放在 Amazon S3 儲存貯體中。
-
除了即時資料之外,通話後 Amazon Transcribe Call Analytics 摘要 .wav 檔案 (已編輯和未編輯,如果在組態中指定) 和通話記錄 .wav 檔案也會傳送至您的 Amazon S3 儲存貯體。
-
您可以使用 Amazon Athena 和標準 SQL 來查詢 Amazon S3 儲存貯體中的資料。
-
CloudFormation 範本也會建立 Glue Data Catalog,透過 Athena 查詢此通話後摘要資料。
-
您也可以使用 Amazon QuickSight 視覺化 Amazon S3 儲存貯體上的所有資料。 Amazon QuickSight QuickSight 使用 Amazon Athena 與 Amazon S3 儲存貯體建立連線。 Amazon Athena
Amazon Athena 資料表使用下列功能來最佳化查詢效能:
- 資料分割
-
分割會將您的資料表分割為部分,並根據日期、國家和區域等資料欄值將相關資料保留在一起。分割區充當虛擬資料欄。在此情況下,CloudFormation 範本會在建立資料表時定義分割區,這有助於減少每個查詢掃描的資料量,並改善效能。您也可以依分割區篩選,以限制查詢掃描的資料量。如需詳細資訊,請參閱《Amazon Athena Athena 使用者指南》中的 Athena 中的分割資料。
此範例顯示日期為 2023 年 1 月 1 日的分割結構:
-
s3://example-bucket/amazon_chime_sdk_data_lake /serviceType=CallAnalytics/detailType={DETAIL_TYPE}/year=2023/month=01/day=01/example-file.parquet -
其中
DETAIL_TYPE是下列其中一項:-
CallAnalyticsMetadata -
TranscribeCallAnalytics -
TranscribeCallAnalyticsCategoryEvents -
Transcribe -
Recording -
VoiceAnalyticsStatus -
SpeakerSearchStatus -
VoiceToneAnalysisStatus
-
-
- 最佳化單欄式資料存放區產生
-
Apache Parquet 使用資料欄式壓縮、根據資料類型壓縮,以及述詞下推來存放資料。更佳的壓縮率或略過資料區塊,表示從 Amazon S3 儲存貯體讀取的位元組較少。這可提高查詢效能並降低成本。為了進行此最佳化,Amazon Kinesis Data Firehose 中會啟用從 JSON 到 parquet 的資料轉換。
- 分割區投影
-
此 Athena 功能會自動為每天建立分割區,以改善以日期為基礎的查詢效能。
資料湖設定
使用 Amazon Chime SDK 主控台來完成下列步驟。
-
啟動 Amazon Chime SDK 主控台 ( https://console.aws.amazon.com/chime-sdk/home
://),然後在 Call Analytics 下的導覽窗格中,選擇組態。 -
完成步驟 1,選擇下一步,然後在步驟 2 頁面上選擇語音分析核取方塊。
-
在輸出詳細資訊下,選取資料倉儲以執行歷史分析核取方塊,然後選擇部署 CloudFormation 堆疊連結。
系統會將您傳送至 CloudFormation 主控台中的快速建立堆疊頁面。
-
輸入堆疊的名稱,然後輸入下列參數:
-
DataLakeType– 選擇建立通話分析 DataLake。 -
KinesisDataStreamName– 選擇您的串流。它應該是用於呼叫分析串流的串流。 -
S3BucketURI– 選擇您的 Amazon S3 儲存貯體。URI 必須有字首s3://bucket-name -
GlueDatabaseName– 選擇唯一的 AWS Glue 資料庫名稱。您無法重複使用 AWS 帳戶中的現有資料庫。
-
-
選擇確認核取方塊,然後選擇建立資料湖。等待 10 分鐘讓系統建立湖。
使用 進行資料湖設定 AWS CLI
使用 AWS CLI 建立具有呼叫 CloudFormation 建立堆疊許可的角色。請依照下列程序來建立和設定 IAM 角色。如需詳細資訊,請參閱 AWS CloudFormation 使用者指南中的建立堆疊。
-
建立名為 AmazonChimeSdkCallAnalytics-Datalake-Provisioning-Role 的角色,並將信任政策連接至允許 CloudFormation 擔任該角色的角色。
-
使用下列範本建立 IAM 信任政策,並以 .json 格式儲存檔案。
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "cloudformation.amazonaws.com" }, "Action": "sts:AssumeRole", "Condition": {} } ] } -
執行 aws iam create-role命令,並將信任政策做為 參數傳遞。
aws iam create-role \ --role-name AmazonChimeSdkCallAnalytics-Datalake-Provisioning-Role --assume-role-policy-document file://role-trust-policy.json -
記下從回應傳回的角色 arn。在下一個步驟中需要角色 arn。
-
-
建立具有建立 CloudFormation 堆疊許可的政策。
-
使用下列範本建立 IAM 政策,並以 .json 格式儲存檔案。呼叫 create-policy 時需要此檔案。
{ "Version": "2012-10-17", "Statement": [ { "Sid": "DeployCloudFormationStack", "Effect": "Allow", "Action": [ "cloudformation:CreateStack" ], "Resource": "*" } ] } -
執行aws iam create-policy並傳遞建立堆疊政策做為 參數。
aws iam create-policy --policy-name testCreateStackPolicy --policy-document file://create-cloudformation-stack-policy.json -
記下從回應傳回的角色 arn。下一個步驟中需要角色 arn。
-
-
將 aws iam attach-role-policy 政策連接到角色。
aws iam attach-role-policy --role-name {Role name created above} --policy-arn {Policy ARN created above} -
建立 CloudFormation 堆疊並輸入必要的參數:aws cloudformation create-stack。
使用 ParameterValue 為每個 ParameterKey 提供參數值。 ParameterValue
aws cloudformation create-stack --capabilities CAPABILITY_NAMED_IAM --stack-name testDeploymentStack --template-url https://chime-sdk-assets.s3.amazonaws.com/public_templates/AmazonChimeSDKDataLake.yaml --parameters ParameterKey=S3BucketURI,ParameterValue={S3 URI} ParameterKey=DataLakeType,ParameterValue="Create call analytics datalake" ParameterKey=KinesisDataStreamName,ParameterValue={Name of Kinesis Data Stream} --role-arn {Role ARN created above}
資料湖設定建立的資源
下表列出建立資料湖時建立的資源。
資源類型 |
資源名稱和描述 |
服務名稱 |
|---|---|---|
AWS Glue Data Catalog 資料庫 |
GlueDatabaseName – 邏輯分組屬於呼叫洞見和語音分析的所有 AWS Glue 資料表。 |
通話分析、語音分析 |
|
AWS Glue Data Catalog 資料表 |
amazon_chime_sdk_call_analytics_firehose_schema – 供饋送至 Kinesis Firehose 的呼叫分析語音分析的合併結構描述。 |
通話分析、語音分析 |
call_analytics_metadata – 呼叫分析中繼資料的結構描述。包含 SIPmetadata和 OneTimeMetadata。 |
呼叫分析 |
|
| call_analytics_recording_metadata – 錄製和語音增強中繼資料的結構描述 | 通話分析、語音分析 | |
transcribe_call_analytics – TranscribeCallAnalytics 承載 "utteranceEvent" 的結構描述 |
呼叫分析 |
|
transcribe_call_analytics_category_events – TranscribeCallAnalytics 承載 "categoryEvent" 的結構描述 |
呼叫分析 |
|
transcribe_call_analytics_post_call – 通話後 Transcribe Call Analytics 摘要承載的結構描述 |
呼叫分析 |
|
轉錄 – 轉錄承載的結構描述 |
呼叫分析 |
|
voice_analytics_status – 語音分析就緒事件的結構描述 |
語音分析 |
|
speaker_search_status – 識別相符項目的結構描述 |
語音分析 |
|
voice_tone_analysis_status – 語音音調分析事件的結構描述 |
語音分析 |
|
Amazon Kinesis Data Firehose |
AmazonChimeSDK-call-analytics- |
通話分析、語音分析 |
Amazon Athena 工作群組 |
GlueDatabaseName-AmazonChimeSDKDataAnalytics – 邏輯使用者群組,用於控制他們在執行查詢時可存取的資源。 |
通話分析、語音分析 |
