本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
在 中使用同質資料遷移從 PostgreSQL 資料庫遷移資料 AWS DMS
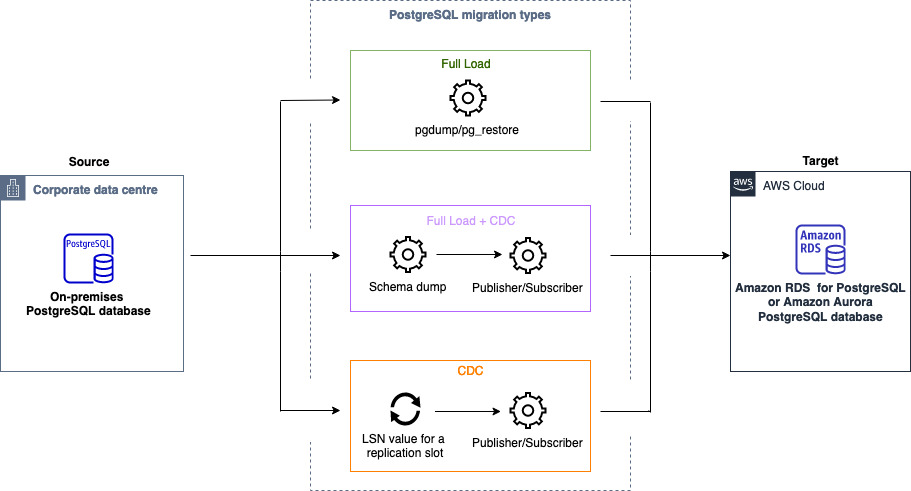
您可以使用 同質資料遷移 將自我管理的 PostgreSQL 資料庫遷移到 RDS for PostgreSQL 或 Aurora PostgreSQL。 AWS DMS 會為您的資料遷移建立無伺服器環境。對於不同類型的資料遷移, AWS DMS 將使用不同的原生 PostgreSQL 資料庫工具。
對於完全載入類型的同質資料遷移, AWS DMS 會使用 pg_dump 從您的來源資料庫讀取資料,並將其存放在連接到無伺服器環境的磁碟上。在 AWS DMS 讀取您的所有來源資料後,它會使用目標資料庫中的 pg_restore 來還原您的資料。
對於完全載入和變更資料擷取 (CDC) 類型的同質資料遷移, AWS DMS 會使用 從您的來源資料庫pg_dump讀取沒有資料表資料的結構描述物件,並將其存放在連接到無伺服器環境的磁碟上。然後,它會pg_restore在目標資料庫中使用 來還原您的結構描述物件。 AWS DMS 完成pg_restore程序後,它會自動切換到發佈者和訂閱者模型以進行邏輯複寫,Initial Data Synchronization並可選擇將初始資料表資料直接從來源資料庫複製到目標資料庫,然後啟動持續複寫。在此模型中,一或多個訂閱用戶訂閱了發布者節點上的一或多個發布項目。
對於變更資料擷取 (CDC) 類型的同質資料遷移, AWS DMS 需要原生起點才能開始複寫。如果您提供原生起點,則 會 AWS DMS 擷取該時間點的變更。或者,若在資料遷移設定中選擇立即,便可在實際資料遷移開始時自動擷取複寫的起點。
注意
若要讓僅限 CDC 遷移正常運作,所有來源資料庫的結構描述和物件都必須已存在於目標資料庫中。不過,目標可以包含不存在於來源上的物件。
您可以使用下列程式碼範例,取得 PostgreSQL 資料庫中的原生起始點。
select confirmed_flush_lsn from pg_replication_slots where slot_name=‘migrate_to_target';
此查詢會使用 PostgreSQL 資料庫中的 pg_replication_slots 檢視來擷取日誌序號 (LSN) 值。
在 AWS DMS 將 PostgreSQL 同質資料遷移的狀態設定為已停止、失敗或刪除後,不會移除發佈者和複寫。如果您不想繼續遷移,請使用下列命令刪除複寫插槽和發布者。
SELECT pg_drop_replication_slot('migration_subscriber_{ARN}'); DROP PUBLICATION publication_{ARN};
下圖顯示使用 中的同質資料遷移 AWS DMS 將 PostgreSQL 資料庫遷移至 RDS for PostgreSQL 或 Aurora PostgreSQL 的程序。
使用 PostgreSQL 資料庫做為同質資料遷移來源的最佳實務
若要加速 FLCDC 任務訂閱者端的初始資料同步,您必須調整
max_logical_replication_workers和max_sync_workers_per_subscription。增加這些值可增強資料表同步速度。max_logical_replication_workers – 指定邏輯複寫工作者的數量上限。這包括訂閱者端的套用工作者和資料表同步工作者。
max_sync_workers_per_subscription – 增加
max_sync_workers_per_subscription只會影響平行同步的資料表數量,不會影響每個資料表的工作者數量。
注意
max_logical_replication_workers不應超過max_worker_processes,且max_sync_workers_per_subscription應小於或等於max_logical_replication_workers。若要遷移大型資料表,請考慮使用選取規則將其分割成不同的任務。例如,您可以將大型資料表劃分為個別任務,將小型資料表劃分為另一個單一任務。
在訂閱者端監控磁碟和 CPU 用量,以維持最佳效能。
