本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
Flink 自動擴展器
概要
Amazon EMR 6.15.0 版及更高版本支援 Flink 自動擴展器。作業自動擴展器功能會從執行 Flink 串流作業中收集指標,並自動擴展個別作業頂點。這樣可以減少背壓並滿足您設定的使用率目標。
如需詳細資訊,請參閱 Apache Flink Kubernetes Operator 文件的自動擴展器
考量事項
-
Amazon EMR 6.15.0 及更高版本支援 Flink 自動擴展器。
-
Flink 自動擴展器僅支援串流作業。
-
僅支援調整式排程器。不支援預設排程器。
-
建議您啟用叢集擴展來允許動態資源佈建。建議使用 Amazon EMR 受管擴展功能,因為指標評估會每 5 到 10 秒進行一次。在此間隔內,您的叢集可以更容易地適應所需叢集資源的變更。
啟用自動擴展器
建立 Amazon EMR on EC2 叢集時,請使用以下步驟啟用 Flink 自動擴展器。
-
在 Amazon EMR 主控台中,建立新的 EMR 叢集:
-
選擇 Amazon EMR
emr-6.15.0版或更高版本。選取 Flink 應用程式套件,然後選取您可能要包含在叢集中的任何其他應用程式。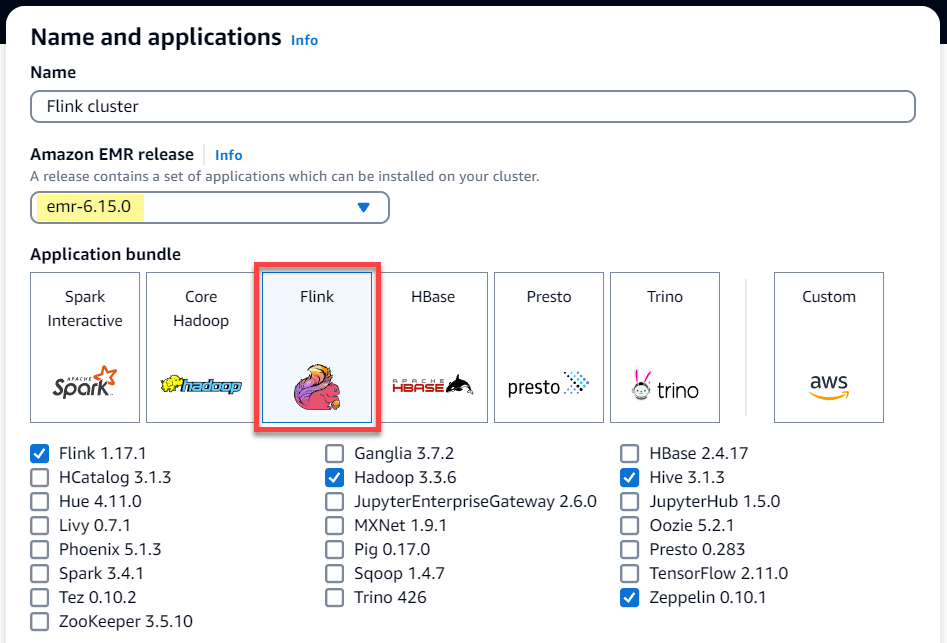
-
針對叢集擴展和佈建選項,選取使用 EMR 受管擴展。

-
-
在軟體設定區段中,輸入下列組態以啟用 Flink 自動擴展器。對於測試案例,請將決策間隔、指標時段間隔和穩定間隔設定為較低的值,如此作業就能立即制定擴展決策,以便更輕鬆地進行驗證。
[ { "Classification": "flink-conf", "Properties": { "job.autoscaler.enabled": "true", "jobmanager.scheduler": "adaptive", "job.autoscaler.stabilization.interval": "60s", "job.autoscaler.metrics.window": "60s", "job.autoscaler.decision.interval": "10s", "job.autoscaler.debug.logs.interval": "60s" } } ] -
根據需要選取或進行任何其他設定,然後建立已啟用 Flink 自動擴展器的叢集。
自動擴展器組態
本節介紹您可以根據特定需求變更的大多數組態。
注意
透過以時間為基礎的組態 (如 time、interval 和 window 設定),未指定單位時的預設單位是毫秒。因此沒有字尾的 30 值等於 30 毫秒。如需其他時間單位,請包含適當的字尾:秒為 s、分鐘為 m 或小時為 h。
自動擴展器迴圈組態
自動擴展器會針對每幾個可設定的時間間隔擷取作業頂點層級指標,將其轉換為擴展可行項目、預估新的作業頂點並行度,並將其推薦給作業排程器。只有在作業重新啟動時間和叢集穩定間隔之後才會收集指標。
| 組態鍵 | 預設值 | 描述 | 範例值 |
|---|---|---|---|
job.autoscaler.enabled |
false |
在 Flink 叢集上啟用自動擴展。 | true, false |
job.autoscaler.decision.interval |
60s |
自動擴展器決策間隔。 | 30 (預設單位為毫秒)、5m、1h |
job.autoscaler.restart.time |
3m |
在 Operator 能夠根據歷史記錄可靠地判斷之前,所使用的預期重新啟動時間。 | 30 (預設單位為毫秒)、5m、1h |
job.autoscaler.stabilization.interval |
300s |
不會執行新擴展的穩定期。 | 30 (預設單位為毫秒)、5m、1h |
job.autoscaler.debug.logs.interval |
300s |
自動擴展器偵錯日誌間隔。 | 30 (預設單位為毫秒)、5m、1h |
指標彙總和歷史記錄組態
自動擴展器會擷取指標,隨著時間根據滑動時段彙整這些指標,並對其進行評估以制定擴展決策。使用每個作業頂點的擴展決策歷史記錄來預估新的並行度。這些都具有以存在時間為基礎的到期日以及歷史記錄大小 (至少為 1)。
| 組態鍵 | 預設值 | 描述 | 範例值 |
|---|---|---|---|
job.autoscaler.metrics.window |
600s |
Scaling metrics aggregation window size. |
30 (預設單位為毫秒)、5m、1h |
job.autoscaler.history.max.count |
3 |
每個頂點可保留的過去擴展決策數量上限。 | 1 至 Integer.MAX_VALUE |
job.autoscaler.history.max.age |
24h |
每個頂點可保留的過去擴展決策數量下限。 | 30 (預設單位為毫秒)、5m、1h |
作業頂點層級組態
每個作業頂點的並行度會根據目標使用率進行修改,且受上下限並行度限制的約束。不建議將目標使用率設定為接近 100% (即值 1),使用率界限可作為緩衝,以處理中間負載波動。
| 組態鍵 | 預設值 | 描述 | 範例值 |
|---|---|---|---|
job.autoscaler.target.utilization |
0.7 |
目標頂點使用率。 | 0 - 1 |
job.autoscaler.target.utilization.boundary |
0.4 |
目標頂點使用率界限。如果目前的處理速率在 [target_rate /
(target_utilization - boundary) 和 (target_rate /
(target_utilization + boundary)] 內,則不會執行擴展。 |
0 - 1 |
job.autoscaler.vertex.min-parallelism |
1 |
自動擴展器可以使用的最小並行度。 | 0 - 200 |
job.autoscaler.vertex.max-parallelism |
200 |
自動擴展器可以使用的最大並行度。請注意,如果該並行度高於 Flink 組態中或直接在每個 Operator 上設定的最大並行度,則會忽略此限制。 | 0 - 200 |
待處理項目處理組態
作業頂點需要額外的資源來處理擴展操作期間累積的待處理事件或待處理項目。這也稱為 catch-up 持續時間。如果處理待處理項目的時間超過設定的 lag -threshold 值,作業頂點目標使用率會增加到最大層級。這有助於防止處理待處理項目時非必要的擴展操作。
| 組態鍵 | 預設值 | 描述 | 範例值 |
|---|---|---|---|
job.autoscaler.backlog-processing.lag-threshold |
5m |
延遲閾值,這將防止非必要的擴展,同時移除應為延遲負責的待處理訊息。 | 30 (預設單位為毫秒)、5m、1h |
job.autoscaler.catch-up.duration |
15m |
擴展操作之後完整處理任何待處理項目的目標持續時間。設定為 0 會停用以待處理項目為基礎的擴展。 | 30 (預設單位為毫秒)、5m、1h |
擴展操作組態
在寬限期內縱向擴展操作之後,自動擴展器不會立即執行縮減規模操作。這樣可以防止由暫時負載波動造成的非必要縱向-橫向擴展操作週期。
我們可以使用縮減規模操作比率逐漸降低並行度並釋放資源,以因應暫時的負載尖峰。其還有助於防止在大規模縮減規模操作之後非必要的小規模縱向擴展操作。
我們可以偵測以過去作業頂點擴展決策歷史記錄為基礎的有效縱向擴展操作,以防止進一步的並行度變更。
| 組態鍵 | 預設值 | 描述 | 範例值 |
|---|---|---|---|
job.autoscaler.scale-up.grace-period |
1h |
在縱向擴展後,不允許將頂點縮減規模的持續時間。 | 30 (預設單位為毫秒)、5m、1h |
job.autoscaler.scale-down.max-factor |
0.6 |
最大縮減規模係數。值 1 表示沒有縮減規模的限制;0.6 表示只能以原始並行度的 60% 縮減作業規模。 |
0 - 1 |
job.autoscaler.scale-up.max-factor |
100000. |
最大縱向擴展比率。2.0 值表示只能以目前並行度的 200% 縱向擴展作業。 |
0 - Integer.MAX_VALUE |
job.autoscaler.scaling.effectiveness.detection.enabled |
false |
是否啟用無效擴展操作的偵測,並允許自動擴展器阻止進一步縱向擴展。 | true, false |
