Amazon Forecast 不再提供給新客戶。Amazon Forecast 的現有客戶可以繼續正常使用服務。[進一步了解」](https://aws.amazon.com/blogs/machine-learning/transition-your-amazon-forecast-usage-to-amazon-sagemaker-canvas/)
本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
# 預測可解釋性
Forecast Explainability 可協助您更加了解資料集中的屬性如何影響特定時間序列 (項目和維度組合) 和時間點的預測。預測使用稱為影響分數的指標來量化每個屬性的相對影響,並判斷它們是否增加或減少預測值。
例如,假設目標所為 `sales` 且有兩個相關屬性的預測案例:`price` 與 `color`。預測可能會發現項目的顏色對某些項目的銷售影響很大,但對其他項目的影響微乎其微。它也可能發現,在夏季的促銷活動對銷售有很大的影響,但在冬季促銷影響不大。
若要啟用預測可解釋性,您的預測器必須至少包含下列其中一項:相關時間序列、項目中繼資料或假日和天氣索引等其他資料集。如需詳細資訊,請參閱[限制和最佳實務](predictor-explainability.md#predictor-explainability-best-practices)。
若要檢視資料集中所有時間序列和時間點的彙總影響分數,請使用 Predictor Explainability 而非 Forecast Explainability。請參閱[預測器可解釋性](predictor-explainability.md)。
**Python 筆記本**
如需預測可解釋性的step-by-step指南,請參閱[項目層級可解釋性](https://github.com/aws-samples/amazon-forecast-samples/blob/main/notebooks/advanced/Item_Level_Explainability/Item_Level_Explanability.ipynb)。
**Topics**
+ [解譯影響分數](#forecast-explainability-impact-scores)
+ [建立預測可解釋性](#creating-forecast-explainability)
+ [視覺化預測可解釋性](#visualizing-forecast-explainability)
+ [匯出預測可解釋性](#exporting-forecast-explainability)
+ [限制和最佳實務](#forecast-explainability-best-practices)
## 解譯影響分數
影響分數會衡量屬性對預測值的相對影響。例如,如果 "price" 屬性的影響分數是 "store location" 屬性的兩倍,您可以得出以下結論:項目的價格對預測值的影響是 "store location" 的兩倍。
影響分數也會提供屬性是否增加或減少預測值的相關資訊。在 主控台中,這會以兩個圖形表示。具有藍色長條的屬性會增加預測值,而具有紅色長條的屬性會減少預測值。
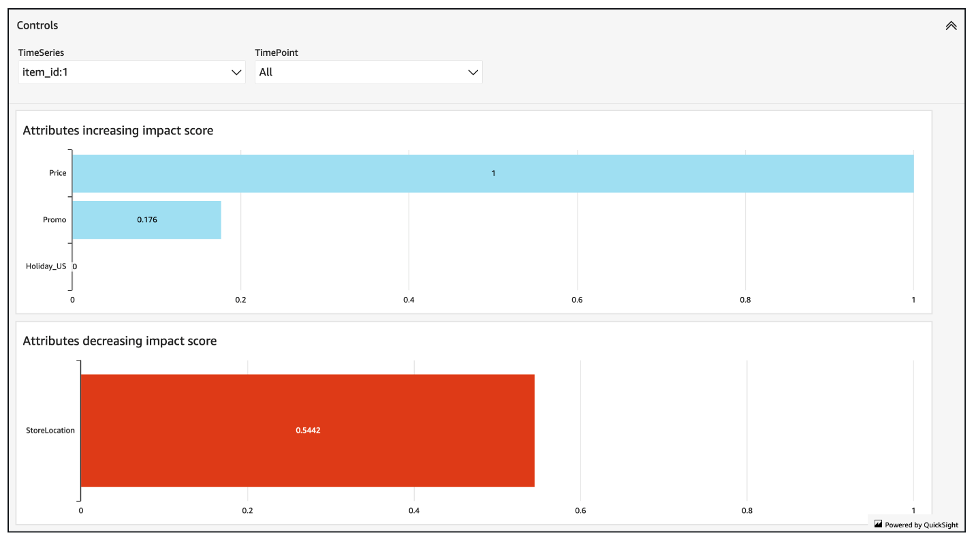
值得注意的是,影響力分數衡量的是屬性的相對影響,而不是絕對影響。因此,影響分數無法用於確定特定屬性是否可以改善模型的準確性。如果某個屬性的影響分數較低,不一定表示它對預測值的影響較低; 這表示與它對預測值的影響比預測器使用的其他屬性要小。
所有或部分影響分數可能為零。如果功能不會影響預測值、AutoPredictor 僅使用非 ML 演算法,或者您沒有提供相關的時間序列或項目中繼資料,則可能會發生這種情況。
對於預測可解釋性,影響分數有兩種形式:標準化影響分數和原始影響分數。原始影響分數是以 Shapley 值為基礎,且不會擴展或綁定。標準化影響分數會將原始分數擴展到介於 -1 和 1 之間的值。
原始影響分數有助於合併和比較不同可解釋性資源的分數。例如,如果您的預測器包含超過 50 個時間序列或超過 500 個時間點,您可以建立多個預測可解釋性資源,以涵蓋更多時間序列或時間點的合併數量,並直接比較屬性的原始影響分數。不過,來自不同預測的預測可解釋性資源的原始影響分數無法直接比較。
在主控台中檢視影響分數時,您只會看到標準化影響分數。匯出可解釋性將為您提供原始分數和標準化分數。
## 建立預測可解釋性
透過預測可解釋性,您可以探索屬性如何影響特定時間點序列的預測值。指定時間序列和時間點之後,Amazon Forecast 只會計算這些特定時間序列和時間點的影響分數。
您可以使用軟體開發套件 (SDK) 或 Amazon Forecast 主控台,為預測器啟用預測可解釋性。使用 SDK 時,請使用 [CreateExplainability](API_CreateExplainability.md) 操作。
**Topics**
+ [指定時間序列](#forecast-explainability-time-series)
+ [指定時間點](#forecast-explainability-time-points)
### 指定時間序列
**注意**
時間序列是項目 (item\_id) 和資料集中所有維度的組合
當您為預測可解釋性指定時間序列 (項目和維度組合) 時,Amazon Forecast 只會計算這些特定時間序列屬性的影響分數。
若要指定時間序列清單,請將依 item\_id 和維度值識別時間序列的 CSV 檔案上傳至 S3 儲存貯體。您最多可以指定 50 個時間序列。您還必須在結構描述中定義時間序列的屬性和屬性類型。
例如,零售商可能想知道促銷如何影響特定商店位置 (`item_id`) 中特定項目 () 的銷售`store_location`。在此使用案例中,您會指定 item\_id 和 store\_location 組合的時間序列。
下列 CSV 檔案會選取下列五個時間序列:
1. Item\_id:001,store\_location:西雅圖
1. Item\_id:001,store\_location:New York
1. Item\_id:002,store\_location:西雅圖
1. Item\_id:002,store\_location:New York
1. Item\_id:003,store\_location:丹佛
```
001, Seattle
001, New York
002, Seattle
002, New York
003, Denver
```
結構描述將第一欄定義為 `item_id`,第二欄定義為 `store_location`。
您可以使用預測主控台或預測軟體開發套件 (SDK) 來指定時間序列。
------
#### [ Console ]
**指定預測可解釋性的時間序列**
1. 登入 AWS 管理主控台 並開啟位於 https://[https://console.aws.amazon.com/forecast/](https://console.aws.amazon.com/forecast/) 的 Amazon Forecast 主控台。
1. 從**資料集群組**中,選擇您的資料集群組。
1. 在導覽窗格中,選擇 ** Insights**。
1. 選擇**建立可解釋性**。
1. 在可**解釋性名稱**欄位中,提供預測可解釋性的唯一名稱。
1. 在**選取預測**欄位中,選擇您的預測。
1. 在 **S3 位置**欄位中,輸入 檔案的位置與您的時間序列。
1. 在**資料結構描述**欄位中,設定時間序列中使用的項目 ID 和維度的**屬性名稱**和**屬性類型**。
1. 選擇**建立可解釋性。**
------
#### [ SDK ]
**指定預測可解釋性的時間序列**
使用 [CreateExplainability](API_CreateExplainability.md) 操作,為 ExplainabilityName 提供唯一名稱,並提供 ResourceArn 的預測 ARN。
設定下列資料類型:
+ `ExplainabilityConfig` - 將 TimeSeriesGranularity 的值設定為 "SPECIFIC",將 TimePointGranularity 設定為 "ALL"。(若要指定時間點,請將 TimePointGranularity 設定為「SPECIFIC」。 請參閱[指定時間點](#forecast-explainability-time-points))
+ `S3Config` - 將「路徑」的值設定為時間序列檔案的 S3 位置,並將「RoleArn」設定為可存取 S3 儲存貯體的角色。
+ `Schema` - 定義 item\_id 的「AttributeName」和「AttributeType」,以及時間序列中的維度。
以下範例顯示結合「item\_id」和「store\_location」維度的時間序列結構描述。
```
{
"ExplainabilityName" : [unique_name],
"ResourceArn" : [forecast_arn],
"ExplainabilityConfig" {
"TimeSeriesGranularity": "SPECIFIC",
"TimePointGranularity": "ALL"
},
"DataSource": {
"S3Config": {
"Path": [S3_path_to_file],
"RoleArn":[role-to-access-s3-bucket]
}
},
"Schema": {
"Attributes": [
{
"AttributeName": "item_id",
"AttributeType": "string"
},
{
"AttributeName": "store_location",
"AttributeType": "string"
}
]
},
}
```
------
### 指定時間點
**注意**
如果您未指定時間點 (`"TimePointGranularity": "ALL"`),Amazon Forecast 將在計算影響分數時考慮整個預測期間。
當您指定 Forecast Explainability 的時間點時,Amazon Forecast 會計算該特定時間範圍屬性的影響分數。您可以在預測期間內指定最多 500 個連續時間點。
例如,零售商可能想知道其屬性如何影響冬天的銷售。在此使用案例中,他們會指定僅跨越預測期間之冬季期間的時間點。
您可以使用預測主控台或預測軟體開發套件 (SDK) 來指定時間點。
------
#### [ Console ]
**指定預測可解釋性的時間序列**
1. 登入 AWS 管理主控台 ,並在 https://[https://console.aws.amazon.com/forecast/](https://console.aws.amazon.com/forecast/) 開啟 Amazon Forecast 主控台。
1. 從**資料集群組**中,選擇您的資料集群組。
1. 在導覽窗格中,選擇 ** Insights**。
1. 選擇**建立可解釋性**。
1. 在可**解釋性名稱**欄位中,提供預測可解釋性的唯一名稱。
1. 在**選取預測**欄位中,選擇您的預測。
1. 在 **S3 位置**欄位中,輸入 檔案的位置與您的時間序列。
1. 在**資料結構描述**欄位中,將*屬性名稱*設定為時間序列中使用的項目 ID 和維度的*屬性類型*。
1. 在**時間持續時間**欄位中,指定行事曆中的開始日期和結束日期。
1. 選擇**建立可解釋性。**
------
#### [ SDK ]
**指定預測可解釋性的時間序列**
使用 [CreateExplainability](API_CreateExplainability.md) 操作,為 ExplainabilityName 提供唯一的名稱,並提供 ResourceArn 的預測 ARN。使用以下時間戳記格式設定開始日期 (`StartDateTime`) 和結束日期 (`EndDateTime`):`yyyy-MM-ddTHH:mm:ss`(範例:2015-01-01T20:00:00)。
設定下列資料類型:
+ `ExplainabilityConfig` - 將 TimeSeriesGranularity 的值設定為「SPECIFIC」,將 TimePointGranularity 設定為「SPECIFIC」。
+ `S3Config` - 將「路徑」的值設定為時間序列檔案的 S3 位置,並將「RoleArn」設定為可存取 S3 儲存貯體的角色。
+ `Schema` - 定義 item\_id 的「AttributeName」和「AttributeType」,以及時間序列中的維度。
以下範例顯示結合「item\_id」和「store\_location」維度的時間序列結構描述。
```
{
"ExplainabilityName" : [unique_name],
"ResourceArn" : [forecast_arn],
"ExplainabilityConfig" {
"TimeSeriesGranularity": "SPECIFIC",
"TimePointGranularity": "SPECIFIC"
},
"DataSource": {
"S3Config": {
"Path": [S3_path_to_file],
"RoleArn":[role-to-access-s3-bucket]
}
},
"Schema": {
"Attributes": [
{
"AttributeName": "item_id",
"AttributeType": "string"
},
{
"AttributeName": "store_location",
"AttributeType": "string"
}
]
},
"StartDateTime": "string",
"EndDateTime": "string",
}
```
------
## 視覺化預測可解釋性
在主控台中建立預測可解釋性時,預測會自動視覺化您的影響分數。使用 [CreateExplainability](API_CreateExplainability.md) 操作建立預測可解釋性時,將 `EnableVisualization`設為「true」,並在主控台中視覺化該可解釋性資源的影響分數。
從可解釋性建立日期起,影響分數視覺化會持續 30 天。若要重新建立視覺化效果,請建立新的預測可解釋性。
## 匯出預測可解釋性
**注意**
匯出檔案可以直接從資料集匯入傳回資訊。如果匯入的資料含公式或命令,這會使檔案受到 CSV 注入的攻擊。因此,匯出的檔案可能會提示安全性警告。若要避免惡意活動,請在讀取匯出的檔案時停用連結和巨集。
預測可讓您將影響分數的 CSV 檔案匯出至 S3 位置。
匯出包含指定時間序列的原始和標準化影響分數,以及所有指定時間序列和所有指定時間點的標準化彙總影響分數。如果您未指定時間點,則已彙總預測期間所有時間點的影響分數。

您可以使用 Amazon Forecast 軟體開發套件 (SDK) 和 Amazon Forecast 主控台匯出 Forecast Explainability。
------
#### [ Console ]
**匯出預測可解釋性**
1. 登入 AWS 管理主控台 ,並在 https://[https://console.aws.amazon.com/forecast/](https://console.aws.amazon.com/forecast/) 開啟 Amazon Forecast 主控台。
1. 從**資料集群組**中,選擇您的資料集群組。
1. 在導覽窗格中,選擇 ** Insights**。
1. 選取您的可解釋性。
1. 從**動作**下拉式清單中,選擇**匯出**。
1. 在**匯出名稱**欄位中,提供 Forecast Explainability 匯出的唯一名稱。
1. 在 **S3 可解釋性匯出位置**欄位中,輸入 S3 位置以匯出 CSV 檔案。
1. 在 **IAM 角色**欄位中,選擇可存取所選 S3 位置的角色。
1. 選擇**建立可解釋性匯出**。
------
#### [ SDK ]
**匯出預測可解釋性**
使用 [CreateExplainabilityExport](API_CreateExplainabilityExport.md) 操作,指定`Destination`物件中的 S3 位置和 IAM 角色,以及 `ExplainabilityArn`和 `ExplainabilityExportName`。
例如:
```
{
"Destination": {
"S3Config": {
"Path": "s3://bucket/example-path/",
"RoleArn": "arn:aws:iam::000000000000:role/ExampleRole"
}
},
"ExplainabilityArn": "arn:aws:forecast:region:explainability/example",
"ExplainabilityName": "Explainability-export-name",
}
```
------
## 限制和最佳實務
使用 Forecast Explainability 時,請考慮下列限制和最佳實務。
+ **預測可解釋性僅適用於從 AutoPredictor 產生的某些預測 - **您無法為從舊版預測器產生的預測啟用預測可解釋性 (AutoML 或手動選擇)。請參閱[升級至 AutoPredictor](howitworks-predictor.md#upgrading-autopredictor)。
+ **預測可解釋性不適用於所有模型** - ARIMA (AutoRegressive移動平均值)、ETS (指數平滑狀態空間模型) 和 NPTS (非參數時間序列) 模型不包含外部時間序列資料。因此,即使您包含其他資料集,這些模型也不會建立可解釋性報告。
+ 可**解釋性需要屬性** - 您的預測器必須至少包含下列其中一項:相關時間序列、項目中繼資料、假日或天氣索引。
+ **零的影響分數表示沒有影響** - 如果一或多個屬性的影響分數為零,則這些屬性對預測值沒有重大影響。如果 AutoPredictor 僅使用非 ML 演算法,或者您沒有提供相關的時間序列或項目中繼資料,則分數也可以為零。
+ **指定最多 50 個時間序列 **- 每個預測可解釋性最多可指定 50 個時間序列。
+ **指定最多 500 個時間點** - 每個預測可解釋性最多可以指定 500 個連續時間點。
+ **預測也會計算一些彙總影響分數** - 預測也會提供指定時間序列和時間點的彙總影響分數。
+ **為單一預測建立多個預測可解釋性資源** - 如果您想要影響超過 50 個時間序列或 500 個時間點的分數,您可以批次建立可解釋性資源,以跨越更大的範圍。
+ **比較不同預測可解釋性資源的原始影響分數** - 可從相同的預測直接比較可解釋性資源的原始影響分數。
+ **Forecast Explainability 視覺化效果可在建立後 30 天內使用** - 若要在 30 天後檢視視覺化效果,請使用相同的組態建立新的 Forecast Explainability。