本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
Amazon FSx for Lustre 效能
本章提供 Amazon FSx for Lustre 效能主題,包括最佳化檔案系統效能的一些重要秘訣和建議。
主題
概觀
Amazon FSx for Lustre 以Lustre熱門的高效能檔案系統 為基礎,提供隨檔案系統大小線性增加的橫向擴展效能。 Lustre 檔案系統可水平擴展多個檔案伺服器和磁碟。此擴展可讓每個用戶端直接存取儲存在每個磁碟上的資料,以消除傳統檔案系統中存在的許多瓶頸。Amazon FSx for Lustre 以Lustre可擴展的架構為基礎,支援大量用戶端的高效能。
FSx for Lustre 檔案系統的運作方式
每個 FSx for Lustre 檔案系統都包含用戶端與之通訊的檔案伺服器,以及連接至每個儲存資料之檔案伺服器的一組磁碟。每個檔案伺服器都使用快速的記憶體內快取來增強最常存取資料的效能。視儲存體方案而定,您的檔案伺服器可以使用選用的 SSD 讀取快取進行佈建。當用戶端存取儲存在記憶體內或 SSD 快取中的資料時,檔案伺服器不需要從磁碟讀取資料,這可減少延遲並增加您可以驅動的總輸送量。下圖說明寫入操作的路徑、從磁碟提供的讀取操作,以及從記憶體或 SSD 快取提供的讀取操作。
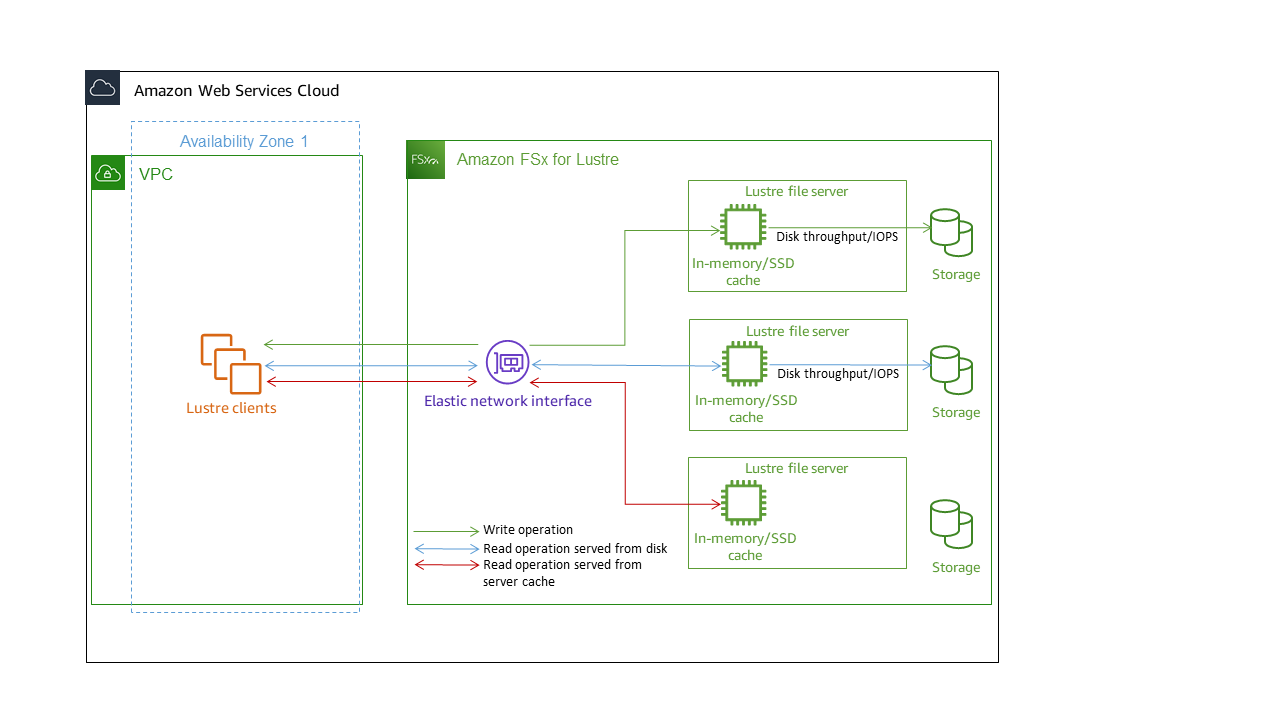
當您讀取存放在檔案伺服器記憶體內或 SSD 快取的資料時,檔案系統效能取決於網路輸送量。當您將資料寫入檔案系統,或讀取未存放在記憶體內快取的資料時,檔案系統效能取決於較低的網路輸送量和磁碟輸送量。
若要進一步了解 SSD 和 HDD 儲存類別的網路輸送量、磁碟輸送量和 IOPS 特性,請參閱 SSD 和 HDD 儲存類別的效能特性和 Intelligent-Tiering 儲存類別的效能特性。
檔案系統中繼資料效能
每秒檔案系統中繼資料 IO 操作 (IOPS) 決定您可以每秒建立、列出、讀取和刪除的檔案和目錄數量。
持久性 2 檔案系統可讓您佈建與儲存容量無關的中繼資料 IOPS,並提高對檔案系統上中繼資料 IOPS 用戶端執行個體數量和類型的可見性。使用 SSD 檔案系統時,中繼資料 IOPS 會根據您佈建的儲存容量自動佈建。Intelligent-Tiering 檔案系統不支援自動模式。
透過 FSx for Lustre 持久性 2 檔案系統,您佈建的中繼資料 IOPS 數量和中繼資料操作類型會決定檔案系統可支援的中繼資料操作速率。您佈建的中繼資料 IOPS 層級會決定為檔案系統中繼資料磁碟佈建的 IOPS 數目。
| 操作類型 | 您可以為每個佈建中繼資料 IOPS 每秒驅動的操作 |
|---|---|
|
檔案建立、開啟和關閉 |
2 |
|
檔案刪除 |
1 |
|
目錄建立、重新命名 |
0.1 |
|
目錄刪除 |
0.2 |
對於 SSD 檔案系統,您可以選擇使用自動模式佈建中繼資料 IOPS。在自動模式中,Amazon FSx 會根據檔案系統的儲存容量,根據下表自動佈建中繼資料 IOPS:
| 檔案系統儲存容量 | 在自動模式下包含中繼資料 IOPS |
|---|---|
|
1200 GiB |
1500 |
|
2400 GiB |
3000 |
|
4800–9600 GiB |
6000 |
|
12000–45600 GiB |
12000 |
|
≥48000 GiB |
每 24000 GiB 12000 IOPS |
在使用者佈建模式中,您可以選擇指定要佈建的中繼資料 IOPS 數目。有效值如下:
對於 SSD 檔案系統,有效值為
1500、3000、12000、6000和 的倍數12000,上限為192000。對於 Intelligent-Tiering 檔案系統,有效值為
6000和12000。
如需如何設定中繼資料 IOPS 的資訊,請參閱 管理中繼資料效能。請注意,您需要為佈建的中繼資料 IOPS 支付超過檔案系統預設中繼資料 IOPS 數量的費用。
個別用戶端執行個體的輸送量
如果您要建立輸送量超過 10 GBps 的檔案系統,建議您啟用 Elastic Fabric Adapter (EFA) 來最佳化每個用戶端執行個體的輸送量。為了進一步最佳化每個用戶端執行個體的輸送量,啟用 EFA 的檔案系統也支援啟用 EFA 的 NVIDIA GPU 用戶端執行個體的 GPUDirect Storage,以及啟用 ENA Express 的用戶端執行個體的 ENA Express。
您可以驅動到單一用戶端執行個體的輸送量取決於您選擇的檔案系統類型和用戶端執行個體上的網路介面。
| 檔案系統類型。 | 用戶端執行個體網路界面 | 每個用戶端的最大輸送量,Gbps |
|---|---|---|
|
未啟用 EFA |
任何 |
100 Gbps* |
|
啟用 EFA |
ENA |
100 Gbps* |
|
啟用 EFA |
ENA Express |
100 Gbps |
|
啟用 EFA |
EFA |
700 Gbps |
|
啟用 EFA |
EFA 搭配 GMS |
1200 Gbps |
注意
* 個別用戶端執行個體與個別 FSx for Lustre 物件儲存伺服器之間的流量限制為 5 Gbps。如需支援 FSx for Lustre 檔案系統的物件儲存伺服器數量檔案系統的 IP 地址,請參閱 。
檔案系統儲存配置
中的所有檔案資料Lustre都會存放在稱為物件儲存目標 (OST) 的儲存磁碟區上。 OSTs 所有檔案中繼資料 (包括檔案名稱、時間戳記、許可等) 都存放在稱為中繼資料目標 (MDTs儲存磁碟區上。Amazon FSx for Lustre 檔案系統由一或多個 MDTs 和多個 OSTs 組成。Amazon FSx for Lustre 會將檔案資料分散至組成檔案系統的 OSTs,以平衡儲存容量與輸送量和 IOPS 負載。
若要檢視組成檔案系統的 MDT 和 OSTs儲存用量,請從掛載檔案系統的用戶端執行下列命令。
lfs df -hmount/path
此令命的輸出結果如下所示:
範例
UUID bytes Used Available Use% Mounted onmountname-MDT0000_UUID 68.7G 5.4M 68.7G 0% /fsx[MDT:0]mountname-OST0000_UUID 1.1T 4.5M 1.1T 0% /fsx[OST:0]mountname-OST0001_UUID 1.1T 4.5M 1.1T 0% /fsx[OST:1] filesystem_summary: 2.2T 9.0M 2.2T 0% /fsx
分割檔案系統中的資料
您可以使用檔案分割來最佳化檔案系統的輸送量效能。Amazon FSx for Lustre 會自動將檔案分散到 OSTs,以確保從所有儲存伺服器提供資料。您可以透過設定檔案在多個 OSTs 之間分割的方式,在檔案層級套用相同的概念。
分割表示檔案可以分成多個區塊,然後存放在不同的 OSTs 中。當檔案分割到多個 OSTs 時,檔案的讀取或寫入請求會分散到這些 OSTs,從而提高您的應用程式可以驅動的彙總輸送量或 IOPS。
以下是 Amazon FSx for Lustre 檔案系統的預設配置。
對於 2020 年 12 月 18 日之前建立的檔案系統,預設配置會指定 1 的條紋計數。這表示除非指定不同的配置,否則使用標準 Linux 工具在 Amazon FSx for Lustre 中建立的每個檔案都會儲存在單一磁碟上。
對於 2020 年 12 月 18 日之後建立的檔案系統,預設配置是漸進式檔案配置,其大小小於 1GiB 的檔案會儲存在一個條紋中,而較大的檔案會獲指派 5 個條紋計數。
對於 2023 年 8 月 25 日之後建立的檔案系統,預設配置是 4 元件漸進式檔案配置,如 中所述漸進式檔案配置。
對於所有檔案系統,無論其建立日期為何,從 Amazon S3 匯入的檔案不會使用預設配置,而是在檔案系統的
ImportedFileChunkSize參數中使用配置。大於 S3-imported檔案ImportedFileChunkSize將存放在多個 OSTs 上,條紋計數為(FileSize / ImportedFileChunksize) + 1。的預設值ImportedFileChunkSize為 1GiB。
您可以使用 lfs getstripe命令檢視檔案或目錄的配置組態。
lfs getstripepath/to/filename
此命令會報告檔案的條紋計數、條紋大小和條紋位移。條紋計數是檔案分割的 OSTs數量。條紋大小是 OST 上存放多少連續資料。條紋位移是檔案分割第一個 OST 的索引。
修改您的分割組態
第一次建立檔案時,會設定檔案的配置參數。使用 lfs setstripe命令來建立具有指定配置的新空白檔案。
lfs setstripefilename--stripe-countnumber_of_OSTs
lfs setstripe 命令只會影響新檔案的配置。在建立檔案之前,請使用它來指定檔案的配置。您也可以定義目錄的配置。在目錄上設定之後,該配置會套用至新增至該目錄的每個新檔案,但不會套用至現有檔案。您建立的任何新子目錄也會繼承新的配置,然後將其套用至您在該子目錄中建立的任何新檔案或目錄。
若要修改現有檔案的配置,請使用 lfs migrate命令。此命令會視需要複製 檔案,以根據您在命令中指定的配置來分發其內容。例如,附加到 或 大小增加的檔案不會變更條紋計數,因此您必須遷移它們才能變更檔案配置。或者,您可以使用 lfs setstripe命令建立新的檔案,以指定其配置、將原始內容複製到新檔案,然後重新命名新檔案以取代原始檔案。
在某些情況下,預設配置組態可能不適合您的工作負載。例如,具有數十個 OSTs 和大量多 GB 檔案的檔案系統可能會看到更高的效能,方法是將檔案分割到超過五個 OSTs 的預設條紋計數值。建立具有低條紋計數的大型檔案可能會導致 I/O 效能瓶頸,也可能導致 OSTs 填滿。在這種情況下,您可以為這些檔案建立具有較大條紋計數的目錄。
設定大型檔案 (特別是大於 1 GB 的檔案) 的條紋配置很重要,原因如下:
允許多個 OSTs 及其相關聯的伺服器在讀取和寫入大型檔案時貢獻 IOPS、網路頻寬和 CPU 資源,以改善輸送量。
降低一小部分 OSTs 成為會限制整體工作負載效能熱點的可能性。
防止單一大型檔案填入 OST,這可能會導致磁碟完全錯誤。
所有使用案例都沒有單一的最佳配置組態。如需檔案配置的詳細指引,請參閱 https://Lustre.org 文件中的管理檔案配置 (分割) 和可用空間
條紋配置對大型檔案來說最為重要,尤其是檔案通常為數百 MB 以上的使用案例。因此,新檔案系統的預設配置會為大小超過 1GiB 的檔案指派 5 的分割計數。
條紋計數是您應針對支援大型檔案的系統調整的配置參數。條紋計數會指定將存放條紋檔案區塊的 OST 磁碟區數量。例如,如果條紋計數為 2 且條紋大小為 1MiB, 會將檔案的替代 1MiB 區塊Lustre寫入兩個 OSTs 中的每一個。
有效條紋計數是實際 OST 磁碟區數量和您指定的條紋計數值中較少的。您可以使用 的特殊條紋計數值
-1,指出應在所有 OST 磁碟區上放置條紋。為小型檔案設定大型條紋計數是次佳的,因為對於某些操作Lustre,需要網路往返到配置中的每個 OST,即使檔案太小而無法在所有 OST 磁碟區上耗用空間。
您可以設定漸進式檔案配置 (PFL),允許檔案的配置隨著大小而變更。PFL 組態可以簡化管理具有大型和小型檔案組合的檔案系統,而無需明確設定每個檔案的組態。如需詳細資訊,請參閱漸進式檔案配置。
條紋大小預設為 1MiB。設定條紋位移在特殊情況下可能很有用,但通常最好保持未指定狀態並使用預設值。
漸進式檔案配置
您可以為目錄指定漸進式檔案配置 (PFL) 組態,以在填入之前為小型和大型檔案指定不同的條紋組態。例如,您可以在最上層目錄上設定 PFL,再將任何資料寫入新的檔案系統。
若要指定 PFL 組態,請使用 lfs setstripe命令搭配 -E選項來指定不同大小檔案的配置元件,例如下列命令:
lfs setstripe -E 100M -c 1 -E 10G -c 8 -E 100G -c 16 -E -1 -c 32/mountname/directory
此命令會設定四個配置元件:
第一個元件 (
-E 100M -c 1) 表示大小上限為 100MiB 的檔案的條紋計數值為 1。第二個元件 (
-E 10G -c 8) 表示大小上限為 10GiB 的檔案的條紋計數為 8。第三個元件 (
-E 100G -c 16) 表示大小上限為 100GiB 的檔案的條紋計數為 16。第四個元件 (
-E -1 -c 32) 表示大於 100GiB 的檔案的條紋計數為 32。
重要
將資料附加至使用 PFL 配置建立的檔案,將會填入其所有配置元件。例如,使用上面顯示的 4 元件命令,如果您建立 1MiB 檔案,然後將資料新增至檔案的結尾,檔案的配置會擴展為 -1 的條紋計數,這表示系統中的所有 OSTs。這並不表示資料會寫入至每個 OST,但讀取檔案長度等操作會平行傳送至每個 OST,為檔案系統新增大量網路負載。
因此,請小心限制任何中小型檔案的條紋計數,這些檔案之後可以附加資料。由於日誌檔案通常會透過附加新記錄來成長,因此 Amazon FSx for Lustre 會將預設條紋計數 1 指派給在附加模式中建立的任何檔案,無論其父目錄指定的預設條紋組態為何。
Amazon FSx for Lustre 檔案系統上在 2023 年 8 月 25 日之後建立的預設 PFL 組態會使用此命令設定:
lfs setstripe -E 100M -c 1 -E 10G -c 8 -E 100G -c 16 -E -1 -c 32/mountname
具有對中型和大型檔案具有高度並行存取之工作負載的客戶,可能會受益於具有更多較小大小條紋的配置,以及針對最大檔案跨所有 OSTs 分割,如四個元件範例配置所示。
監控效能和用量
Amazon FSx for Lustre 每分鐘會為每個磁碟 (MDT 和 OST) 發出用量指標給 Amazon CloudWatch。
若要檢視彙總檔案系統用量詳細資訊,您可以查看每個指標的總和統計資料。例如,DataReadBytes統計資料的總和會報告檔案系統中所有 OSTs 所見的總讀取輸送量。同樣地,FreeDataStorageCapacity統計資料的總和會報告檔案系統中檔案資料的總可用儲存容量。
如需監控檔案系統效能的詳細資訊,請參閱 監控 Amazon FSx for Lustre 檔案系統。
