本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
指定資料表位置和分區層級
依預設,編目程式為 Amazon S3 中存放的資料定義資料表時,編目程式會嘗試將結構描述合併在一起並建立頂層資料表 (year=2019)。在某些情況下,您可能會預期爬蟲程式為資料夾 month=Jan 建立資料表,然而由於同級資料夾 (month=Mar) 已合併到相同的資料表中,因此爬蟲程式是建立分割區。
資料表層級爬蟲程式選項讓您可以靈活地告訴爬蟲程式資料表的位置,以及建立分割區的方式。當您指定 Table level (資料表層級),資料表會從 Amazon S3 儲存貯體在該絕對層級建立。
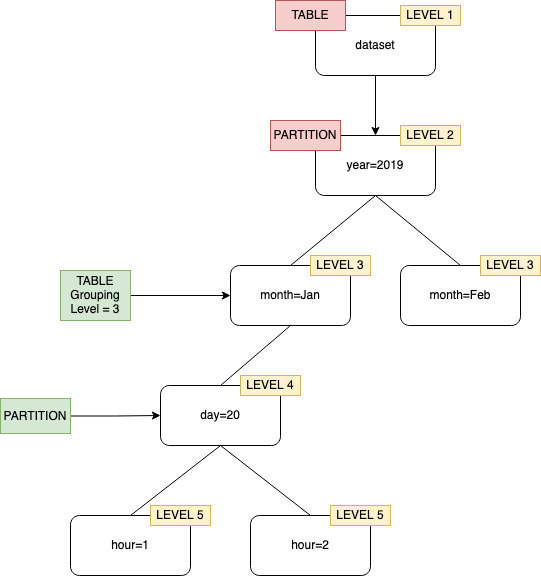
在主控台設定爬蟲程式時,您可指定 Table level (資料表層級) 爬蟲程式選項的值。值必須是正整數,表示資料表位置 (資料集中的絕對層級)。頂層資料夾的層級為 1。例如,對於路徑 mydataset/year/month/day/hour,如果層級設定為 3,則資料表會在位置 mydataset/year/month。