本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
將 Apache Spark 程式遷移到 AWS Glue
Apache Spark 是在大型資料集上執行的分散式運算工作負載的開放原始碼平台。AWS Glue 利用 Spark 的功能,為 ETL 提供最佳化的體驗。您可以將 Spark 程式遷移到 AWS Glue 以充分利用我們的功能。AWS Glue 提供與 Amazon EMR 上的 Apache Spark 相同的效能增強功能。
執行 Spark 程式碼
原生 Spark 程式碼可以在 AWS Glue 環境中立即執行。指令碼通常是透過反覆變更一段程式碼來開發,這樣的工作流程很適合互動式工作階段。但是,現有程式碼更適合在 AWS Glue 任務中執行,可讓您安排並持續取得每個指令碼執行的日誌和指標。您可以透過主控台上傳和編輯現有指令碼。
-
取得指令碼的來源。在此範例中,您將使用 Apache Spark 儲存庫中的範例指令碼。二值化器範例
-
在 AWS Glue 主控台中,展開左側導覽窗格,然後選取 ETL > Jobs (任務)
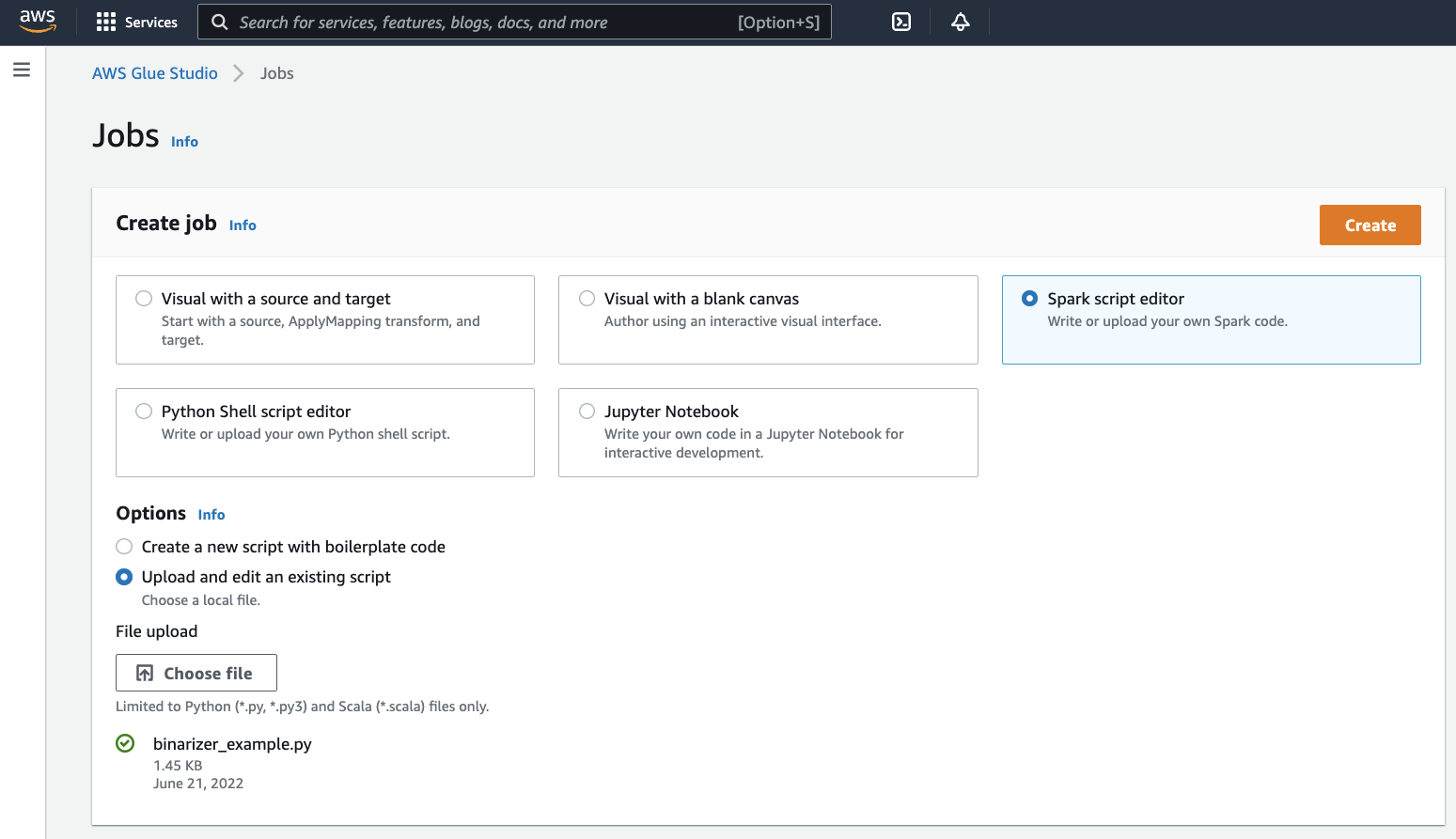
在 Create job (建立任務) 面板中,選取 Spark script editor (Spark 指令碼編輯器)。Options (選項) 區段將會出現。在 Options (選項) 下,選取 Upload and edit an existing script (上傳並編輯現有的指令碼)。
File upload (檔案上傳) 區段將會出現。在 File upload (檔案上傳) 下,按一下 Choose file (選擇檔案)。您的系統文件選擇器將會出現。導覽到您儲存
binarizer_example.py的位置中,選取它並確認。Create (建立 )按鈕會出現在 Create job (建立任務) 面板的標頭。按一下該按鈕。
-
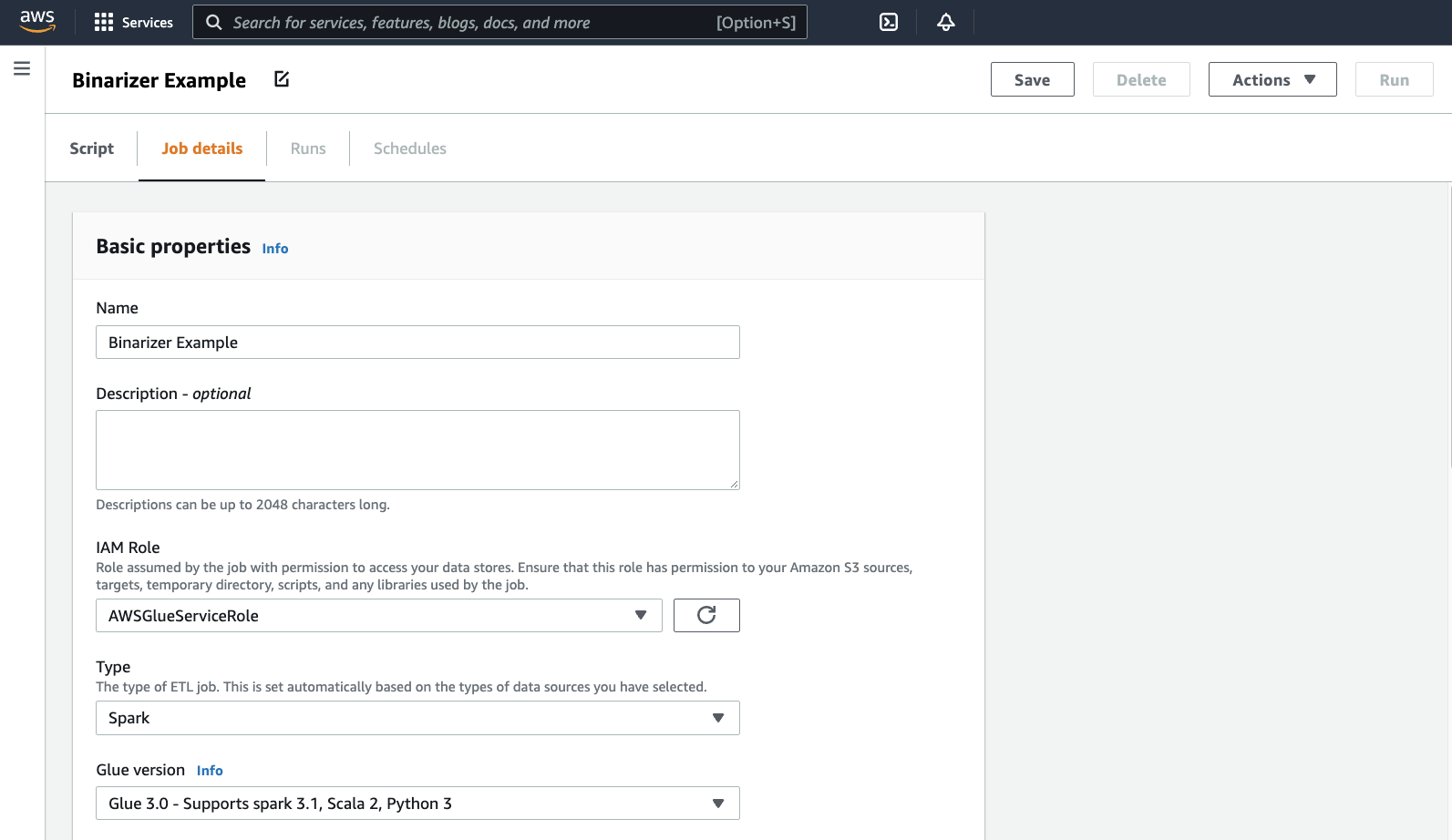
您的瀏覽器將導覽至指令碼編輯器。在標頭上,按一下 Job details (任務詳細資訊) 索引標籤。設定名稱和 IAM 角色。如需 AWS Glue IAM 角色的相關指引,請參閱 設定 的IAM許可 AWS Glue。
選用 - 將 Requested number of workers (請求的工作者數目) 設定為
2,並將 Number of retries (重試次數) 設定為1。這些選項在執行生產任務時非常重要,但是在測試功能時,關閉這些選項可以簡化您的體驗。在標題列中,按一下 Save (儲存),然後點選 Run (執行)
-
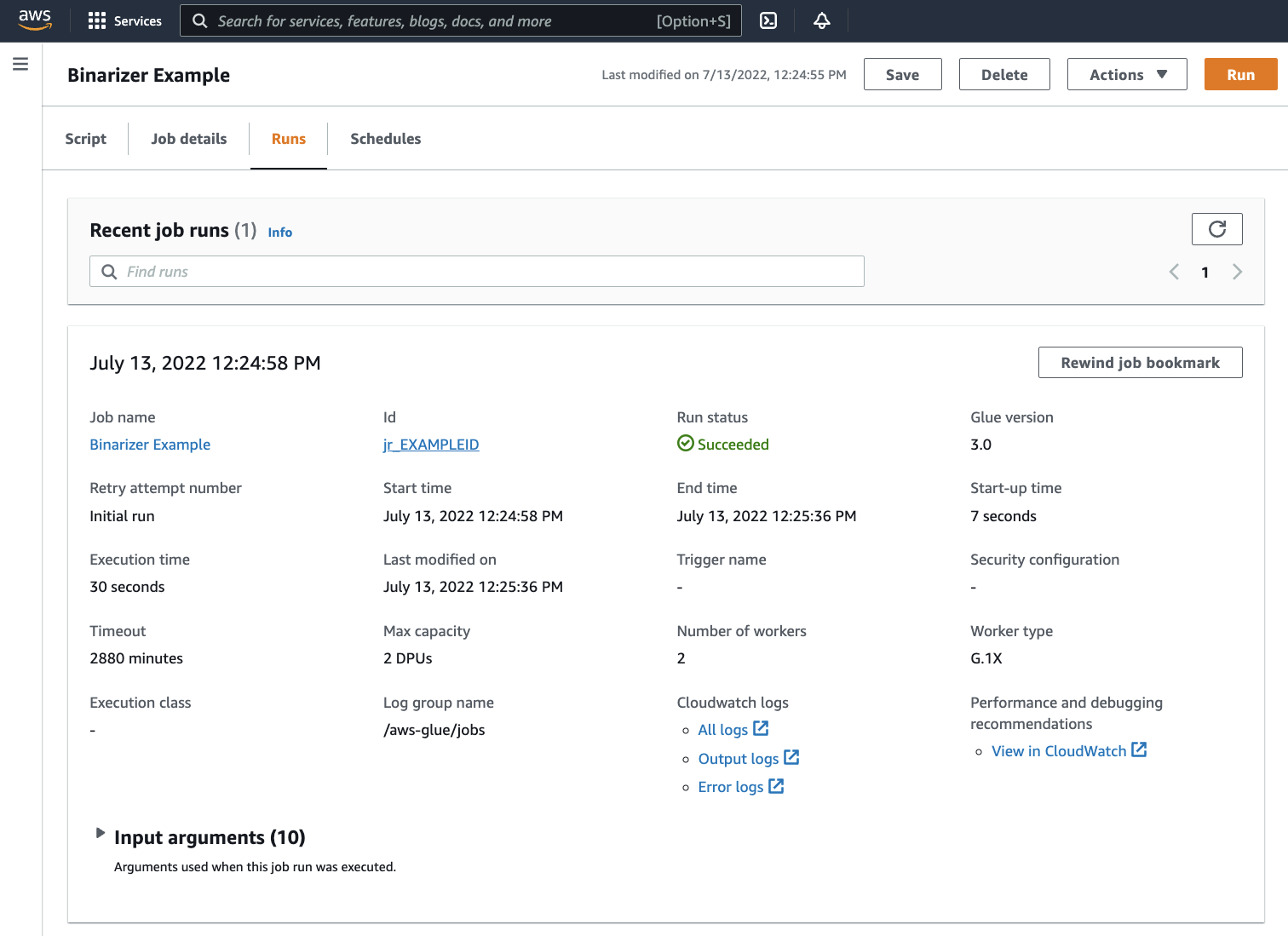
導覽至 Runs (執行) 索引標籤。您會看到與您任務執行對應的面板。請稍候幾分鐘,頁面應該會自動重新整理,並在 Run status (執行狀態) 下顯示 Succeeded (成功)。
-
您需要檢查輸出,以確認 Spark 指令碼按預期執行。此 Apache Spark 範例指令碼應該將字串寫入至輸出串流。您可以透過導覽至成功任務執行面板中 Cloudwatch logs (CloudWatch 日誌) 下的 Output logs (輸出日誌) 找到該資料。請注意,任務執行運行 ID (在 Id 標籤下產生的 id) 以
jr_開頭 。這將開啟 CloudWatch 主控台,設定為可視覺化預設 AWS Glue 日誌群組
/aws-glue/jobs/output的內容,篩選為任務執行 ID 的日誌串流內容。每個工作者都會產生日誌串流,並在 Log streams (日誌串流) 下顯示為資料列。每個工作者應執行請求的程式碼。您需要開啟所有日誌串流來找出正確的工作者。找到正確的工作者之後,您應該會看到指令碼的輸出,如下圖所示: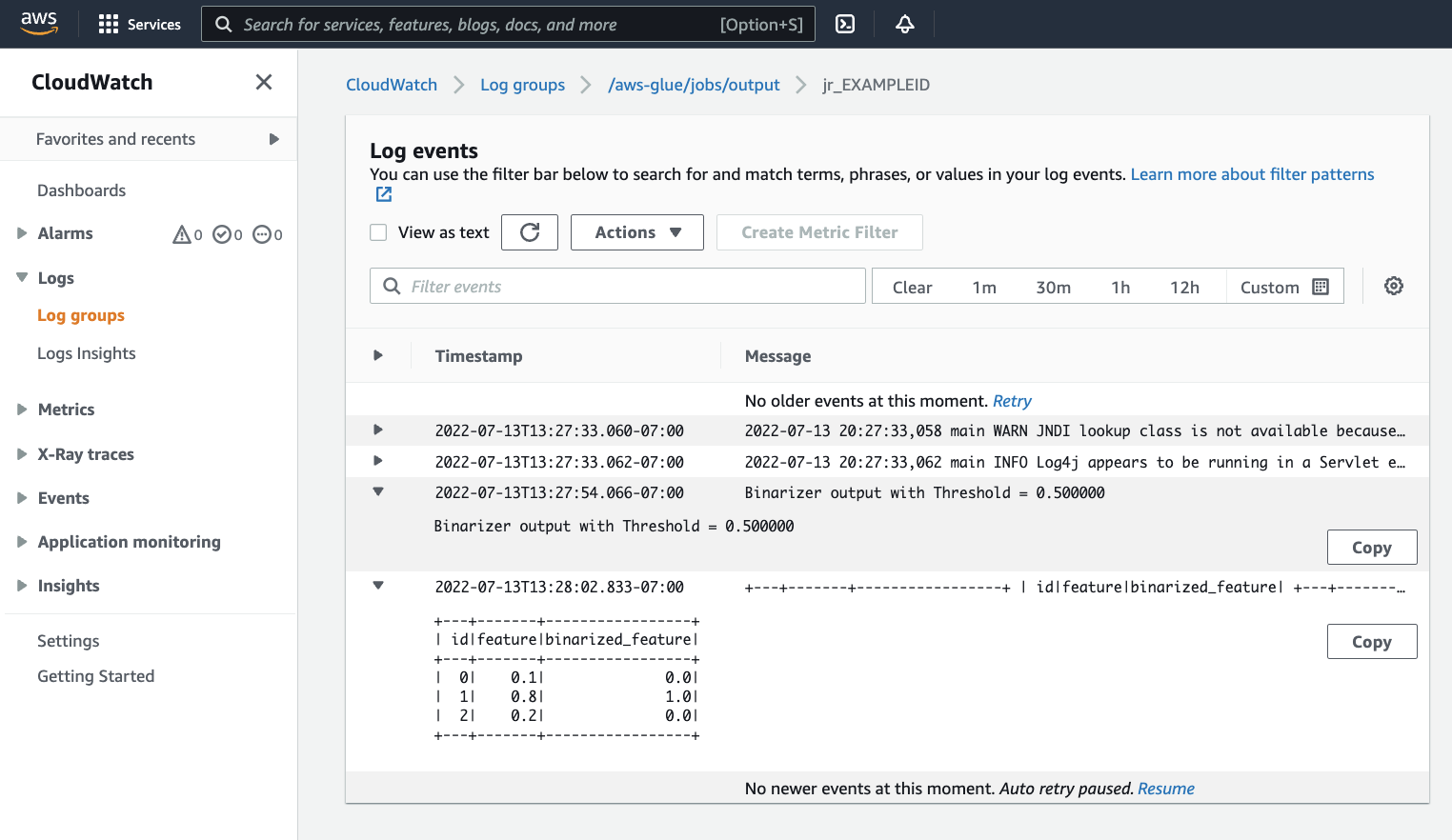
遷移 Spark 程式所需的常見程序
評估 Spark 版本支援
AWS Glue 發行版本決定了可用於 AWS Glue 任務的 Apache Spark 和 Python 版本。您可以在 AWS Glue 版本 找到我們的 AWS Glue 版本和其支援的內容。您可能需要更新 Spark 程式,以便與較新版本的 Spark 相容,才能存取部分 AWS Glue 功能。
包含第三方程式庫
許多現有的 Spark 程式將具有相依性 (在私有和公有成品上)。AWS Glue 支援 Scala 任務的 JAR 樣式相依性和 Python 任務的 Wheel 和來源純 Python 相依性。
Python - 如需 Python 相依性的相關資訊,請參閱 搭配 Glue 使用 Python AWS 程式庫
在 AWS Glue 環境中提供常見的 Python 相依性,包含經常請求的 Pandas--additional-python-modules。如需任務引數的相關資訊,請參閱 在 Glue AWS 任務中使用任務參數。
您可以為額外的 Python 相依性提供 --extra-py-files 任務引數。如果您要從 Spark 程式遷移任務,這個參數就是一個不錯的選擇,因為其在功能上等同於 PySpark 中的 --py-files 旗標,並且受到相同限制。如需有關 --extra-py-files 參數的詳細資訊,請參閱 包括 Python 檔案與 PySpark 原生功能
對於新任務,您可以使用 --additional-python-modules 任務引數來管理 Python 相依性。使用此引數可以獲得更完善的相依性管理體驗。此參數支援 Wheel 樣式相依性,包含具有與 Amazon Linux 2 相容的原生程式碼繫結的相依性。
Scala
您可以為額外的 Scala 相依性提供 --extra-jars 任務引數。相依性必須在 Amazon S3 中託管,且引數值應為以逗號分隔的 Amazon S3 路徑清單,並不含空格。先重新綁定相依性再託管和設定相依性,會讓您更輕鬆地管理組態。AWS GlueJAR 相依性包含可以從任何 JVM 語言產生的 Java 位元碼。您可以使用其他 JVM 語言 (例如 Java) 來撰寫自訂相依性。
管理資料來源憑證
現有的 Spark 程式可能帶有複雜或自訂組態,以從其資料來源中提取資料。AWS Glue 連線支援常見的資料來源身分驗證流程。如需有關 AWS Glue 連線的詳細資訊,請參閱 連線至資料。
AWS Glue 連線有助於將您的任務連線到各種類型的資料存放區,這展現在兩種主要方式上:透過對我們程式庫的方法呼叫以及在 AWS 主控台中設定 Additional network connection (其他網路連線)。您也可以從您的任務中呼叫 AWS SDK 以從連線擷取資訊。
方法呼叫 – AWS Glue 連線已與 AWS Glue 資料目錄緊密整合,可讓您彙整資料集的相關資訊,並反映在可用來與 AWS Glue 連線互動的方法。如果您有希望重複使用的現有身分驗證組態,對於 JDBC 連線,您可以透過 GlueContext 上的 extract_jdbc_conf 方法來存取 AWS Glue 連線組態。如需詳細資訊,請參閱 extract_jdbc_conf
主控台組態 – AWS Glue 任務使用關聯 AWS Glue 連線來設定連線至 Amazon VPC 子網路。如果您直接管理安全素材,可能需要在 AWS 主控台中提供 NETWORK 類型 Additional network connection (其他網路連線) 來設定路由。如需有關 AWS Glue 連線 API 的詳細資訊,請參閱 連線 API
如果您的 Spark 程式具有自訂或不常見的身分驗證流程,則可能需要以實作方式來管理安全素材。如果 AWS Glue 連線不適合使用,您可以安全地在 Secrets Manager 中託管安全素材,並透過 boto3 或 AWS SDK (在任務中會提供) 執行存取。
設定 Apache Spark
複雜的遷移通常會改變 Spark 組態,以因應其工作負載。現代版本的 Apache Spark 允許執行時間組態與 SparkSession 一起設定。AWS Glue3.0 以上的任務提供 SparkSession,可以修改以設定執行時間組態。Apache Spark 組態
設定自訂組態
遷移的 Spark 程式可以設計為採取自訂組態。AWS Glue 允許透過任務引數在任務和任務執行層級上設定組態。如需任務引數的相關資訊,請參閱 在 Glue AWS 任務中使用任務參數。您可以透過我們的程式庫來存取任務內容中的任務引數。AWS Glue 提供公用程式功能,可在任務上設定的引數與任務執行上設定的引數之間提供一致檢視。請在 Python 中參閱 使用 getResolvedOptions 存取參數,並在 Scala 中參閱 AWS Glue Scala GlueArgParser API。
遷移 Java 程式碼
如同 包含第三方程式庫 中所說明,您的相依性可以包含由 JVM 語言 (例如 Java 或 Scala) 產生的類別。您的相依性可以包含 main 方法。您可以使用相依性中的 main 方法來作為 AWS Glue Scala 任務的入口點。這可以讓您在 Java 中寫入 main 方法,或重複使用封裝至您自身程式庫標準的 main 方法。
若要使用來自相依性的 main 方法,請執行以下操作:清除提供預設 GlueApp 物件的編輯窗格內容。在相依性中提供完全合格的類別名稱,以作為具有金鑰 --class 的任務引數。然後,您應該能夠觸發任務執行。
您無法設定引數 AWS Glue 傳遞給 main 方法的順序或結構。如果您現有的程式碼需要讀取 AWS Glue 中設定的組態,這可能會導致與先前程式碼的不相容性。如果您使用 getResolvedOptions,也無法擁有能夠呼叫此方法的適當位置。考慮直接從 AWS Glue 產生的主要方法來叫用您的相依性。以下展示 AWS Glue ETL 指令碼範例。
import com.amazonaws.services.glue.util.GlueArgParser object GlueApp { def main(sysArgs: Array[String]) { val args = GlueArgParser.getResolvedOptions(sysArgs, Seq("JOB_NAME").toArray) // Invoke static method from JAR. Pass some sample arguments as a String[], one defined inline and one taken from the job arguments, using getResolvedOptions com.mycompany.myproject.MyClass.myStaticPublicMethod(Array("string parameter1", args("JOB_NAME"))) // Alternatively, invoke a non-static public method. (new com.mycompany.myproject.MyClass).someMethod() } }
