本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
教學課程:使用 建立機器學習轉換 AWS Glue
本教學會帶您使用 AWS Glue逐步進行建立及管理機器學習 (ML) 轉換的動作。使用本教學前,建議您先熟悉使用 AWS Glue 主控台新增爬取程式和任務,以及編輯指令碼。您也應熟悉在 Amazon Simple Storage Service (Amazon S3) 主控台上尋找及下載檔案。
在此範例中,您會建立一個 FindMatches 轉換來尋找相符的記錄、教導它如何識別相符及不相符的記錄,並在 AWS Glue 任務中使用它。AWS Glue 任務會寫入一個包含名為 match_id 額外資料行的新 Amazon S3 檔案。
本教學使用的來源資料是名為 dblp_acm_records.csv 的檔案。此檔案是可從原始 DBLP ACM 資料集dblp_acm_records.csv 檔案是一個逗點分隔值 (CSV) 檔案,其格式為不包含位元組順序標記 (BOM) 的 UTF-8 格式。
第二個檔案 dblp_acm_labels.csv 則是包含相符和不相符記錄的範例標記檔案,會做為本教學的一部分用來教導轉換。
主題
步驟 1:網路爬取來源資料
首先,請先爬取來源 Amazon S3 CSV 檔案來在 Data Catalog 中建立相對應的中繼資料資料表。
重要
若要指示爬蟲程式只為 CSV 檔案建立資料表,請將 CSV 來源資料存放在與其他檔案不同的 Amazon S3 資料夾中。
登入 AWS Management Console 並在 https://https://console.aws.amazon.com/glue/
開啟 AWS Glue 主控台。 -
在導覽窗格中,選擇 Crawlers (爬取程式)、Add crawler (新增爬取程式)。
-
遵循精靈來建立和執行名為
demo-crawl-dblp-acm的爬取程式,並輸出至demo-db-dblp-acm資料庫。執行精靈時,若資料庫尚未存在,請建立demo-db-dblp-acm資料庫。選擇 Amazon S3 包含路徑,以在目前 AWS 區域中取樣資料。例如,針對us-east-1,指向來源檔案的 Amazon S3 包含路徑為s3://ml-transforms-public-datasets-us-east-1/dblp-acm/records/dblp_acm_records.csv。若作業成功,爬取程式會建立
dblp_acm_records_csv資料表,其中包含下列資料行:id、標題 (title)、作者 (authors)、地點 (venue)、年份 (year) 及來源 (source)。
步驟 2:建立機器學習轉換
接著,請新增以爬取程式所建立資料來源資料表的結構描述為基礎,名為 demo-crawl-dblp-acm 的機器學習轉換。
-
在 AWS Glue 主控台的資料整合和 ETL 下的導覽窗格中,選擇資料分類工具 > 記錄比對,然後選擇新增轉換。請遵循精靈來建立包含下列屬性的
Find matches轉換。-
針對 Transform name (轉換名稱),請輸入
demo-xform-dblp-acm。這是轉換的名稱,用來尋找來源資料中的相符項目。 -
針對 IAM role (IAM 角色),請選擇擁有 Amazon S3 來源資料、標記檔案及 AWS Glue API 操作許可的 IAM 角色。如需詳細資訊,請參閱 AWS Glue 開發人員指南中的為 AWS Glue 建立 IAM 角色。
-
對於 Data source (資料來源),請選擇資料庫 demo-db-dblp-acm 中名為 dblp_acm_csv 的資料表。
-
針對 Primary key (主索引鍵),請選擇資料表的主索引鍵資料行,即 id。
-
在精靈中,選擇 Finish (完成) 並傳回 ML transforms (機器學習轉換) 清單。
步驟 3:教導您的機器學習轉換
接下來,您會使用教學範例標記檔案來教導您的機器學習轉換。
在其狀態變更為 Ready for use (已準備就緒可供使用) 之前,您無法在擷取、轉換和載入 (ETL) 作業中使用機器學習語言。若要讓您的轉換準備就緒,您必須提供相符和不相符記錄的範例,來教導它如何識別相符與不相符的記錄。若要教導您的轉換,您可以 Generate a label file (產生標記檔案) 及標籤,然後 Upload label file (上傳標記檔案)。在本教學中,您可以使用名為 dblp_acm_labels.csv 的範例標記檔案。如需標記程序的詳細資訊,請參閱 標記。
-
在 AWS Glue 主控台上的導覽窗格中,選擇記錄比對。
-
選擇
demo-xform-dblp-acm轉換,然後選擇 Action (動作)、Teach (教導)。遵循精靈來教導您的Find matches轉換。 在轉換屬性頁面上,選擇 I have labels (我擁有標籤)。選擇目前 AWS 區域中範例標籤檔案的 Amazon S3 路徑。例如,針對
us-east-1,請從 Amazon S3 路徑s3://ml-transforms-public-datasets-us-east-1/dblp-acm/labels/dblp_acm_labels.csv使用 overwrite (覆寫) 現有標籤選項來上傳所提供的標記檔案。標記檔案必須位於和 AWS Glue 主控台相同區域內的 Amazon S3 中。在您上傳標記檔案時,會在 AWS Glue 中啟動任務,來新增或覆寫用來教導轉換如何處理資料來源的標籤。
在精靈的最終頁面上,選擇 Finish (完成),然後傳回 ML transforms (機器學習轉換) 清單。
步驟 4:估計您機器學習轉換的品質
接著,您可以估計您機器學習轉換的品質。品質會取決於您已完成的標記數。如需估計品質的詳細資訊,請參閱 Estimate quality (估計品質)。
-
在 AWS Glue 主控台的資料整合和 ETL 下的導覽窗格中,選擇資料分類工具 > 記錄比對。
-
選擇
demo-xform-dblp-acm轉換,然後選擇 Estimate quality (估計品質) 標籤。此標籤會顯示目前轉換的品質估計 (若可用的話)。 選擇 Estimate quality (估計品質) 來啟動任務,估計轉換的品質。品質估計的正確性會以來源資料的標記為基礎。
導覽至 History (歷史記錄) 標籤。在此窗格中,會為轉換列出任務執行,包括 Estimating quality (估計品質) 任務。如需執行的詳細資訊,請選擇 Logs (日誌)。在完成時,檢查執行狀態是否是 Succeeded (成功)。
步驟 5:使用您的機器學習轉換新增和執行任務
在此步驟中,您會使用機器學習轉換來在 AWS Glue 中新增及執行任務。當 demo-xform-dblp-acm 轉換為 Ready for use (已準備就緒可供使用) 時,您便可以在 ETL 任務中使用它。
-
在 AWS Glue 主控台上,選擇導覽窗格中的 Jobs (任務)。
-
選擇 Add job (新增任務),並遵循精靈中的步驟,使用所產生的指令碼來建立 ETL Spark 任務。為您的轉換選擇下列屬性值:
-
針對 Name (名稱),選擇本教學中的範例任務 demo-etl-dblp-acm。
-
針對 IAM role (IAM 角色),選擇具備 Amazon S3 來源資料、標記檔案及 AWS Glue API 操作許可的 IAM 角色。如需詳細資訊,請參閱 AWS Glue 開發人員指南中的為 AWS Glue 建立 IAM 角色。
-
針對 ETL language (ETL 語言),選擇 Scala。這是 ETL 指令碼中的程式語言。
-
針對 Script file name (指令碼檔案名稱),選擇 demo-etl-dblp-acm。這是 Scala 指令碼的檔案名稱 (與任務名稱相同)。
-
針對 Data source (資料來源),選擇 dblp_acm_records_csv。您選擇的資料來源必須符合機器學習轉換資料來源結構描述。
-
針對 Transform type (轉換類型),請選擇 Find matching records (尋找相符記錄) 來使用機器學習轉換建立任務。
-
清除 Remove duplicate records (移除重複記錄)。由於寫入的輸出記錄包含新增的額外
match_id欄位,因此您不需要移除重複記錄。 -
針對 Transform (轉換),選擇任務使用的機器學習轉換 demo-xform-dblp-acm。
-
針對 Create tables in your data target (在您的資料目標中建立資料表),選擇使用下列屬性建立資料表:
-
資料存放區類型 —
Amazon S3 -
格式 –
CSV -
壓縮類型 —
None -
目標路徑 — 寫入任務輸出的 Amazon S3 路徑 (在目前的主控台 AWS 區域中)
-
-
-
選擇 Save job and edit script (儲存任務並編輯指令碼) 來顯示指令碼編輯器頁面。
-
編輯指令碼以新增陳述式,將指向 Target path (目標路徑) 的任務輸出寫入單一分割區。在執行
FindMatches轉換的陳述式後立即新增此陳述式。陳述式與以下內容相似。val single_partition = findmatches1.repartition(1)您必須修改
.writeDynamicFrame(findmatches1)陳述式,將輸出做為.writeDynamicFrame(single_partion)寫入。 -
在您編輯指令碼後,請選擇 Save (儲存)。修改後的指令碼看起來會與以下程式碼相似,但已根據您的環境進行自訂。
import com.amazonaws.services.glue.GlueContext import com.amazonaws.services.glue.errors.CallSite import com.amazonaws.services.glue.ml.FindMatches import com.amazonaws.services.glue.util.GlueArgParser import com.amazonaws.services.glue.util.Job import com.amazonaws.services.glue.util.JsonOptions import org.apache.spark.SparkContext import scala.collection.JavaConverters._ object GlueApp { def main(sysArgs: Array[String]) { val spark: SparkContext = new SparkContext() val glueContext: GlueContext = new GlueContext(spark) // @params: [JOB_NAME] val args = GlueArgParser.getResolvedOptions(sysArgs, Seq("JOB_NAME").toArray) Job.init(args("JOB_NAME"), glueContext, args.asJava) // @type: DataSource // @args: [database = "demo-db-dblp-acm", table_name = "dblp_acm_records_csv", transformation_ctx = "datasource0"] // @return: datasource0 // @inputs: [] val datasource0 = glueContext.getCatalogSource(database = "demo-db-dblp-acm", tableName = "dblp_acm_records_csv", redshiftTmpDir = "", transformationContext = "datasource0").getDynamicFrame() // @type: FindMatches // @args: [transformId = "tfm-123456789012", emitFusion = false, survivorComparisonField = "<primary_id>", transformation_ctx = "findmatches1"] // @return: findmatches1 // @inputs: [frame = datasource0] val findmatches1 = FindMatches.apply(frame = datasource0, transformId = "tfm-123456789012", transformationContext = "findmatches1", computeMatchConfidenceScores = true)// Repartition the previous DynamicFrame into a single partition. val single_partition = findmatches1.repartition(1)// @type: DataSink // @args: [connection_type = "s3", connection_options = {"path": "s3://aws-glue-ml-transforms-data/sal"}, format = "csv", transformation_ctx = "datasink2"] // @return: datasink2 // @inputs: [frame = findmatches1] val datasink2 = glueContext.getSinkWithFormat(connectionType = "s3", options = JsonOptions("""{"path": "s3://aws-glue-ml-transforms-data/sal"}"""), transformationContext = "datasink2", format = "csv").writeDynamicFrame(single_partition) Job.commit() } } 選擇 Run job (執行任務) 來啟動任務執行。在任務清單中檢查任務的狀態。當任務完成時,在 ML transform (ML 轉換)、History (歷史記錄) 索引標籤上,有一個新的 Run ID (執行 ID) 列已加入 ETL job (ETL 任務) 類型。
導覽至 Jobs (任務)、History (歷史記錄) 標籤。在這個窗格中會列出任務執行。如需執行的詳細資訊,請選擇 Logs (日誌)。在完成時,檢查執行狀態是否是 Succeeded (成功)。
步驟 6:驗證 Amazon S3 的輸出資料
在此步驟中,您可以在新增任務時所選擇的 Amazon S3 儲存貯體內檢查任務執行的輸出。您可以將輸出檔案下載到您的本機電腦,並驗證已成功識別相符的記錄。
開啟位於 https://console.aws.amazon.com/s3/
的 Amazon S3 主控台。 下載任務的目標輸出檔案
demo-etl-dblp-acm。在試算表應用程式 (您可能需要為檔案新增.csv副檔名,才能正常開啟) 中開啟檔案。下圖顯示 Microsoft Excel 中的輸出摘要。
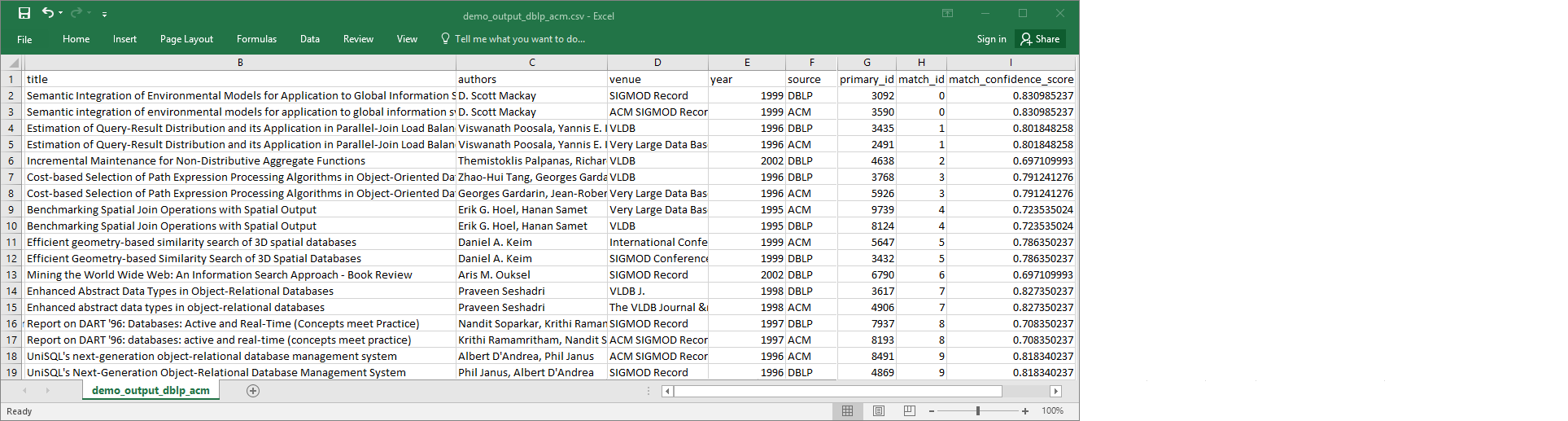
資料來源和目標檔案都有 4,911 筆記錄。但是,
Find matches轉換會新增另一個名為match_id的資料行,來識別輸出中的相符記錄。match_id相同的資料列會視為相符記錄。match_confidence_score為介於 0 至 1 之間的數字,用來估計Find matches找到之相符項目的品質。-
依據
match_id排序輸出檔案,來輕鬆查看哪些記錄是相符項目。比較其他資料行中的值,查看您是否同意Find matches轉換的結果。若您不同意其結果,您可以新增更多標籤來繼續教導轉換。您也可以依據其他欄位排序檔案 (例如
title),來查看標題相似的記錄是否擁有相同的match_id。
