本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
監控多個任務的進度
您可以同時描述多個 AWS Glue 任務,並監控它們之間的資料流程。這是一個常見的任務流程模式,且需要監控個別任務進度、資料處理後端紀錄、資料重新處理和任務書籤。
已分析的程式碼
在此任務流程中,您有兩個任務:輸入任務和輸出任務。輸入任務透過定期觸發排定每隔 30 分鐘執行。在每個輸入任務成功執行之後,即排定要執行的輸出任務。這些排定的任務皆由任務觸發器控制。

輸入任務:此任務從 Amazon Simple Storage Service (Amazon S3) 位置讀取的資料,會使用 ApplyMapping 轉換該任務,並將其寫入至暫存 Amazon S3 位置。以下程式碼是已分析的輸入任務程式碼:
datasource0 = glueContext.create_dynamic_frame.from_options(connection_type="s3", connection_options = {"paths": ["s3://input_path"], "useS3ListImplementation":True,"recurse":True}, format="json") applymapping1 = ApplyMapping.apply(frame = datasource0, mappings = [map_spec]) datasink2 = glueContext.write_dynamic_frame.from_options(frame = applymapping1, connection_type = "s3", connection_options = {"path": staging_path, "compression": "gzip"}, format = "json")
輸出任務:此任務從 Amazon S3 的暫存位置讀取輸入任務中的輸出,將其再次轉換並寫入至目的地:
datasource0 = glueContext.create_dynamic_frame.from_options(connection_type="s3", connection_options = {"paths": [staging_path], "useS3ListImplementation":True,"recurse":True}, format="json") applymapping1 = ApplyMapping.apply(frame = datasource0, mappings = [map_spec]) datasink2 = glueContext.write_dynamic_frame.from_options(frame = applymapping1, connection_type = "s3", connection_options = {"path": output_path}, format = "json")
在 AWS Glue 主控台上視覺化已分析的指標
在相同的輸出任務時間軸上,以下儀表板會將輸入任務的 Amazon S3 位元組寫入指標,加乘至 Amazon S3 位元組讀取指標。該時間軸顯示了輸入與輸出任務的不同任務執行。輸入任務 (紅色) 每 30 分鐘啟動一次。輸出任務 (褐色) 會於輸入任務完成時啟動,最大並行數量為 1。
在此範例中並未啟用任務書籤。在該指令碼程式碼中沒有使用轉換細節來啟用任務書籤。
任務歷史記錄:從下午 12 點開始,輸入和輸出任務會有多項執行,如 History (歷史記錄) 標籤中所示。
AWS Glue 主控台的輸入任務如下所示:

下列映像顯示了輸出任務:

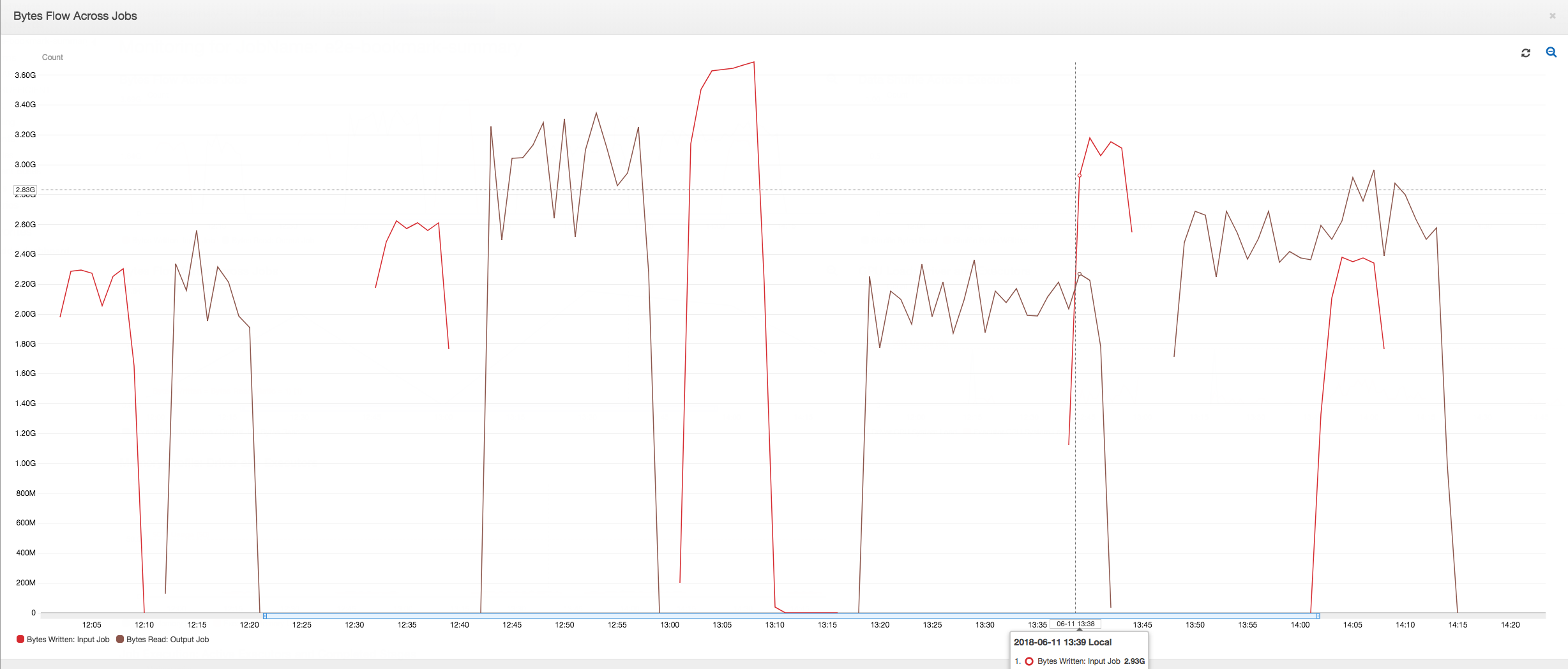
第一個任務執行:如下方的 Data Bytes Read and Written (資料位元組讀取和寫入圖形) 所示,在 12:00 和 12:30 之間的第一個輸入與輸出任務的任務執行,顯示了曲線下大致的相同區域。那些領域代表了輸入任務寫入的 Amazon S3 位元組,以及輸出任務讀取的 Amazon S3 位元組。此資料也由 Amazon S3 位元組寫入的比例所確認 (超過 30 分鐘的加總 - 輸入任務的任務觸發器頻率)。在下午 12 點開始的輸入任務執行比例資料點也是 1。
以下圖表顯示所有任務執行的資料流程比例:
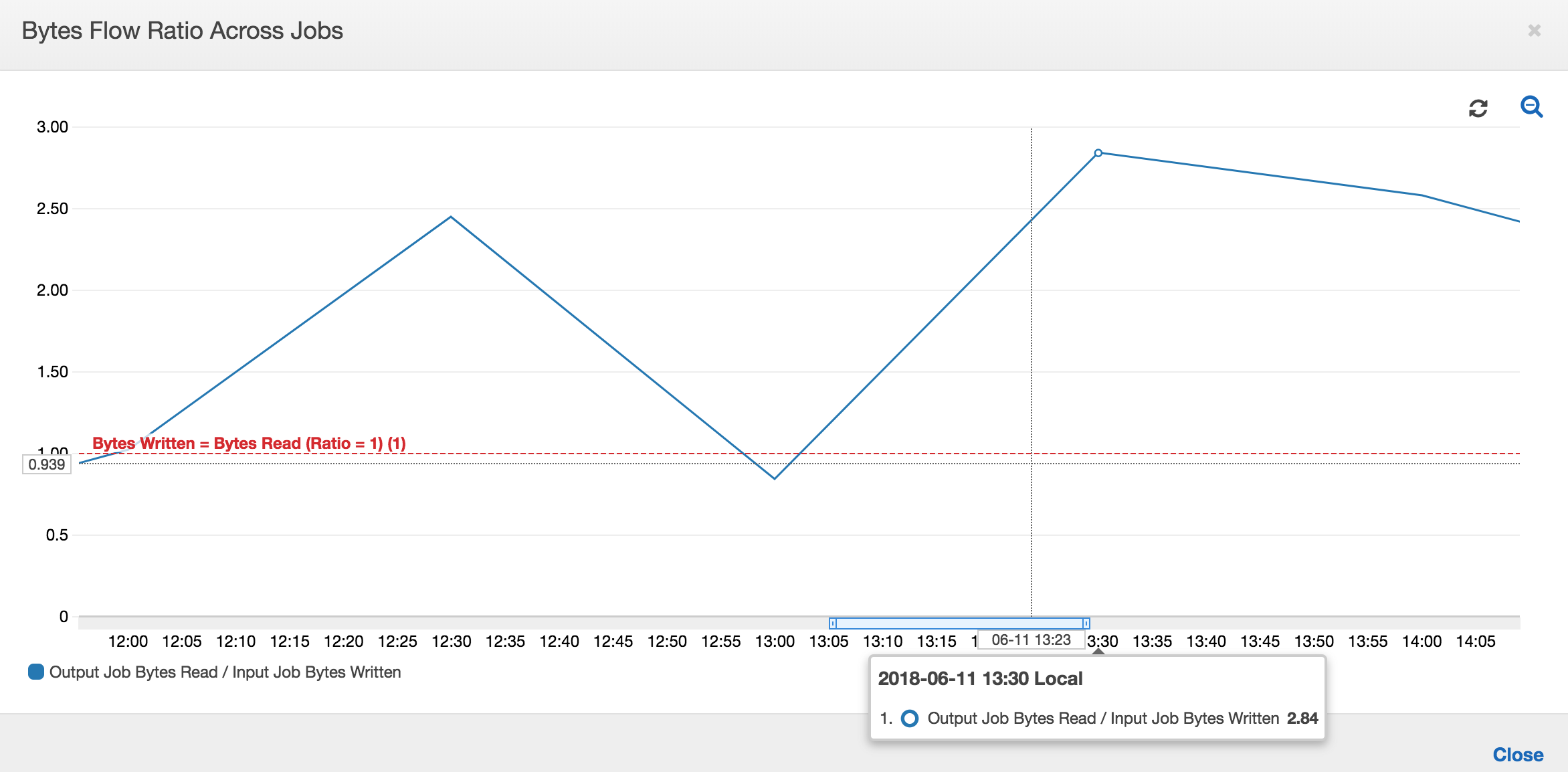
第二個任務執行:在第二個任務執行中,輸出任務讀取的位元數和輸入任務寫入的位元數之間有清楚的差異。(在輸出任務的兩個任務執行中比較曲線下的區域,或在輸入與輸出任務中的第二個執行中比較區域。) 讀取和寫入的位元組比例,顯示第二個範圍 (從 12:30 至 13:00) 的 30 分鐘內,輸出任務資料讀取約是輸入任務資料寫入的 2.5 倍。這是因為任務書籤並未啟用,故輸出任務重新處理了輸入任務的第一個任務執行的輸出。超過 1 的比率,說明有由輸出任務處理的額外資料後端紀錄。
第三個任務執行:輸入任務與寫入的位元組數相當的一致 (請參閱紅色曲線以下的區域)。不過,輸入任務第三個任務執行的執行時間超出預期 (請參閱紅色曲線的尾部)。因此,輸出任務的第三個任務執行會延遲開始。第三個任務執行僅在 13:00 到 13:30 之間剩餘的 30 分鐘內處理暫存位置中累積的一小部分資料。位元組流程的比例,顯示它僅會處理由輸入任務的第三個任務執行寫入資料的 0.83 (參見 13:00 時的比例)。
輸入和輸出任務的重疊:輸出任務的第四個任務執行依各排程在 13:30 開始,即輸出任務的第三個任務執行完成之前。這兩個任務執行間有部分重疊。不過,輸出任務的第三個任務執行約在 13:17 開始,它僅擷取 Amazon S3 暫存位置中列出的檔案。這包含了輸入任務的第一個任務執行的所有資料輸出。13:30 的實際比例為 2.75。從 13:30 至 14:00 間,輸出任務的第三個任務執行處理的寫入資料,是輸入任務的第四個任務執行的 2.75 倍。
如這些映像所示,輸出任務正在重新處理資料,這些資料位於輸入任務的所有優先任務暫存位置。因此,輸出任務的第四個任務執行時間最長,並與輸入任務的整個第五個任務執行重疊。
修正檔案處理
您應該確保輸出任務僅會處理尚未由輸出任務的前一任務執行處理過的檔案。若要執行此操作,請啟用任務書籤並在輸出任務中設定轉換內容,如下所示:
datasource0 = glueContext.create_dynamic_frame.from_options(connection_type="s3", connection_options = {"paths": [staging_path], "useS3ListImplementation":True,"recurse":True}, format="json", transformation_ctx = "bookmark_ctx")
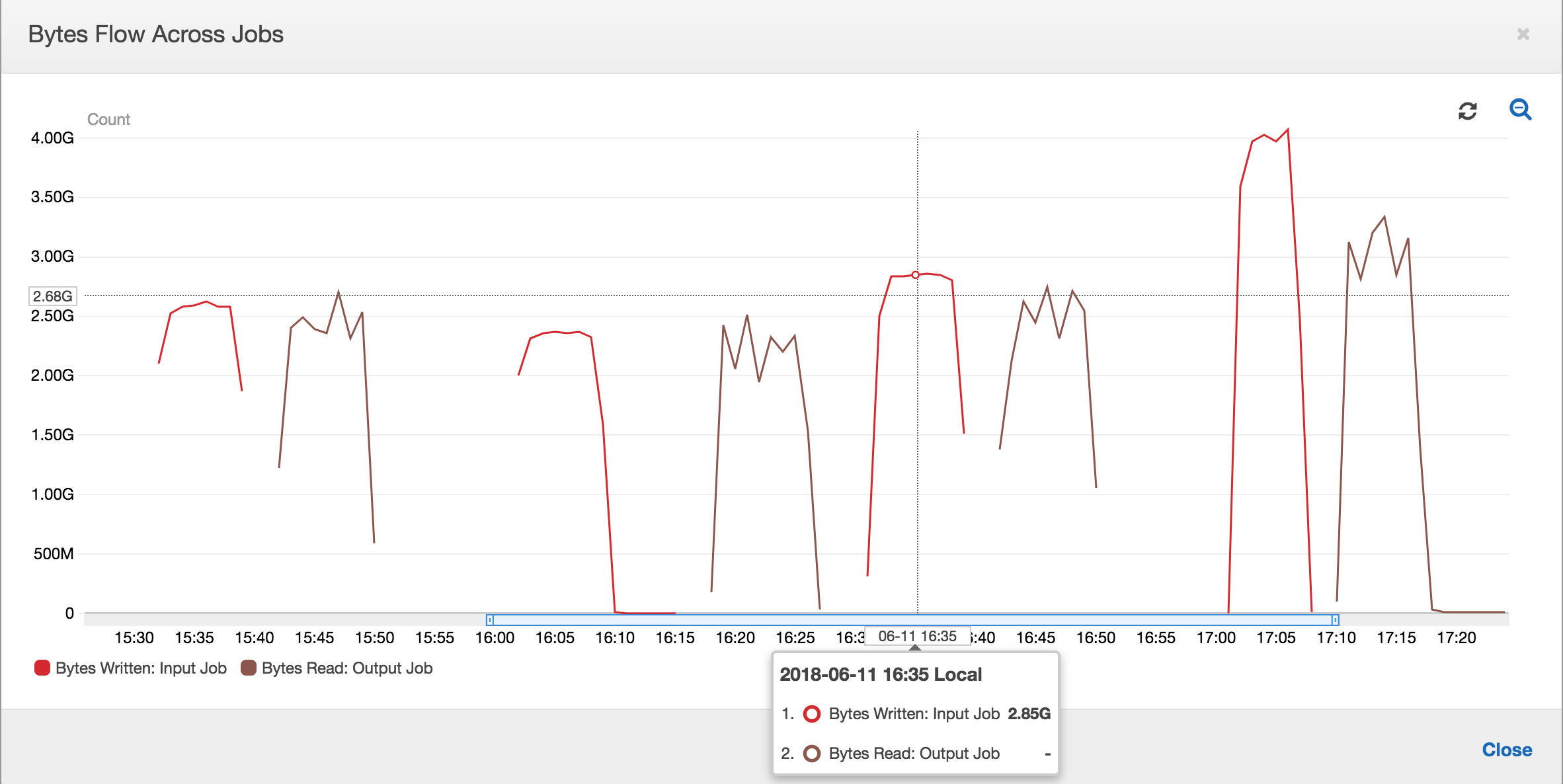
任務書籤啟用後,輸出任務將不會自輸入任務的所有先前任務執行中重新處理暫存位置裡的資料。下列映像顯示了資料的讀取和寫入,棕色曲線下的面積與紅色曲線相當一致且相似。
由於沒有額外的資料處理,位元組流程比例也會大致保持接近為 1。
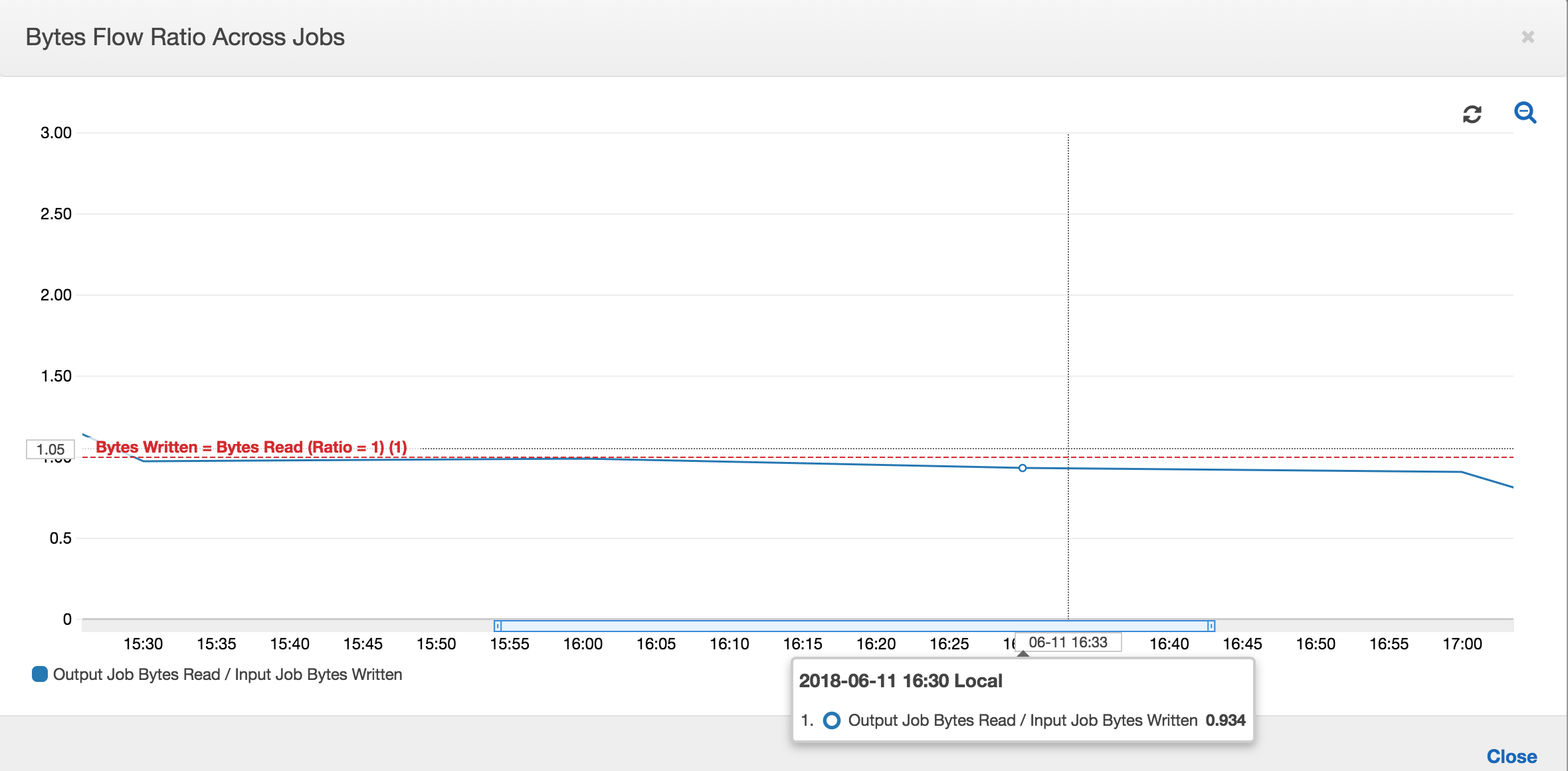
在下一個輸入任務執行開始將更多資料放入暫存位置之前,輸出任務的任務執行將開始並擷取暫存位置中的檔案。只要此操作持續執行,它僅會處理之前的輸入任務執行所擷取的檔案,且比例保持接近 1。
假設輸入任務花費的時間超過預期,於是,輸出任務將從兩個輸入任務執行中擷取暫存位置中的檔案。然後,該輸出任務執行的比例將高於 1。不過,以下輸出任務的任務執行,不會處理任何輸出任務之前的任務執行已處裡的檔案。
