本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
使用 AWS Glue 任務執行洞見進行監控
AWS Glue 任務執行洞見是 中的一項功能 AWS Glue ,可簡化 AWS Glue 任務的任務偵錯和最佳化。 AWS Glue 提供 Spark 使用者介面,以及用於監控 AWS Glue 任務的CloudWatch 日誌和指標。透過此功能,您可以取得 AWS Glue 任務執行的相關資訊:
失敗 AWS Glue 的任務指令碼行號。
在任務失敗之前,Spark 查詢計劃中最近執行的 Spark 動作。
與時間排序日誌串流中顯示的故障相關的 Spark 異常事件。
根本原因分析和修正問題的建議動作 (例如調校指令碼)。
常見的 Spark 事件 (與 Spark 動作相關的日誌訊息),其中包含解決根本原因的建議動作。
您可以使用 CloudWatch AWS Glue 任務日誌中的兩個新日誌串流,取得所有這些洞見。
要求
AWS Glue 任務執行洞見功能適用於 2.0、3.0、4.0 和 5.0 AWS Glue 版。您可以遵循現有任務的遷移指南,從較舊 AWS Glue 版本升級這些任務。
啟用任務的任務 AWS Glue ETL執行洞見
您可以透過 AWS Glue Studio 或 啟用任務執行洞見CLI。
AWS Glue Studio
透過 建立任務時 AWS Glue Studio,您可以在任務詳細資訊索引標籤下啟用或停用任務執行洞見。檢查是否已選取產生任務洞見方塊。

命令列
如果透過 建立任務CLI,您可以使用單一新任務參數開始任務執行:--enable-job-insights = true。
預設情況下,在 AWS Glue 連續記錄使用的相同預設日誌群組下建立任務執行見解日誌串流, 即 /aws-glue/jobs/logs-v2/。您可以使用相同的連續記錄引數集來設定自訂日誌群組名稱、日誌篩選條件和日誌群組組態。如需詳細資訊,請參閱啟用 AWS Glue 任務的持續記錄。
在 中存取任務執行洞見日誌串流 CloudWatch
啟用任務執行見解功能後,當任務執行失敗時,可能會建立兩個日誌串流。任務成功完成後,兩個串流均不會產生。
異常分析日誌串流:
<job-run-id>-job-insights-rca-driver。此串流提供下列資訊:造成失敗 AWS Glue 的任務指令碼行號。
Spark 查詢計劃 () 中最後執行的 Spark 動作DAG。
Spark 驅動程式和執行器中與異常相關的簡明時間排序事件。您可以從中找到詳細資訊,例如完整的錯誤訊息、失敗的 Spark 任務及其執行器 ID,這些資訊可協助您專注於特定執行器的日誌串流,以便在需要時進行更深入的調查。
基於規則的見解串流:
根本原因分析和關於如何修正錯誤的建議 (例如使用特定的任務參數以最佳化效能)。
作為根本原因分析基礎的相關 Spark 事件和建議的動作。
注意
僅當任何異常 Spark 事件可用於失敗的任務執行時,第一個串流才會存在;只有在見解可用於失敗的任務執行時,第二個串流才存在。例如,如果您的任務成功完成,則不會產生任何串流;如果任務失敗,但沒有可以與故障場景相符的服務定義規則,則僅產生第一個串流。
如果任務是從中建立 AWS Glue Studio,則任務執行詳細資訊索引標籤 (任務執行洞見) 下也會提供上述串流的連結,做為「簡潔和合併錯誤日誌」和「錯誤分析和指引」。
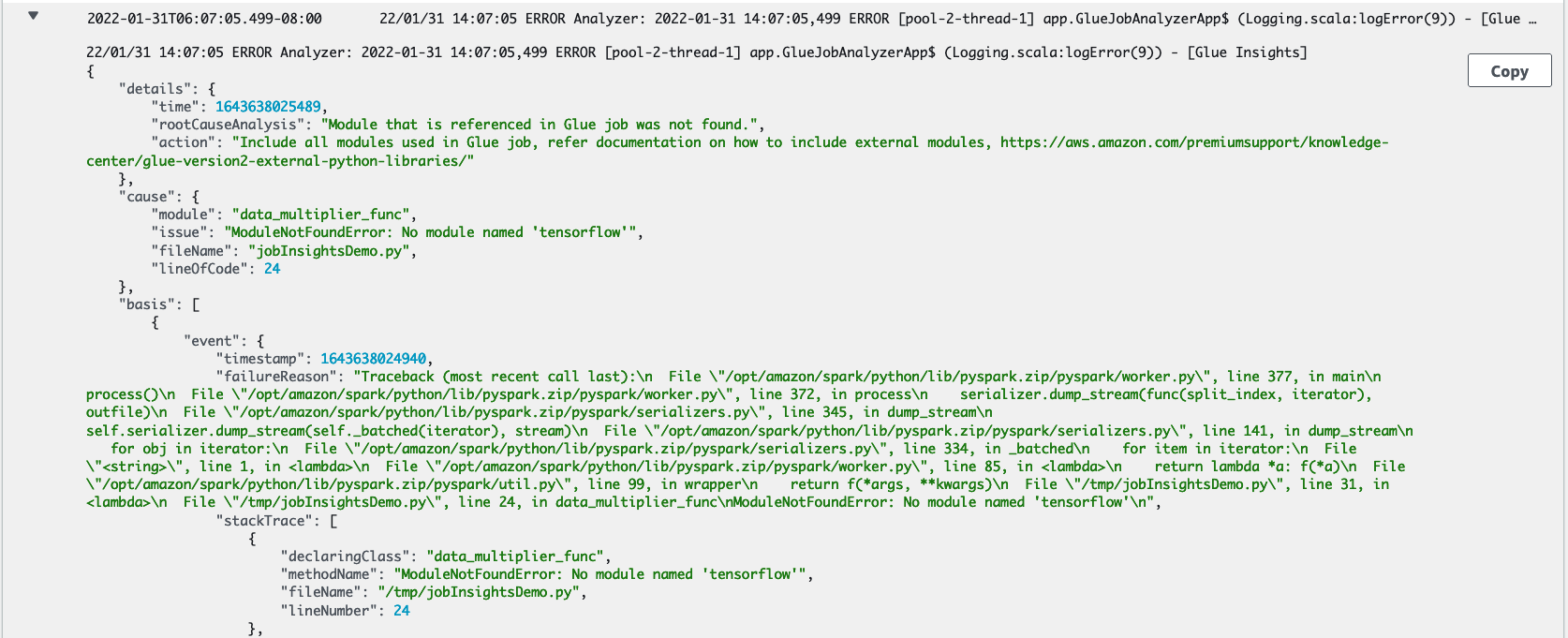
AWS Glue 任務執行洞見的範例
在本部分中,我們展示任務執行見解功能如何協助您解決失敗任務中問題的範例。在此範例中,使用者忘記在 AWS Glue 任務中匯入所需的模組 (張量流程),以分析和建置其資料的機器學習模型。
import sys from awsglue.transforms import * from awsglue.utils import getResolvedOptions from pyspark.context import SparkContext from awsglue.context import GlueContext from awsglue.job import Job from pyspark.sql.types import * from pyspark.sql.functions import udf,col args = getResolvedOptions(sys.argv, ['JOB_NAME']) sc = SparkContext() glueContext = GlueContext(sc) spark = glueContext.spark_session job = Job(glueContext) job.init(args['JOB_NAME'], args) data_set_1 = [1, 2, 3, 4] data_set_2 = [5, 6, 7, 8] scoresDf = spark.createDataFrame(data_set_1, IntegerType()) def data_multiplier_func(factor, data_vector): import tensorflow as tf with tf.compat.v1.Session() as sess: x1 = tf.constant(factor) x2 = tf.constant(data_vector) result = tf.multiply(x1, x2) return sess.run(result).tolist() data_multiplier_udf = udf(lambda x:data_multiplier_func(x, data_set_2), ArrayType(IntegerType(),False)) factoredDf = scoresDf.withColumn("final_value", data_multiplier_udf(col("value"))) print(factoredDf.collect())
如果沒有任務執行見解功能,當任務失敗時,您只會看到 Spark 擲回的訊息:
An error occurred while calling o111.collectToPython. Traceback (most recent call last):
該訊息含糊不清,並限制了您的偵錯體驗。在此情況下,此功能會在兩個 CloudWatch 日誌串流中為您提供其他洞見:
job-insights-rca-driver日誌串流:異常事件:此日誌串流提供與從 Spark 驅動程式和不同分佈式工作者收集的故障相關的 Spark 異常事件。這些事件可協助您了解例外狀況的時間順序傳播,因為故障的程式碼會跨 Spark 任務、執行器和跨 AWS Glue 工作者分佈的階段執行。
行號:此日誌串流標識第 21 行,該行叫用以匯入導致失敗的 Python 模組;它還標識第 24 行,其中叫用 Spark Action
collect(),作為指令碼中最後執行的一行。
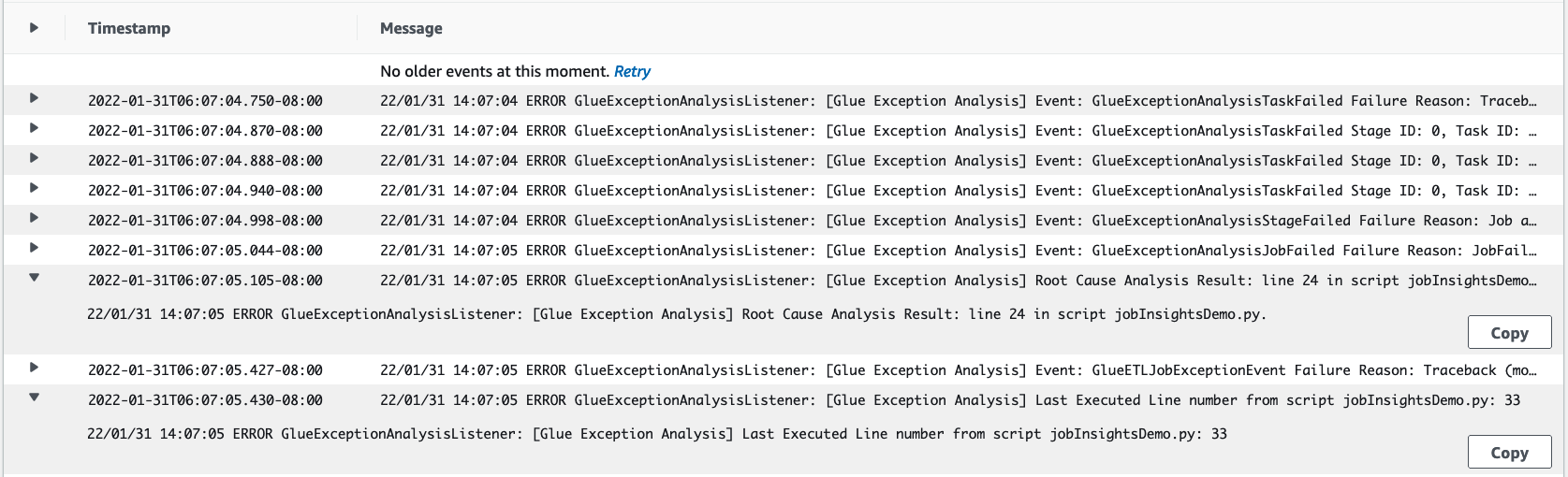
job-insights-rule-driver日誌串流:根本原因和建議:除了指令碼中故障的行號和上次執行的行號之外,此日誌串流會顯示根本原因分析和建議,讓您遵循 AWS Glue 文件並設定必要的任務參數,以便在 AWS Glue 任務中使用額外的 Python 模組。
基礎事件:此日誌串流還顯示了使用服務定義規則評估的 Spark 異常事件,以推斷根本原因並提供建議。