本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
整合 AWS Glue 結構描述登錄檔
這些章節描述與 的整合 AWS Glue 結構描述登錄檔。這些區段中的範例顯示AVRO資料格式的結構描述。如需更多範例,包括具有JSON資料格式的結構描述,請參閱中的整合測試和 ReadMe 資訊 AWS Glue 結構描述登錄檔開放原始碼儲存庫
主題
使用案例:將結構描述登錄檔連線至 Amazon MSK或 Apache Kafka
假設您正在將資料寫入 Apache Kafka 主題,並且您可以按照下列步驟開始使用。
建立具有至少一個主題的 Amazon Managed Streaming for Apache Kafka (Amazon MSK) 或 Apache Kafka 叢集。若要建立 Amazon MSK叢集,您可以使用 AWS Management Console。請遵循下列指示:Amazon Managed Streaming for Apache Kafka 開發人員指南 中的開始使用 MSK Amazon。
遵循上述的安裝 SerDe 程式庫步驟。
若要建立結構描述登錄檔、結構描述或結構描述版本,請依照這份文件的開始使用結構描述登錄一節指示進行。
啟動您的生產者和消費者,使用結構描述登錄檔來寫入和讀取 Amazon MSK或 Apache Kafka 主題的 / 或從中讀取記錄。範例生產者和消費者程式碼可從 Serde 程式庫的 ReadMe 檔案中
找到。生產者上的結構描述登錄檔程式庫會自動序列化記錄,並使用結構描述版本 ID 裝飾記錄。 如果已輸入此記錄的結構描述,或者如果開啟自動註冊,則結構描述將已在結構描述登錄檔中註冊。
消費者從 Amazon MSK或 Apache Kafka 主題中讀取,使用 AWS Glue 結構描述登錄檔程式庫會自動從結構描述登錄檔查詢結構描述。
使用案例:將 Amazon Kinesis Data Streams 與 整合 AWS Glue 結構描述登錄檔
此整合要求您擁有現有的 Amazon Kinesis 資料串流。如需詳細資訊,請參閱 Amazon Kinesis Data Streams 開發人員指南中的 Amazon Kinesis Data Streams 入門。
您可以透過兩種方式與 Kinesis 資料串流中的資料互動。
透過 Java 中的 Kinesis Producer Library (KPL) 和 Kinesis Client Library (KCL) 程式庫。不提供多語言支援。
透過 中APIs提供的
PutRecords、PutRecord和GetRecordsKinesis Data Streams AWS SDK for Java。
如果您目前使用 KPL/KCL 程式庫,建議您繼續使用該方法。有整合結構描述登錄檔的更新KCL和KPL版本,如範例所示。否則,您可以使用範例程式碼來利用 AWS Glue 如果KDSAPIs直接使用 ,則結構描述登錄檔。
結構描述登錄整合僅適用於 KPL v0.14.2 或更新版本,以及 v2KCL.3 或更新版本。結構描述登錄檔與JSON資料格式的整合適用於 KPL v0.14.8 或更新版本,以及 v2KCL.3.6 或更新版本。
使用 Kinesis SDK V2 與資料互動
本節說明使用 Kinesis SDK V2 與 Kinesis 互動
// Example JSON Record, you can construct a AVRO record also private static final JsonDataWithSchema record = JsonDataWithSchema.builder(schemaString, payloadString); private static final DataFormat dataFormat = DataFormat.JSON; //Configurations for Schema Registry GlueSchemaRegistryConfiguration gsrConfig = new GlueSchemaRegistryConfiguration("us-east-1"); GlueSchemaRegistrySerializer glueSchemaRegistrySerializer = new GlueSchemaRegistrySerializerImpl(awsCredentialsProvider, gsrConfig); GlueSchemaRegistryDataFormatSerializer dataFormatSerializer = new GlueSchemaRegistrySerializerFactory().getInstance(dataFormat, gsrConfig); Schema gsrSchema = new Schema(dataFormatSerializer.getSchemaDefinition(record), dataFormat.name(), "MySchema"); byte[] serializedBytes = dataFormatSerializer.serialize(record); byte[] gsrEncodedBytes = glueSchemaRegistrySerializer.encode(streamName, gsrSchema, serializedBytes); PutRecordRequest putRecordRequest = PutRecordRequest.builder() .streamName(streamName) .partitionKey("partitionKey") .data(SdkBytes.fromByteArray(gsrEncodedBytes)) .build(); shardId = kinesisClient.putRecord(putRecordRequest) .get() .shardId(); GlueSchemaRegistryDeserializer glueSchemaRegistryDeserializer = new GlueSchemaRegistryDeserializerImpl(awsCredentialsProvider, gsrConfig); GlueSchemaRegistryDataFormatDeserializer gsrDataFormatDeserializer = glueSchemaRegistryDeserializerFactory.getInstance(dataFormat, gsrConfig); GetShardIteratorRequest getShardIteratorRequest = GetShardIteratorRequest.builder() .streamName(streamName) .shardId(shardId) .shardIteratorType(ShardIteratorType.TRIM_HORIZON) .build(); String shardIterator = kinesisClient.getShardIterator(getShardIteratorRequest) .get() .shardIterator(); GetRecordsRequest getRecordRequest = GetRecordsRequest.builder() .shardIterator(shardIterator) .build(); GetRecordsResponse recordsResponse = kinesisClient.getRecords(getRecordRequest) .get(); List<Object> consumerRecords = new ArrayList<>(); List<Record> recordsFromKinesis = recordsResponse.records(); for (int i = 0; i < recordsFromKinesis.size(); i++) { byte[] consumedBytes = recordsFromKinesis.get(i) .data() .asByteArray(); Schema gsrSchema = glueSchemaRegistryDeserializer.getSchema(consumedBytes); Object decodedRecord = gsrDataFormatDeserializer.deserialize(ByteBuffer.wrap(consumedBytes), gsrSchema.getSchemaDefinition()); consumerRecords.add(decodedRecord); }
使用 KPL/KCL 程式庫與資料互動
本節說明使用 KPL/KCL 程式庫將 Kinesis Data Streams 與結構描述登錄檔整合。如需使用 KPL/ 的詳細資訊KCL,請參閱 Amazon Kinesis Data Streams 開發人員指南 中的使用 Amazon Kinesis 生產者程式庫開發生產者。 Amazon Kinesis
在 中設定結構描述登錄檔 KPL
定義 中編寫的資料、資料格式和結構描述名稱的結構描述定義 AWS Glue 結構描述登錄檔。
選用地設定
GlueSchemaRegistryConfiguration物件。將結構描述物件傳遞給
addUserRecord API。private static final String SCHEMA_DEFINITION = "{"namespace": "example.avro",\n" + " "type": "record",\n" + " "name": "User",\n" + " "fields": [\n" + " {"name": "name", "type": "string"},\n" + " {"name": "favorite_number", "type": ["int", "null"]},\n" + " {"name": "favorite_color", "type": ["string", "null"]}\n" + " ]\n" + "}"; KinesisProducerConfiguration config = new KinesisProducerConfiguration(); config.setRegion("us-west-1") //[Optional] configuration for Schema Registry. GlueSchemaRegistryConfiguration schemaRegistryConfig = new GlueSchemaRegistryConfiguration("us-west-1"); schemaRegistryConfig.setCompression(true); config.setGlueSchemaRegistryConfiguration(schemaRegistryConfig); ///Optional configuration ends. final KinesisProducer producer = new KinesisProducer(config); final ByteBuffer data = getDataToSend(); com.amazonaws.services.schemaregistry.common.Schema gsrSchema = new Schema(SCHEMA_DEFINITION, DataFormat.AVRO.toString(), "demoSchema"); ListenableFuture<UserRecordResult> f = producer.addUserRecord( config.getStreamName(), TIMESTAMP, Utils.randomExplicitHashKey(), data, gsrSchema); private static ByteBuffer getDataToSend() { org.apache.avro.Schema avroSchema = new org.apache.avro.Schema.Parser().parse(SCHEMA_DEFINITION); GenericRecord user = new GenericData.Record(avroSchema); user.put("name", "Emily"); user.put("favorite_number", 32); user.put("favorite_color", "green"); ByteArrayOutputStream outBytes = new ByteArrayOutputStream(); Encoder encoder = EncoderFactory.get().directBinaryEncoder(outBytes, null); new GenericDatumWriter<>(avroSchema).write(user, encoder); encoder.flush(); return ByteBuffer.wrap(outBytes.toByteArray()); }
設定 Kinesis client library
您將用 Java 開發 Kinesis Client Library 消費者。如需詳細資訊,請參閱 Amazon Kinesis Data Streams 開發人員指南中的以 Java 開發 Kinesis Client Library 消費者。
傳遞
GlueSchemaRegistryConfiguration物件,建立GlueSchemaRegistryDeserializer的執行個體。傳遞
GlueSchemaRegistryDeserializer至retrievalConfig.glueSchemaRegistryDeserializer。透過呼叫
kinesisClientRecord.getSchema()存取內送訊息的結構描述。GlueSchemaRegistryConfiguration schemaRegistryConfig = new GlueSchemaRegistryConfiguration(this.region.toString()); GlueSchemaRegistryDeserializer glueSchemaRegistryDeserializer = new GlueSchemaRegistryDeserializerImpl(DefaultCredentialsProvider.builder().build(), schemaRegistryConfig); RetrievalConfig retrievalConfig = configsBuilder.retrievalConfig().retrievalSpecificConfig(new PollingConfig(streamName, kinesisClient)); retrievalConfig.glueSchemaRegistryDeserializer(glueSchemaRegistryDeserializer); Scheduler scheduler = new Scheduler( configsBuilder.checkpointConfig(), configsBuilder.coordinatorConfig(), configsBuilder.leaseManagementConfig(), configsBuilder.lifecycleConfig(), configsBuilder.metricsConfig(), configsBuilder.processorConfig(), retrievalConfig ); public void processRecords(ProcessRecordsInput processRecordsInput) { MDC.put(SHARD_ID_MDC_KEY, shardId); try { log.info("Processing {} record(s)", processRecordsInput.records().size()); processRecordsInput.records() .forEach( r -> log.info("Processed record pk: {} -- Seq: {} : data {} with schema: {}", r.partitionKey(), r.sequenceNumber(), recordToAvroObj(r).toString(), r.getSchema())); } catch (Throwable t) { log.error("Caught throwable while processing records. Aborting."); Runtime.getRuntime().halt(1); } finally { MDC.remove(SHARD_ID_MDC_KEY); } } private GenericRecord recordToAvroObj(KinesisClientRecord r) { byte[] data = new byte[r.data().remaining()]; r.data().get(data, 0, data.length); org.apache.avro.Schema schema = new org.apache.avro.Schema.Parser().parse(r.schema().getSchemaDefinition()); DatumReader datumReader = new GenericDatumReader<>(schema); BinaryDecoder binaryDecoder = DecoderFactory.get().binaryDecoder(data, 0, data.length, null); return (GenericRecord) datumReader.read(null, binaryDecoder); }
使用 Kinesis Data Streams 與資料互動 APIs
本節說明使用 Kinesis Data Streams 將 Kinesis Data Streams 與結構描述登錄檔整合APIs。
更新這些 Maven 相依性:
<dependencyManagement> <dependencies> <dependency> <groupId>com.amazonaws</groupId> <artifactId>aws-java-sdk-bom</artifactId> <version>1.11.884</version> <type>pom</type> <scope>import</scope> </dependency> </dependencies> </dependencyManagement> <dependencies> <dependency> <groupId>com.amazonaws</groupId> <artifactId>aws-java-sdk-kinesis</artifactId> </dependency> <dependency> <groupId>software.amazon.glue</groupId> <artifactId>schema-registry-serde</artifactId> <version>1.1.5</version> </dependency> <dependency> <groupId>com.fasterxml.jackson.dataformat</groupId> <artifactId>jackson-dataformat-cbor</artifactId> <version>2.11.3</version> </dependency> </dependencies>在生產者中,使用 Kinesis Data Streams
PutRecordAPI中的PutRecords或 新增結構描述標頭資訊。//The following lines add a Schema Header to the record com.amazonaws.services.schemaregistry.common.Schema awsSchema = new com.amazonaws.services.schemaregistry.common.Schema(schemaDefinition, DataFormat.AVRO.name(), schemaName); GlueSchemaRegistrySerializerImpl glueSchemaRegistrySerializer = new GlueSchemaRegistrySerializerImpl(DefaultCredentialsProvider.builder().build(), new GlueSchemaRegistryConfiguration(getConfigs())); byte[] recordWithSchemaHeader = glueSchemaRegistrySerializer.encode(streamName, awsSchema, recordAsBytes);在生產者中,使用
PutRecords或PutRecordAPI 將記錄放入資料串流。在消費者中,從標頭移除結構描述記錄,並序列化 Avro 結構描述記錄。
//The following lines remove Schema Header from record GlueSchemaRegistryDeserializerImpl glueSchemaRegistryDeserializer = new GlueSchemaRegistryDeserializerImpl(DefaultCredentialsProvider.builder().build(), getConfigs()); byte[] recordWithSchemaHeaderBytes = new byte[recordWithSchemaHeader.remaining()]; recordWithSchemaHeader.get(recordWithSchemaHeaderBytes, 0, recordWithSchemaHeaderBytes.length); com.amazonaws.services.schemaregistry.common.Schema awsSchema = glueSchemaRegistryDeserializer.getSchema(recordWithSchemaHeaderBytes); byte[] record = glueSchemaRegistryDeserializer.getData(recordWithSchemaHeaderBytes); //The following lines serialize an AVRO schema record if (DataFormat.AVRO.name().equals(awsSchema.getDataFormat())) { Schema avroSchema = new org.apache.avro.Schema.Parser().parse(awsSchema.getSchemaDefinition()); Object genericRecord = convertBytesToRecord(avroSchema, record); System.out.println(genericRecord); }
使用 Kinesis Data Streams 與資料互動 APIs
以下是使用 PutRecords和 GetRecords 的範例程式碼APIs。
//Full sample code import com.amazonaws.services.schemaregistry.deserializers.GlueSchemaRegistryDeserializerImpl; import com.amazonaws.services.schemaregistry.serializers.GlueSchemaRegistrySerializerImpl; import com.amazonaws.services.schemaregistry.utils.AVROUtils; import com.amazonaws.services.schemaregistry.utils.AWSSchemaRegistryConstants; import org.apache.avro.Schema; import org.apache.avro.generic.GenericData; import org.apache.avro.generic.GenericDatumReader; import org.apache.avro.generic.GenericDatumWriter; import org.apache.avro.generic.GenericRecord; import org.apache.avro.io.Decoder; import org.apache.avro.io.DecoderFactory; import org.apache.avro.io.Encoder; import org.apache.avro.io.EncoderFactory; import software.amazon.awssdk.auth.credentials.DefaultCredentialsProvider; import software.amazon.awssdk.services.glue.model.DataFormat; import java.io.ByteArrayOutputStream; import java.io.File; import java.io.IOException; import java.nio.ByteBuffer; import java.util.Collections; import java.util.HashMap; import java.util.Map; public class PutAndGetExampleWithEncodedData { static final String regionName = "us-east-2"; static final String streamName = "testStream1"; static final String schemaName = "User-Topic"; static final String AVRO_USER_SCHEMA_FILE = "src/main/resources/user.avsc"; KinesisApi kinesisApi = new KinesisApi(); void runSampleForPutRecord() throws IOException { Object testRecord = getTestRecord(); byte[] recordAsBytes = convertRecordToBytes(testRecord); String schemaDefinition = AVROUtils.getInstance().getSchemaDefinition(testRecord); //The following lines add a Schema Header to a record com.amazonaws.services.schemaregistry.common.Schema awsSchema = new com.amazonaws.services.schemaregistry.common.Schema(schemaDefinition, DataFormat.AVRO.name(), schemaName); GlueSchemaRegistrySerializerImpl glueSchemaRegistrySerializer = new GlueSchemaRegistrySerializerImpl(DefaultCredentialsProvider.builder().build(), new GlueSchemaRegistryConfiguration(regionName)); byte[] recordWithSchemaHeader = glueSchemaRegistrySerializer.encode(streamName, awsSchema, recordAsBytes); //Use PutRecords api to pass a list of records kinesisApi.putRecords(Collections.singletonList(recordWithSchemaHeader), streamName, regionName); //OR //Use PutRecord api to pass single record //kinesisApi.putRecord(recordWithSchemaHeader, streamName, regionName); } byte[] runSampleForGetRecord() throws IOException { ByteBuffer recordWithSchemaHeader = kinesisApi.getRecords(streamName, regionName); //The following lines remove the schema registry header GlueSchemaRegistryDeserializerImpl glueSchemaRegistryDeserializer = new GlueSchemaRegistryDeserializerImpl(DefaultCredentialsProvider.builder().build(), new GlueSchemaRegistryConfiguration(regionName)); byte[] recordWithSchemaHeaderBytes = new byte[recordWithSchemaHeader.remaining()]; recordWithSchemaHeader.get(recordWithSchemaHeaderBytes, 0, recordWithSchemaHeaderBytes.length); com.amazonaws.services.schemaregistry.common.Schema awsSchema = glueSchemaRegistryDeserializer.getSchema(recordWithSchemaHeaderBytes); byte[] record = glueSchemaRegistryDeserializer.getData(recordWithSchemaHeaderBytes); //The following lines serialize an AVRO schema record if (DataFormat.AVRO.name().equals(awsSchema.getDataFormat())) { Schema avroSchema = new org.apache.avro.Schema.Parser().parse(awsSchema.getSchemaDefinition()); Object genericRecord = convertBytesToRecord(avroSchema, record); System.out.println(genericRecord); } return record; } private byte[] convertRecordToBytes(final Object record) throws IOException { ByteArrayOutputStream recordAsBytes = new ByteArrayOutputStream(); Encoder encoder = EncoderFactory.get().directBinaryEncoder(recordAsBytes, null); GenericDatumWriter datumWriter = new GenericDatumWriter<>(AVROUtils.getInstance().getSchema(record)); datumWriter.write(record, encoder); encoder.flush(); return recordAsBytes.toByteArray(); } private GenericRecord convertBytesToRecord(Schema avroSchema, byte[] record) throws IOException { final GenericDatumReader<GenericRecord> datumReader = new GenericDatumReader<>(avroSchema); Decoder decoder = DecoderFactory.get().binaryDecoder(record, null); GenericRecord genericRecord = datumReader.read(null, decoder); return genericRecord; } private Map<String, String> getMetadata() { Map<String, String> metadata = new HashMap<>(); metadata.put("event-source-1", "topic1"); metadata.put("event-source-2", "topic2"); metadata.put("event-source-3", "topic3"); metadata.put("event-source-4", "topic4"); metadata.put("event-source-5", "topic5"); return metadata; } private GlueSchemaRegistryConfiguration getConfigs() { GlueSchemaRegistryConfiguration configs = new GlueSchemaRegistryConfiguration(regionName); configs.setSchemaName(schemaName); configs.setAutoRegistration(true); configs.setMetadata(getMetadata()); return configs; } private Object getTestRecord() throws IOException { GenericRecord genericRecord; Schema.Parser parser = new Schema.Parser(); Schema avroSchema = parser.parse(new File(AVRO_USER_SCHEMA_FILE)); genericRecord = new GenericData.Record(avroSchema); genericRecord.put("name", "testName"); genericRecord.put("favorite_number", 99); genericRecord.put("favorite_color", "red"); return genericRecord; } }
使用案例:Amazon Managed Service for Apache Flink
Apache Flink 是一個流行的開源架構和分散式處理引擎,用於對未限制和有限制資料串流進行狀態計算。Amazon Managed Service for Apache Flink 是一項完全受管 AWS 的服務,可讓您建置和管理 Apache Flink 應用程式,以處理串流資料。
開源 Apache Flink 提供一些來源和接收器。例如,預先定義的資料來源包括從檔案、目錄和通訊端讀取,以及從集合和迭代器擷取資料。Apache Flink DataStream Connectors 為 Apache Flink 提供程式碼,以與各種第三方系統連接,例如來源和/或接收器的 Apache Kafka 或 Kinesis。
如需詳細資訊,請參閱 Amazon Kinesis Data Analytics 開發人員指南。
Apache Flink Kafka 連接器
Apache Flink 提供 Apache Kafka 資料串流連接器,用於使用恰好一次的保證從 Kafka 主題讀取資料以及寫入資料至 Kafka 主題。Flink 的 Kafka 消費者 FlinkKafkaConsumer 提供從一個或多個 Kafka 主題的讀取存取權。Apache Flink 的 Kafka 生產者 FlinkKafkaProducer 允許寫入記錄串流到一個或多個 Kafka 主題。如需詳細資訊,請參閱 Apache Kafka 連接器
Apache Flink Kinesis 串流連接器
Kinesis Data Streams 連接器可存取 Amazon Kinesis Data Streams。FlinkKinesisConsumer 是完全一次性的平行串流資料來源,可訂閱相同 AWS 服務區域內的多個 Kinesis 串流,並在任務執行時透明地處理串流的重新共用。消費者的每個子工作都負責從多個 Kinesis 分片擷取資料記錄。每個子工作擷取的碎片數量將隨著碎片關閉並由 Kinesis 建立而改變。FlinkKinesisProducer 使用 Kinesis Producer Library (KPL) 將來自 Apache Flink 串流的資料放入 Kinesis 串流。如需詳細資訊,請參閱 Amazon Kinesis Streams Connector
如需詳細資訊,請參閱 AWS Glue 結構描述 Github 儲存庫
與 Apache Flink 整合
結構描述登錄檔提供的 SerDes 程式庫與 Apache Flink 整合。若要使用 Apache Flink,您需要實作稱為 GlueSchemaRegistryAvroSerializationSchema 和 GlueSchemaRegistryAvroDeserializationSchema 的 SerializationSchemaDeserializationSchema
新增 AWS Glue Apache Flink 應用程式的結構描述登錄檔相依性
將整合相依性設定為 AWS Glue Apache Flink 應用程式中的結構描述登錄檔:
將相依性新增到
pom.xml檔案。<dependency> <groupId>software.amazon.glue</groupId> <artifactId>schema-registry-flink-serde</artifactId> <version>1.0.0</version> </dependency>
將 Kafka 或 Amazon MSK與 Apache Flink 整合
您可以使用 Managed Service for Apache Flink,搭配 Kafka 作為來源或搭配 Kafka 作為接收器。
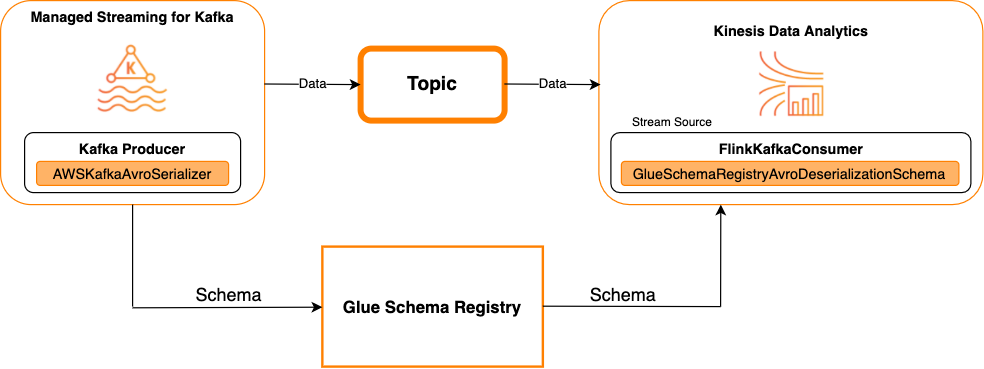
Kafka 作為來源
下圖顯示將 Kinesis Data Streams 與 Managed Service for Apache Flink 整合,並將 Kafka 作為來源。
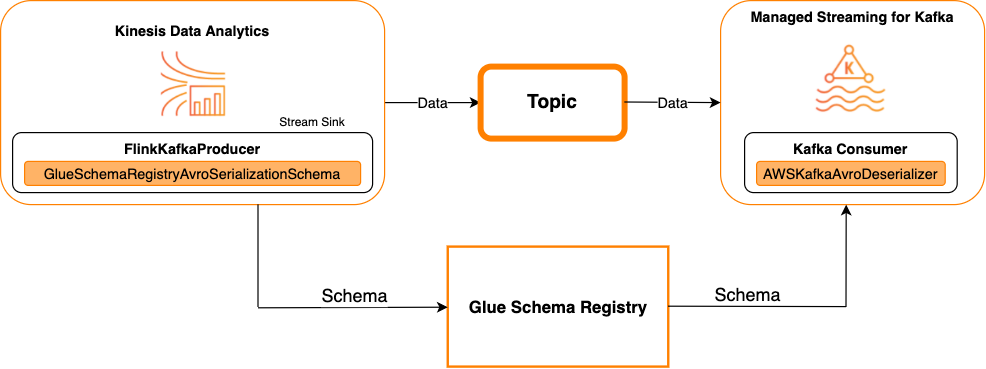
Kafka 做為接收器
下圖顯示將 Kinesis Data Streams 與 Managed Service for Apache Flink 整合,並將 Kafka 作為接收器。
若要將 Kafka (或 Amazon MSK) 與 Managed Service for Apache Flink for Apache Flink 整合,並將 Kafka 作為來源或 Kafka 作為接收器,請進行下列程式碼變更。將粗體程式碼區塊新增到類似區段中的各自程式碼中。
如果 Kafka 是來源,請使用還原序列化程式程式碼 (區塊 2)。如果 Kafka 是接收器,請使用序列化程式程式碼 (區塊 3)。
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); String topic = "topic"; Properties properties = new Properties(); properties.setProperty("bootstrap.servers", "localhost:9092"); properties.setProperty("group.id", "test"); // block 1 Map<String, Object> configs = new HashMap<>(); configs.put(AWSSchemaRegistryConstants.AWS_REGION, "aws-region"); configs.put(AWSSchemaRegistryConstants.SCHEMA_AUTO_REGISTRATION_SETTING, true); configs.put(AWSSchemaRegistryConstants.AVRO_RECORD_TYPE, AvroRecordType.GENERIC_RECORD.getName()); FlinkKafkaConsumer<GenericRecord> consumer = new FlinkKafkaConsumer<>( topic, // block 2 GlueSchemaRegistryAvroDeserializationSchema.forGeneric(schema, configs), properties); FlinkKafkaProducer<GenericRecord> producer = new FlinkKafkaProducer<>( topic, // block 3 GlueSchemaRegistryAvroSerializationSchema.forGeneric(schema, topic, configs), properties); DataStream<GenericRecord> stream = env.addSource(consumer); stream.addSink(producer); env.execute();
將 Kinesis Data Streams 與 Apache Flink 整合
您可以使用 Managed Service for Apache Flink,搭配 Kinesis Data Streams 作為來源或接收器。
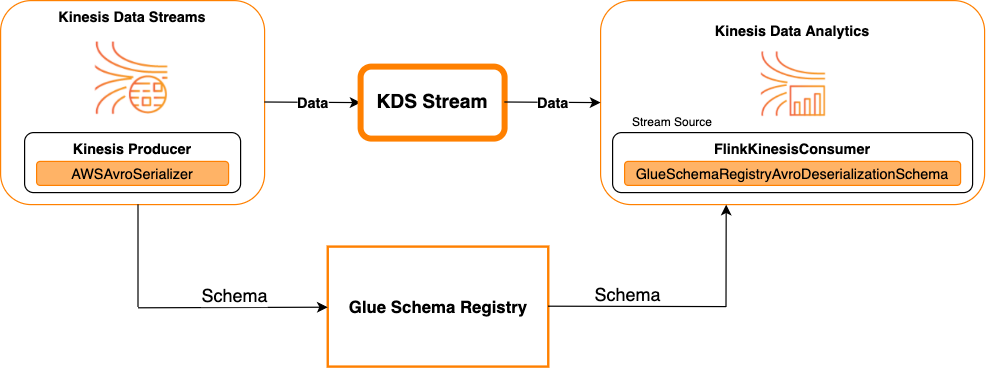
Kinesis Data Streams 做為來源
下圖顯示將 Kinesis Data Streams 與 Managed Service for Apache Flink 整合,並將 Kinesis Data Streams 作為來源。
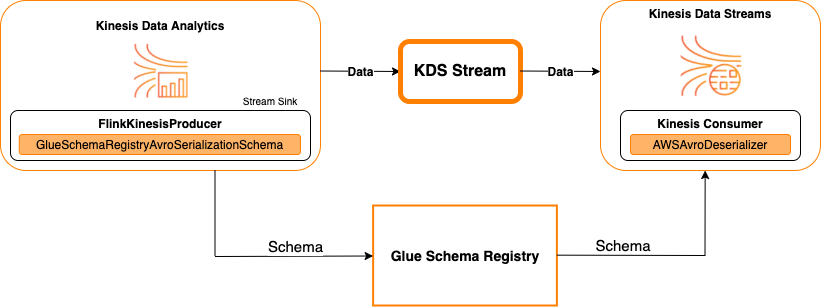
Kinesis Data Streams 做為接收器
下圖顯示將 Kinesis Data Streams 與 Managed Service for Apache Flink 整合,並將 Kinesis Data Streams 作為接收器。
若要將 Kinesis Data Streams 與 Managed Service for Apache Flink 整合,並將 Kinesis Data Streams 作為來源或將 Kinesis Data Streams 作為接收器,請對程式碼進行下列變更。將粗體程式碼區塊新增到類似區段中的各自程式碼中。
如果 Kinesis Data Streams 是來源,請使用還原序列化程式程式碼 (區塊 2)。如果 Kinesis Data Streams 是接收器,請使用序列化程式程式碼 (區塊 3)。
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); String streamName = "stream"; Properties consumerConfig = new Properties(); consumerConfig.put(AWSConfigConstants.AWS_REGION, "aws-region"); consumerConfig.put(AWSConfigConstants.AWS_ACCESS_KEY_ID, "aws_access_key_id"); consumerConfig.put(AWSConfigConstants.AWS_SECRET_ACCESS_KEY, "aws_secret_access_key"); consumerConfig.put(ConsumerConfigConstants.STREAM_INITIAL_POSITION, "LATEST"); // block 1 Map<String, Object> configs = new HashMap<>(); configs.put(AWSSchemaRegistryConstants.AWS_REGION, "aws-region"); configs.put(AWSSchemaRegistryConstants.SCHEMA_AUTO_REGISTRATION_SETTING, true); configs.put(AWSSchemaRegistryConstants.AVRO_RECORD_TYPE, AvroRecordType.GENERIC_RECORD.getName()); FlinkKinesisConsumer<GenericRecord> consumer = new FlinkKinesisConsumer<>( streamName, // block 2 GlueSchemaRegistryAvroDeserializationSchema.forGeneric(schema, configs), properties); FlinkKinesisProducer<GenericRecord> producer = new FlinkKinesisProducer<>( // block 3 GlueSchemaRegistryAvroSerializationSchema.forGeneric(schema, topic, configs), properties); producer.setDefaultStream(streamName); producer.setDefaultPartition("0"); DataStream<GenericRecord> stream = env.addSource(consumer); stream.addSink(producer); env.execute();
使用案例:與 整合 AWS Lambda
使用 AWS Lambda函數作為 Apache Kafka/Amazon MSK取用者,並使用 還原序列化 Avro 編碼的訊息 AWS Glue 結構描述登錄檔,請造訪MSK實驗室頁面
使用案例: AWS Glue Data Catalog
AWS Glue 資料表支援您可以手動或參考 指定的結構描述 AWS Glue 結構描述登錄檔。結構描述登錄檔會與 Data Catalog 整合,可讓您在建立或更新結構描述登錄檔時選擇性地使用存放於結構描述登錄檔中的結構描述 AWS Glue Data Catalog 中的資料表或分割區。若要在結構描述登錄檔中識別結構描述定義,您至少需要知道其所屬結構描述ARN的 。包含結構描述定義的結構描述版本可以由其 UUID或 版本編號參考。永遠有一個結構描述版本,也就是「最新」版本,可以在不知道版本編號或 的情況下進行查詢UUID。
呼叫 CreateTable 或 UpdateTable 操作時,您將傳遞一個 TableInput 結構,其中包含 StorageDescriptor,它可能有一個新增到結構描述登錄檔中現有結構描述的 SchemaReference。同樣地,當您呼叫 GetTable或 GetPartition 時APIs,回應可能包含結構描述和 SchemaReference。使用結構描述參考建立資料表或分割區時,Data Catalog 會嘗試擷取此結構描述參考的結構描述。如果它無法在結構描述登錄檔中找到結構描述,它會在 GetTable 回應中傳回空的結構描述;否則回應將同時具有結構描述和結構描述參考。
您也可以從 執行動作 AWS Glue 主控台。
若要執行這些操作並建立、更新或檢視結構描述資訊,您必須將 IAM角色提供給提供 GetSchemaVersion 許可的呼叫使用者API。
新增資料表或更新資料表的結構描述
從現有的結構描述新增資料表,會將資料表繫結至特定的結構描述版本。註冊新的結構描述版本後,您可以從 中的檢視資料表頁面更新此資料表定義 AWS Glue 主控台或使用 UpdateTable 動作 (Python: update_table) API。
從現有的結構描述新增資料表
您可以建立 AWS Glue 使用 登錄檔中結構描述版本的資料表 AWS Glue 主控台或 CreateTable API。
AWS Glue API
呼叫 CreateTable 時API,您會將TableInput包含 StorageDescriptor的 傳遞SchemaReference至結構描述登錄檔中現有的結構描述。
AWS Glue 主控台
從 建立資料表 AWS Glue 主控台:
-
登入 AWS Management Console 並開啟 AWS Glue 主控台https://console.aws.amazon.com/glue/
。 在導覽窗格中,於 Data catalog 下選擇 Tables (資料表)。
在 Add Tables (新增資料表) 選單中,選擇 Add table from existing schema (從現有結構描述新增資料表)。
根據 設定資料表屬性和資料存放區 AWS Glue 開發人員指南。
在 Choose a Glue schema (選擇 Glue 結構描述) 頁面上,選取結構描述所在的 Registry (登錄檔)。
選擇 Schema name (結構描述名稱),然後選取要套用之結構描述的 Version (版本)。
檢閱結構描述預覽,然後選擇 Next (下一步)。
檢閱和建立資料表。
套用至資料表的結構描述和版本會顯示在資料表清單的 Glue schema (Glue 結構描述) 欄。您可以檢視資料表以查看更多詳細資訊。
更新資料表的結構描述
當新的結構描述版本可用時,您可能想要使用 UpdateTable 動作 (Python: update_table)API或 更新資料表的結構描述 AWS Glue 主控台。
重要
更新具有 之現有資料表的結構描述時 AWS Glue 手動指定的結構描述,結構描述登錄檔中參考的新結構描述可能不相容。這可能會導致您的任務失敗。
AWS Glue API
呼叫 UpdateTable 時API,您會將TableInput包含 StorageDescriptor的 傳遞SchemaReference至結構描述登錄檔中現有的結構描述。
AWS Glue 主控台
若要從 更新資料表的結構描述 AWS Glue 主控台:
-
登入 AWS Management Console 並開啟 AWS Glue 主控台https://console.aws.amazon.com/glue/
。 在導覽窗格中,於 Data catalog 下選擇 Tables (資料表)。
從資料表清單中檢視資料表。
按一下 Update schema (更新結構描述),通知您有關新版本的方塊。
檢閱目前資料結構描述和新資料結構描述之間的差異。
選擇 Show all schema differences (顯示所有結構描述差異) 以查看更多詳細資訊。
選擇 Save table (儲存資料表) 以接受新的版本。
使用案例:AWS Glue 串流
AWS Glue 串流會耗用來自串流來源的資料,並在寫入輸出接收器之前執行ETL操作。輸入串流來源可以使用資料表來指定,也可以透過指定來源配置的方式直接指定。
AWS Glue 串流支援使用 中存在的結構描述建立的串流來源的資料目錄資料表 AWS Glue 結構描述登錄檔。您可以在 中建立結構描述 AWS Glue 結構描述登錄檔並建立 AWS Glue 具有使用此結構描述之串流來源的 資料表。這一個 AWS Glue 資料表可以用作 的輸入 AWS Glue 串流任務,用於取消序列化輸入串流中的資料。
此處需要注意的一點是 AWS Glue 結構描述登錄檔變更,您需要重新啟動 AWS Glue 串流任務需要反映結構描述中的變更。
使用案例:Apache Kafka Streams
Apache Kafka Streams API是用戶端程式庫,用於處理和分析儲存在 Apache Kafka 中的資料。本節說明 Apache Kafka Streams 與 的整合 AWS Glue 結構描述登錄檔,可讓您管理和強制執行資料串流應用程式的結構描述。如需 Apache Kafka Streams 的詳細資訊,請參閱 Apache Kafka Streams
與 SerDes 程式庫整合
有一個 GlueSchemaRegistryKafkaStreamsSerde 類別,您可用於設定串流應用程式。
Kafka Streams 應用程式範例程式碼
若要使用 AWS Glue Apache Kafka Streams 應用程式內的結構描述登錄檔:
設定 Kafka Streams 應用程式。
final Properties props = new Properties(); props.put(StreamsConfig.APPLICATION_ID_CONFIG, "avro-streams"); props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092"); props.put(StreamsConfig.CACHE_MAX_BYTES_BUFFERING_CONFIG, 0); props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName()); props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, AWSKafkaAvroSerDe.class.getName()); props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest"); props.put(AWSSchemaRegistryConstants.AWS_REGION, "aws-region"); props.put(AWSSchemaRegistryConstants.SCHEMA_AUTO_REGISTRATION_SETTING, true); props.put(AWSSchemaRegistryConstants.AVRO_RECORD_TYPE, AvroRecordType.GENERIC_RECORD.getName()); props.put(AWSSchemaRegistryConstants.DATA_FORMAT, DataFormat.AVRO.name());從主題 avro-input 建立串流。
StreamsBuilder builder = new StreamsBuilder(); final KStream<String, GenericRecord> source = builder.stream("avro-input");處理資料記錄 (範例會篩選出 favorite_color 值為 pink 或 amount 值為 15 的記錄)。
final KStream<String, GenericRecord> result = source .filter((key, value) -> !"pink".equals(String.valueOf(value.get("favorite_color")))); .filter((key, value) -> !"15.0".equals(String.valueOf(value.get("amount"))));將結果寫回主題 avro-output。
result.to("avro-output");啟動 Apache Kafka Streams 應用程式。
KafkaStreams streams = new KafkaStreams(builder.build(), props); streams.start();
實作結果
這些結果顯示記錄篩選程序,其在步驟 3 中篩選出 favorite_color 為「pink」或值為「15.0」的記錄。
篩選前的記錄:
{"name": "Sansa", "favorite_number": 99, "favorite_color": "white"} {"name": "Harry", "favorite_number": 10, "favorite_color": "black"} {"name": "Hermione", "favorite_number": 1, "favorite_color": "red"} {"name": "Ron", "favorite_number": 0, "favorite_color": "pink"} {"name": "Jay", "favorite_number": 0, "favorite_color": "pink"} {"id": "commute_1","amount": 3.5} {"id": "grocery_1","amount": 25.5} {"id": "entertainment_1","amount": 19.2} {"id": "entertainment_2","amount": 105} {"id": "commute_1","amount": 15}
篩選後的記錄:
{"name": "Sansa", "favorite_number": 99, "favorite_color": "white"} {"name": "Harry", "favorite_number": 10, "favorite_color": "black"} {"name": "Hermione", "favorite_number": 1, "favorite_color": "red"} {"name": "Ron", "favorite_number": 0, "favorite_color": "pink"} {"id": "commute_1","amount": 3.5} {"id": "grocery_1","amount": 25.5} {"id": "entertainment_1","amount": 19.2} {"id": "entertainment_2","amount": 105}
使用案例:Apache Kafka Connect
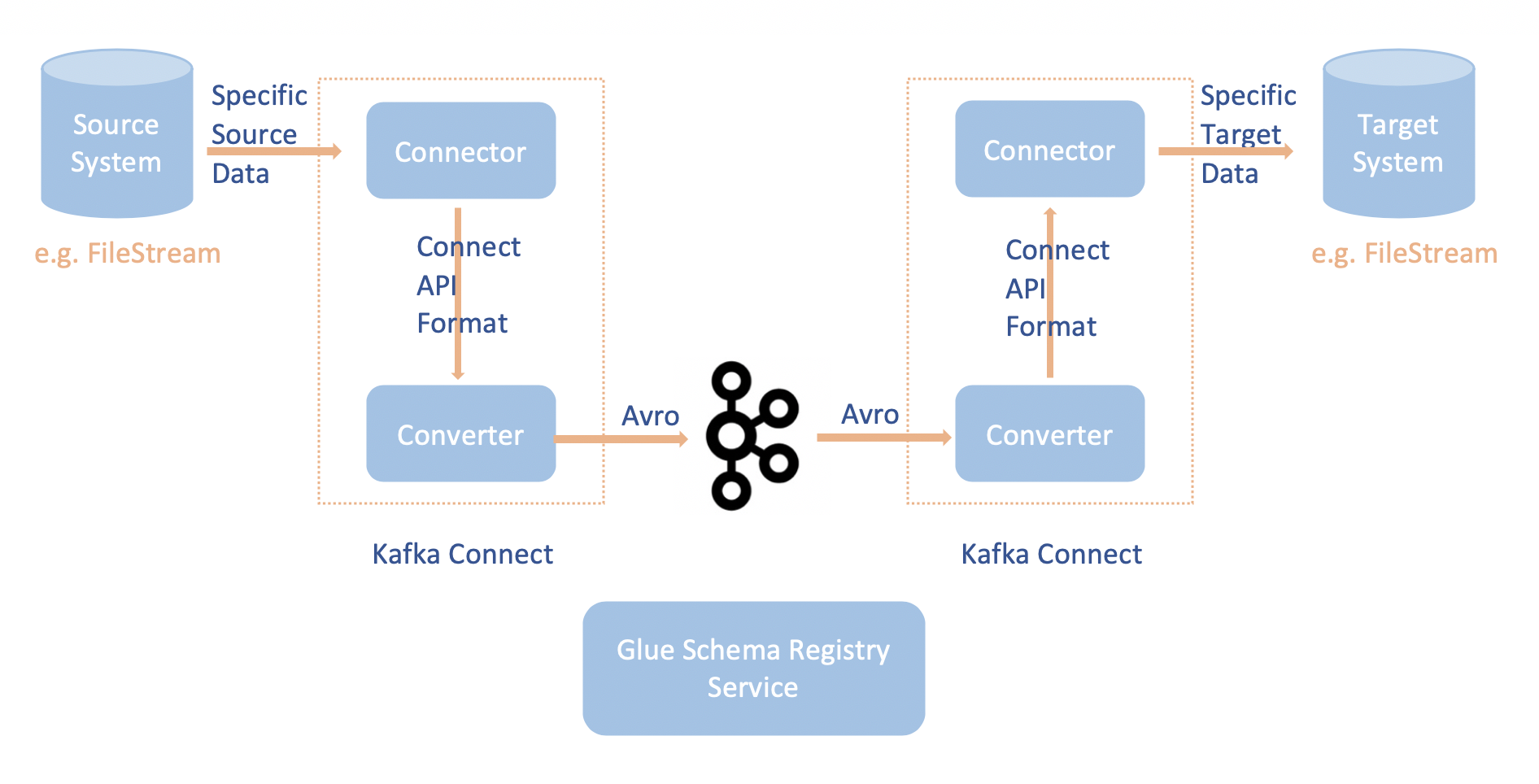
Apache Kafka Connect 與 的整合 AWS Glue 結構描述登錄檔可讓您從連接器取得結構描述資訊。Apache Kafka 轉換器指定 Apache Kafka 中的資料的格式,以及如何將其轉換成 Apache Kafka Connect 資料。每個 Apache Kafka Connect 使用者將需要根據他們希望他們的資料在載入或儲存到 Apache Kafka 時的格式,設定這些轉換器。如此一來,您可以定義自己的轉換器,將 Apache Kafka Connect 資料轉換為 中使用的類型 AWS Glue 結構描述登錄檔 (例如:Avro),並利用我們的序列化器來註冊其結構描述並進行序列化。然後轉換器也能夠使用我們的還原序列化程式將從 Apache Kafka 接收到的資料還原序列化,並將其轉換回 Apache Kafka Connect 資料。範例工作流程圖如下所示。
透過複製 的 Github 儲存庫來安裝
aws-glue-schema-registry專案 AWS Glue 結構描述登錄檔。 git clone git@github.com:awslabs/aws-glue-schema-registry.git cd aws-glue-schema-registry mvn clean install mvn dependency:copy-dependencies如果您打算在獨立模式中使用 Apache Kafka Connect,請使用此步驟的下列指示來更新 connect-standalone.properties。如果您計劃在分散式模式下使用 Apache Kafka Connect,請使用相同的指示更新 connect-avro-distributed.properties。
將這些屬性也新增到 Apache Kafka 連接屬性檔案:
key.converter.region=aws-regionvalue.converter.region=aws-regionkey.converter.schemaAutoRegistrationEnabled=true value.converter.schemaAutoRegistrationEnabled=true key.converter.avroRecordType=GENERIC_RECORD value.converter.avroRecordType=GENERIC_RECORD將下列命令新增至 kafka-run-class.sh 下的啟動模式區段:
-cp $CLASSPATH:"<your AWS GlueSchema Registry base directory>/target/dependency/*"
將下列命令新增至 kafka-run-class.sh 下的啟動模式區段
-cp $CLASSPATH:"<your AWS GlueSchema Registry base directory>/target/dependency/*"它應該如下所示:
# Launch mode if [ "x$DAEMON_MODE" = "xtrue" ]; then nohup "$JAVA" $KAFKA_HEAP_OPTS $KAFKA_JVM_PERFORMANCE_OPTS $KAFKA_GC_LOG_OPTS $KAFKA_JMX_OPTS $KAFKA_LOG4J_OPTS -cp $CLASSPATH:"/Users/johndoe/aws-glue-schema-registry/target/dependency/*" $KAFKA_OPTS "$@" > "$CONSOLE_OUTPUT_FILE" 2>&1 < /dev/null & else exec "$JAVA" $KAFKA_HEAP_OPTS $KAFKA_JVM_PERFORMANCE_OPTS $KAFKA_GC_LOG_OPTS $KAFKA_JMX_OPTS $KAFKA_LOG4J_OPTS -cp $CLASSPATH:"/Users/johndoe/aws-glue-schema-registry/target/dependency/*" $KAFKA_OPTS "$@" fi如果使用 bash,請執行下列命令,在 bash_profile CLASSPATH中設定您的 。對於任何其他 Shell,請相應地更新環境。
echo 'export GSR_LIB_BASE_DIR=<>' >>~/.bash_profile echo 'export GSR_LIB_VERSION=1.0.0' >>~/.bash_profile echo 'export KAFKA_HOME=<your Apache Kafka installation directory>' >>~/.bash_profile echo 'export CLASSPATH=$CLASSPATH:$GSR_LIB_BASE_DIR/avro-kafkaconnect-converter/target/schema-registry-kafkaconnect-converter-$GSR_LIB_VERSION.jar:$GSR_LIB_BASE_DIR/common/target/schema-registry-common-$GSR_LIB_VERSION.jar:$GSR_LIB_BASE_DIR/avro-serializer-deserializer/target/schema-registry-serde-$GSR_LIB_VERSION.jar' >>~/.bash_profile source ~/.bash_profile(選用) 如果您想要使用簡單的檔案來源進行測試,請複製檔案來源連接器。
git clone https://github.com/mmolimar/kafka-connect-fs.git cd kafka-connect-fs/在來源連接器組態下,將資料格式編輯為 Avro、檔案讀取器編輯為
AvroFileReader並從您正在讀取的檔案路徑中更新範例 Avro 物件。例如:vim config/kafka-connect-fs.propertiesfs.uris=<path to a sample avro object> policy.regexp=^.*\.avro$ file_reader.class=com.github.mmolimar.kafka.connect.fs.file.reader.AvroFileReader安裝來源連接器。
mvn clean package echo "export CLASSPATH=\$CLASSPATH:\"\$(find target/ -type f -name '*.jar'| grep '\-package' | tr '\n' ':')\"" >>~/.bash_profile source ~/.bash_profile更新
<your Apache Kafka installation directory>/config/connect-file-sink.propertiesfile=<output file full path> topics=<my topic>
啟動來源連接器 (在此範例中,它是檔案來源連接器)。
$KAFKA_HOME/bin/connect-standalone.sh $KAFKA_HOME/config/connect-standalone.properties config/kafka-connect-fs.properties執行接收器連接器 (在此範例中,它是檔案接收器連接器)。
$KAFKA_HOME/bin/connect-standalone.sh $KAFKA_HOME/config/connect-standalone.properties $KAFKA_HOME/config/connect-file-sink.properties如需 Kafka Connect 用量範例,請參閱 Github 儲存庫中整合測試資料夾下的 run-local-tests.sh 指令碼 AWS Glue 結構描述登錄檔
。
