本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
使用 Amazon Managed Grafana 監控 Amazon EKS 基礎設施的解決方案
監控 Amazon Elastic Kubernetes Service 基礎設施是使用 Amazon Managed Grafana 的最常見案例之一。此頁面說明一個範本,為您提供此案例的解決方案。您可以使用 AWS Cloud Development Kit (AWS CDK)或搭配 Terraform
此解決方案會設定:
-
您的 Amazon Managed Service for Prometheus 工作區可存放來自 Amazon EKS 叢集的指標,並建立受管收集器來抓取指標並將其推送至該工作區。如需詳細資訊,請參閱使用 AWS 受管收集器擷取指標。
-
使用 CloudWatch 代理程式從 Amazon EKS 叢集收集日誌。日誌存放在 CloudWatch 中,並由 Amazon Managed Grafana 查詢。如需詳細資訊,請參閱記錄 Amazon EKS
-
您的 Amazon Managed Grafana 工作區可提取這些日誌和指標,並建立儀表板和提醒,協助您監控叢集。
套用此解決方案將建立儀表板和提醒:
-
評估整體 Amazon EKS 叢集運作狀態。
-
顯示 Amazon EKS 控制平面的運作狀態和效能。
-
顯示 Amazon EKS 資料平面的運作狀態和效能。
-
顯示跨 Kubernetes 命名空間的 Amazon EKS 工作負載洞察。
-
顯示跨命名空間的資源用量,包括 CPU、記憶體、磁碟和網路用量。
關於此解決方案
此解決方案會設定 Amazon Managed Grafana 工作區,為您的 Amazon EKS 叢集提供指標。這些指標用於產生儀表板和提醒。
這些指標可讓您深入了解 Kubernetes 控制和資料平面的運作狀態和效能,進而更有效地操作 Amazon EKS 叢集。您可以從節點層級、Pod 到 Kubernetes 層級了解 Amazon EKS 叢集,包括詳細監控資源用量。
解決方案同時提供預期和修正功能:
-
預期功能包括:
-
透過推動排程決策來管理資源效率。例如,若要為 Amazon EKS 叢集的內部使用者提供效能和可靠性 SLAs,您可以根據追蹤歷史用量,為其工作負載配置足夠的 CPU 和記憶體資源。
-
用量預測:根據您 Amazon EKS 叢集資源的目前使用率,例如節點、Amazon EBS 支援的持久性磁碟區,或 Application Load Balancer,您可以提前規劃,例如,針對具有類似需求的新產品或專案。
-
及早偵測潛在問題:例如,透過分析 Kubernetes 命名空間層級的資源耗用趨勢,您可以了解工作負載用量的季節性。
-
-
更正功能包括:
-
減少基礎設施和 Kubernetes 工作負載層級問題的平均偵測時間 (MTTD)。例如,透過查看故障診斷儀表板,您可以快速測試有關發生錯誤的假設並消除它們。
-
判斷問題在堆疊中發生的位置。例如,Amazon EKS 控制平面完全由 管理,如果 API 伺服器超載或連線受到影響,更新 Kubernetes 部署等 AWS 特定操作可能會失敗。
-
下圖顯示解決方案的儀表板資料夾範例。
您可以選擇儀表板以查看更多詳細資訊,例如,選擇檢視工作負載的運算資源會顯示儀表板,如下圖所示。
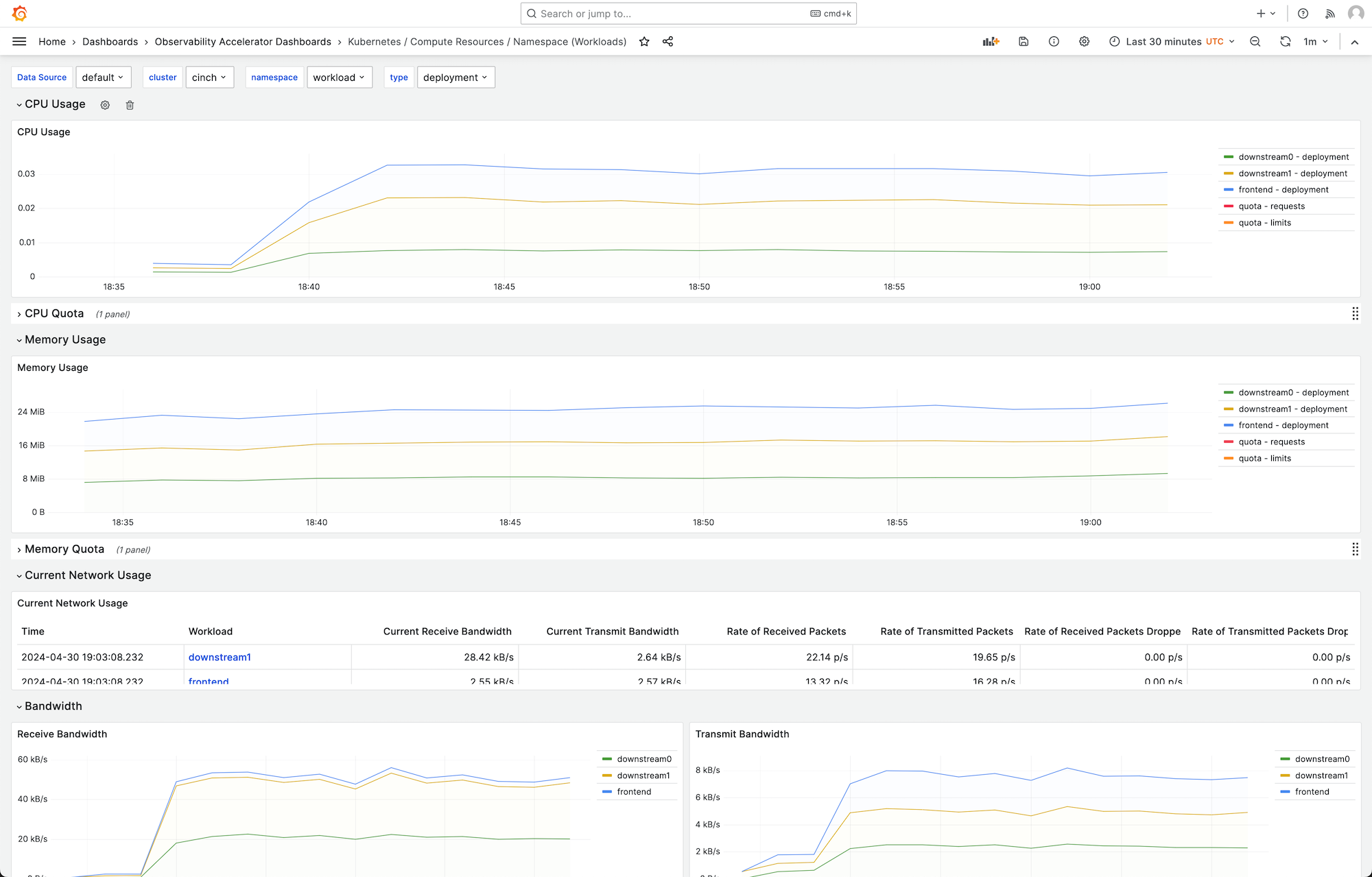
指標會以 1 分鐘的抓取間隔進行抓取。儀表板會根據特定指標,顯示彙總至 1 分鐘、5 分鐘或更多的指標。
日誌也會顯示在儀表板中,以便您可以查詢和分析日誌以尋找問題的根本原因。下圖顯示日誌儀表板。
如需此解決方案追蹤的指標清單,請參閱 追蹤的指標清單。
如需解決方案建立的提醒清單,請參閱 建立的提醒清單。
成本
此解決方案會在您的工作區中建立和使用資源。您將需要支付所建立資源的標準用量費用,包括:
-
使用者存取 Amazon Managed Grafana 工作區。如需定價的詳細資訊,請參閱 Amazon Managed Grafana 定價
。 -
Amazon Managed Service for Prometheus 指標擷取和儲存,包括使用 Amazon Managed Service for Prometheus 無代理程式收集器,以及指標分析 (查詢範例處理)。此解決方案使用的指標數量取決於 Amazon EKS 叢集組態和用量。
您可以使用 CloudWatch 檢視 Amazon Managed Service for Prometheus 中的擷取和儲存指標 如需詳細資訊,請參閱《Amazon Managed Service for Prometheus 使用者指南》中的 CloudWatch 指標。
您可以使用 Amazon Managed Service for Prometheus 定價
頁面上的定價計算器估計成本。指標數量取決於叢集中的節點數量,以及應用程式產生的指標。 -
CloudWatch Logs 擷取、儲存和分析。根據預設,日誌保留會設定為永不過期。您可以在 CloudWatch 中調整此選項。如需定價的詳細資訊,請參閱 Amazon CloudWatch 定價
。 -
網路成本。您可能會針對跨可用區域、區域或其他流量產生標準 AWS 網路費用。
每個產品的定價頁面提供定價計算器,可協助您了解解決方案的潛在成本。下列資訊有助於取得在與 Amazon EKS 叢集相同可用區域中執行之解決方案的基本成本。
| 產品 | 計算器指標 | Value |
|---|---|---|
Amazon Managed Service for Prometheus |
作用中系列 |
8000 (基本) 15,000 (每個節點) |
平均收集間隔 |
60 (秒) |
|
Amazon Managed Service for Prometheus (受管收集器) |
收集器數量 |
1 |
範例數量 |
15 (基礎) 150 (每個節點) |
|
規則數目 |
161 |
|
平均規則擷取間隔 |
60 (秒) |
|
Amazon Managed Grafana |
作用中編輯器/管理員的數量 |
1 (或更多,取決於您的使用者) |
CloudWatch (日誌) |
標準日誌:擷取的資料 |
24.5 GB (基本) 0.5 GB (每個節點) |
日誌儲存/存檔 (標準和已取代的日誌) |
是,以存放日誌:假設保留 1 個月 |
|
掃描的預期日誌資料 |
來自 Grafana 的每個日誌洞察查詢都會掃描群組在指定期間內的所有日誌內容。 |
這些數字是執行 EKS 且沒有其他軟體之解決方案的基本號碼。這將為您提供基本成本的預估。它也會免除網路使用成本,這取決於 Amazon Managed Grafana 工作區、Amazon Managed Service for Prometheus 工作區和 Amazon EKS 叢集是否位於相同的可用區域 AWS 區域和 VPN。
注意
當此表格中的項目包含每個資源(base)的值和值 (例如,(per node)) 時,您應該將基本值新增至每個資源值乘以您擁有該資源的數量。例如,針對平均作用中時間序列,輸入 的數字8000 + the number of nodes in your cluster * 15,000。如果您有 2 個節點,請輸入 38,000,即 8000 + ( 2 * 15,000 )。
先決條件
此解決方案需要您在使用解決方案之前完成以下操作。
-
您必須擁有或建立您要監控的 Amazon Elastic Kubernetes Service 叢集,且叢集必須至少有一個節點。叢集必須設定 API 伺服器端點存取,以包含私有存取 (也可以允許公開存取)。
身分驗證模式必須包含 API 存取 (可以設定為
API或API_AND_CONFIG_MAP)。這可讓解決方案部署使用存取項目。應該在叢集中安裝下列項目 (透過主控台建立叢集時預設為true,但如果您使用 AWS API 或 建立叢集,則必須新增) AWS CLI: AWS CNI、CoreDNS 和 Kube-proxy AddOns。
儲存叢集名稱以稍後指定。這可在 Amazon EKS 主控台的叢集詳細資訊中找到。
注意
如需如何建立 Amazon EKS 叢集的詳細資訊,請參閱 Amazon EKS 入門。
-
您必須在 AWS 帳戶 與 Amazon EKS 叢集相同的 中建立 Amazon Managed Service for Prometheus 工作區。如需詳細資訊,請參閱《Amazon Managed Service for Prometheus 使用者指南》中的建立工作區。
儲存 Amazon Managed Service for Prometheus 工作區 ARN 以供稍後指定。
-
您必須在 AWS 區域 與 Amazon EKS 叢集相同的 中,使用 Grafana 第 9 版或更新版本建立 Amazon Managed Grafana 工作區。如需建立新工作區的詳細資訊,請參閱 建立 Amazon Managed Grafana 工作區。
工作區角色必須具有存取 Amazon Managed Service for Prometheus 和 Amazon CloudWatch APIs許可。最簡單的方法是使用服務受管許可,然後選取 Amazon Managed Service for Prometheus 和 CloudWatch。您也可以手動將 AmazonPrometheusQueryAccess 和 AmazonGrafanaCloudWatchAccess 政策新增至工作區 IAM 角色。
儲存 Amazon Managed Grafana 工作區 ID 和端點以供稍後指定。ID 的格式為
g-123example。您可以在 Amazon Managed Grafana 主控台中找到 ID 和端點。端點是工作區的 URL,並包含 ID。例如https://g-123example.grafana-workspace.<region>.amazonaws.com/。 -
如果您使用 Terraform 部署解決方案,則必須建立可從您的帳戶存取的 Amazon S3 儲存貯體。這將用於存放部署的 Terraform 狀態檔案。
儲存 Amazon S3 儲存貯體 ID 以供稍後指定。
-
若要檢視 Amazon Managed Service for Prometheus 警示規則,您必須啟用 Amazon Managed Grafana 工作區的 Grafana 警示。
此外,Amazon Managed Grafana 必須具有 Prometheus 資源的下列許可。您必須將這些政策新增至中 AWS 資料來源的 Amazon Managed Grafana 許可和政策 所述的服務管理或客戶管理政策。
aps:ListRulesaps:ListAlertManagerSilencesaps:ListAlertManagerAlertsaps:GetAlertManagerStatusaps:ListAlertManagerAlertGroupsaps:PutAlertManagerSilencesaps:DeleteAlertManagerSilence
注意
雖然不需要嚴格設定解決方案,但您必須在 Amazon Managed Grafana 工作區中設定使用者身分驗證,使用者才能存取建立的儀表板。如需詳細資訊,請參閱驗證 Amazon Managed Grafana 工作區中的使用者。
使用此解決方案
此解決方案會設定 AWS 基礎設施,以支援來自 Amazon EKS 叢集的報告和監控指標。您可以使用 AWS Cloud Development Kit (AWS CDK)或 搭配 Terraform
追蹤的指標清單
此解決方案會建立從 Amazon EKS 叢集收集指標的湊集器。這些指標會儲存在 Amazon Managed Service for Prometheus 中,然後顯示在 Amazon Managed Grafana 儀表板中。根據預設,湊集器會收集叢集公開的所有 Prometheus 相容指標。在叢集中安裝產生更多指標的軟體將增加收集的指標。如果需要,您可以使用篩選指標的組態來更新抓取器,以減少指標數量。
在基本 Amazon EKS 叢集組態中,此解決方案會追蹤下列指標,而未安裝其他軟體。
| 指標 | 描述/目的 |
|---|---|
|
|
標示為無法使用的 APIServices 計量,依 APIService 名稱細分。 |
|
|
以秒為單位的許可 Webhook 延遲長條圖,依每個操作和 API 資源和類型 (驗證或許可) 的名稱識別和細分。 |
|
|
最後 秒內每個請求類型的目前使用中請求限制數量上限。 |
|
|
快取 DEKs 目前佔用的快取插槽百分比。 |
|
|
API Priority and Fairness 子系統中初始 (適用於 WATCH) 或任何 (適用於非 WATCH) 執行階段的請求數量。 |
|
|
API Priority and Fairness 子系統中初始 (適用於 WATCH) 或任何 (適用於非 WATCH) 執行階段中被拒絕的請求數量。 |
|
|
為每個優先順序層級設定的正式執行座位數。 |
|
|
API Priority and Fairness 子系統中初始階段 (適用於 WATCH) 或任何 (適用於非 WATCH) 請求執行階段的儲存貯體長條圖。 |
|
|
API Priority and Fairness 子系統中請求執行的初始階段 (適用於 WATCH) 或任何階段 (適用於非 WATCH) 計數。 |
|
|
指出 API 伺服器請求。 |
|
|
已請求、依 APIs的已棄用 API 計量。 |
|
|
每個動詞、試轉值、群組、版本、資源、子資源、範圍和元件的回應延遲分佈,以秒為單位。 |
|
|
每個動詞、試轉值、群組、版本、資源、子資源、範圍和元件的回應延遲分佈的儲存貯體長條圖,以秒為單位。 |
|
|
每個動詞、試轉值、群組、版本、資源、子資源、範圍和元件的服務水準目標 (SLO) 回應延遲分佈,以秒為單位。 |
|
|
apiserver 在自我防禦中終止的請求數量。 |
|
|
每個動詞、試轉值、群組、版本、資源、範圍、元件和 HTTP 回應碼的清除請求計數器。 |
|
|
消耗的累積 cpu 時間。 |
|
|
讀取位元組的累積計數。 |
|
|
已完成讀取的累積計數。 |
|
|
寫入位元組的累積計數。 |
|
|
已完成寫入的累積計數。 |
|
|
頁面快取記憶體總計。 |
|
|
RSS 的大小。 |
|
|
容器交換用量。 |
|
|
目前的工作集。 |
|
|
收到的位元組累積計數。 |
|
|
接收時捨棄的封包累積計數。 |
|
|
收到的封包累積計數。 |
|
|
傳輸的位元組累積計數。 |
|
|
傳輸時捨棄的封包累積計數。 |
|
|
傳輸的封包累積計數。 |
|
|
對於每個操作和物件類型,以秒為單位的模擬請求延遲的儲存貯體長條圖。 |
|
|
目前存在的 goroutine 數目。 |
|
|
建立的作業系統執行緒數目。 |
|
|
cgroup Manager 操作的儲存貯體持續時間長條圖,以秒為單位。依方法分解。 |
|
|
cgroup Manager 操作的持續時間,以秒為單位。依方法分解。 |
|
|
如果節點發生組態相關錯誤,此指標為 true (1),否則為 false (0)。 |
|
|
節點的名稱。計數一律為 1。 |
|
|
在 PLEG 中重新列出 Pod 的儲存貯體持續時間長條圖,以秒為單位。 |
|
|
在 PLEG 中重新列出 Pod 的持續時間計數,以秒為單位。 |
|
|
在 PLEG 中重新列出間隔的儲存貯體長條圖,以秒為單位。 |
|
|
從 kubelet 第一次看到 Pod 到 Pod 開始執行的持續時間計數,以秒為單位。 |
|
|
用於同步單一 Pod 的儲存貯體持續時間長條圖,以秒為單位。依操作類型中斷:建立、更新或同步。 |
|
|
同步單一 Pod 的持續時間計數,以秒為單位。依操作類型中斷:建立、更新或同步。 |
|
|
目前正在執行的容器數量。 |
|
|
具有執行中 Pod 沙盒的 Pod 數量。 |
|
|
以執行時間操作秒為單位的儲存貯體持續時間長條圖。依操作類型分解。 |
|
|
依操作類型列出的累計執行時間操作錯誤數目。 |
|
|
依操作類型計算的執行時間操作數量。 |
|
|
Pod 可配置的資源量 (在為系統常駐程式保留部分 之後)。 |
|
|
節點可用的資源總量。 |
|
|
容器請求的限制資源數量。 |
|
|
容器請求的限制資源數量。 |
|
|
容器所請求的請求資源數量。 |
|
|
容器所請求的請求資源數量。 |
|
|
Pod 擁有者的相關資訊。 |
|
|
Kubernetes 中的資源配額會對命名空間內的 CPU、記憶體和儲存體等資源強制執行用量限制。 |
|
|
節點的 CPU 用量指標,包括每個核心的用量和總用量。 |
|
|
每個模式中花費CPUs 秒數。 |
|
|
節點在磁碟上執行 I/O 操作所花費的累積時間。 |
|
|
節點在磁碟上執行 I/O 操作所花費的總時間。 |
|
|
節點從磁碟讀取的位元組總數。 |
|
|
節點寫入磁碟的位元組總數。 |
|
|
Kubernetes 叢集中節點之檔案系統上可用空間的位元組數。 |
|
|
節點上檔案系統的總大小。 |
|
|
節點 CPU 用量的 1 分鐘負載平均值。 |
|
|
節點 CPU 用量的 15 分鐘負載平均值。 |
|
|
節點 CPU 用量的 5 分鐘負載平均值。 |
|
|
節點作業系統用於緩衝區快取的記憶體量。 |
|
|
節點作業系統用於磁碟快取的記憶體量。 |
|
|
可供應用程式和快取使用的記憶體數量。 |
|
|
節點上可用的可用記憶體數量。 |
|
|
節點上可用的實體記憶體總量。 |
|
|
節點透過網路接收的位元組總數。 |
|
|
節點透過網路傳輸的位元組總數。 |
|
|
花費的使用者和系統 CPU 總時間,以秒為單位。 |
|
|
常駐記憶體大小,以位元組為單位。 |
|
|
HTTP 請求的數量,依狀態碼、方法和主機分割。 |
|
|
請求延遲的儲存貯體長條圖,以秒為單位。被動詞和主機分解。 |
|
|
儲存操作持續時間的儲存貯體長條圖。 |
|
|
儲存操作持續時間的計數。 |
|
|
儲存操作期間的累積錯誤數量。 |
|
|
指出受監控目標 (例如節點) 是否已啟動並執行的指標。 |
|
|
磁碟區管理員管理的磁碟區總數。 |
|
|
工作佇列處理的新增總數。 |
|
|
工作佇列的目前深度。 |
|
|
儲存貯體長條圖,顯示項目在請求之前在工作佇列中停留的秒數。 |
|
|
從工作佇列處理項目所需的儲存貯體長條圖,以秒為單位。 |
建立的提醒清單
下表列出此解決方案建立的提醒。提醒會在 Amazon Managed Service for Prometheus 中建立為規則,並顯示在 Amazon Managed Grafana 工作區中。
您可以修改規則,包括透過編輯 Amazon Managed Service for Prometheus 工作區中的規則組態檔案來新增或刪除規則。
這兩個提醒是特殊提醒,處理方式與一般提醒略有不同。它們不會提醒您問題,而是為您提供用於監控系統的資訊。描述包含如何使用這些提醒的詳細資訊。
| 警示 | 描述和用量 |
|---|---|
|
這是提醒,旨在確保整個提醒管道都正常運作。此提醒一律會觸發,因此應一律在 Alertmanager 中觸發,並一律對接收者觸發。您可以將此與通知機制整合,在未觸發此提醒時傳送通知。例如,您可以在 PagerDuty 中使用 DeadMansSnitch 整合。 |
|
這是用於抑制資訊提醒的提醒。資訊層級警示本身可能非常吵雜,但在與其他警示結合時是相關的。每當有 |
下列提醒會為您提供有關系統的資訊或警告。
| 警示 | 嚴重性 | Description |
|---|---|---|
|
|
warning |
網路界面通常會變更其狀態 |
|
|
warning |
檔案系統預計在接下來的 24 小時內會用盡空間。 |
|
|
critical |
檔案系統預計在接下來的 4 小時內會用盡空間。 |
|
|
warning |
檔案系統的剩餘空間少於 5%。 |
|
|
critical |
檔案系統的剩餘空間少於 3%。 |
|
|
warning |
檔案系統預計會在接下來的 24 小時內耗盡索引。 |
|
|
critical |
檔案系統預計會在接下來的 4 小時內耗盡索引。 |
|
|
warning |
檔案系統剩餘少於 5% 的索引。 |
|
|
critical |
檔案系統剩餘少於 3% 的索引。 |
|
|
warning |
網路界面正在報告許多接收錯誤。 |
|
|
warning |
網路界面正在報告許多傳輸錯誤。 |
|
|
warning |
連線項目數量接近限制。 |
|
|
warning |
Node Exporter 文字檔案收集器無法抓取。 |
|
|
warning |
偵測到時鐘扭曲。 |
|
|
warning |
時鐘未同步。 |
|
|
critical |
RAID 陣列已降級 |
|
|
warning |
RAID 陣列中的失敗裝置 |
|
|
warning |
預測核心很快就會耗盡檔案描述項限制。 |
|
|
critical |
預測核心很快就會耗盡檔案描述項限制。 |
|
|
warning |
節點尚未就緒。 |
|
|
warning |
無法連線節點。 |
|
|
info |
Kubelet 正在以容量執行。 |
|
|
warning |
節點整備狀態為翻轉。 |
|
|
warning |
Kubelet Pod 生命週期事件產生器重新列出的時間太長。 |
|
|
warning |
Kubelet Pod 啟動延遲太高。 |
|
|
warning |
Kubelet 用戶端憑證即將過期。 |
|
|
critical |
Kubelet 用戶端憑證即將過期。 |
|
|
warning |
Kubelet 伺服器憑證即將過期。 |
|
|
critical |
Kubelet 伺服器憑證即將過期。 |
|
|
warning |
Kubelet 無法續約其用戶端憑證。 |
|
|
warning |
Kubelet 無法續約其伺服器憑證。 |
|
|
critical |
目標已從 Prometheus 目標探索中消失。 |
|
|
warning |
執行中 Kubernetes 元件的不同語意版本。 |
|
|
warning |
Kubernetes API 伺服器用戶端發生錯誤。 |
|
|
warning |
用戶端憑證即將過期。 |
|
|
critical |
用戶端憑證即將過期。 |
|
|
warning |
Kubernetes 彙總 API 已回報錯誤。 |
|
|
warning |
Kubernetes 彙總 API 已關閉。 |
|
|
critical |
目標已從 Prometheus 目標探索中消失。 |
|
|
warning |
kubernetes apiserver 已終止 {{ $value | humanizePercentage }} 的傳入請求。 |
|
|
critical |
持久性磁碟區正在填滿。 |
|
|
warning |
持久性磁碟區正在填滿。 |
|
|
critical |
持久性磁碟區 Inodes 正在填滿。 |
|
|
warning |
持久性磁碟區節點正在填滿。 |
|
|
critical |
持久性磁碟區在佈建方面發生問題。 |
|
|
warning |
叢集有過度遞交的 CPU 資源請求。 |
|
|
warning |
叢集有過度遞交的記憶體資源請求。 |
|
|
warning |
叢集有過度遞交的 CPU 資源請求。 |
|
|
warning |
叢集有過度遞交的記憶體資源請求。 |
|
|
info |
命名空間配額將已滿。 |
|
|
info |
命名空間配額已完全使用。 |
|
|
warning |
命名空間配額已超過限制。 |
|
|
info |
程序會體驗提升的 CPU 限流。 |
|
|
warning |
Pod 正在當機迴圈。 |
|
|
warning |
Pod 已處於非就緒狀態超過 15 分鐘。 |
|
|
warning |
由於可能的復原,部署產生不相符 |
|
|
warning |
部署不符合預期的複本數量。 |
|
|
warning |
StatefulSet 不符合預期的複本數量。 |
|
|
warning |
由於可能的轉返,StatefulSet 產生不相符 |
|
|
warning |
StatefulSet 更新尚未推出。 |
|
|
warning |
DaemonSet 推展卡住。 |
|
|
warning |
Pod 容器等待超過 1 小時 |
|
|
warning |
未排程 DaemonSet Pod。 |
|
|
warning |
DaemonSet Pod 排程錯誤。 |
|
|
warning |
任務未及時完成 |
|
|
warning |
任務無法完成。 |
|
|
warning |
HPA 不符合所需的複本數量。 |
|
|
warning |
HPA 正在以最大複本執行 |
|
|
critical |
kube-state-metrics 在清單操作中遇到錯誤。 |
|
|
critical |
kube-state-metrics 在監看操作中遇到錯誤。 |
|
|
critical |
kube-state-metrics 碎片設定錯誤。 |
|
|
critical |
缺少 kube-state-metrics 碎片。 |
|
|
critical |
API 伺服器消耗過多的錯誤預算。 |
|
|
critical |
API 伺服器消耗過多的錯誤預算。 |
|
|
warning |
API 伺服器消耗過多的錯誤預算。 |
|
|
warning |
API 伺服器消耗過多的錯誤預算。 |
|
|
warning |
一或多個目標已關閉。 |
|
|
critical |
Etcd 叢集成員不足。 |
|
|
warning |
Etcd 叢集大量領導者變更。 |
|
|
critical |
Etcd 叢集沒有領導者。 |
|
|
warning |
Etcd 叢集大量失敗的 gRPC 請求。 |
|
|
critical |
Etcd 叢集 gRPC 請求緩慢。 |
|
|
warning |
Etcd 叢集成員通訊緩慢。 |
|
|
warning |
Etcd 叢集大量失敗的提案。 |
|
|
warning |
Etcd 叢集高同步持續時間。 |
|
|
warning |
Etcd 叢集的遞交持續時間高於預期。 |
|
|
warning |
Etcd 叢集的 HTTP 請求失敗。 |
|
|
critical |
Etcd 叢集有大量失敗的 HTTP 請求。 |
|
|
warning |
Etcd 叢集 HTTP 請求緩慢。 |
|
|
warning |
主機時鐘未同步。 |
|
|
warning |
偵測到主機 OOM 刪除。 |
疑難排解
有幾件事可能會導致專案設定失敗。請務必檢查下列項目。
-
您必須先完成所有先決條件,才能安裝解決方案。
-
叢集必須至少有一個節點,才能嘗試建立解決方案或存取指標。
-
您的 Amazon EKS 叢集必須安裝
AWS CNI、CoreDNS和kube-proxy附加元件。如果未安裝,解決方案將無法正常運作。透過主控台建立叢集時,預設會安裝它們。如果叢集是透過 AWS SDK 建立,您可能需要安裝它們。 -
Amazon EKS Pod 安裝逾時。如果節點容量不足,就可能發生這種情況。這些問題有多種原因,包括:
-
Amazon EKS 叢集已使用 Fargate 而非 Amazon EC2 初始化。此專案需要 Amazon EC2。
-
節點會受到污點,因此無法使用。
您可以使用
kubectl describe node檢查污點。然後NODENAME| grep Taintskubectl taint node移除污點。請務必在污點名稱NODENAMETAINT_NAME--後面包含 。 -
節點已達到容量限制。在這種情況下,您可以建立新的節點或增加容量。
-
-
您在 Grafana 中看不到任何儀表板:使用不正確的 Grafana 工作區 ID。
執行下列命令以取得 Grafana 的相關資訊:
kubectl describe grafanas external-grafana -n grafana-operator您可以檢查結果是否有正確的工作區 URL。如果不是您預期的工作空間,請使用正確的工作區 ID 重新部署。
Spec: External: API Key: Key: GF_SECURITY_ADMIN_APIKEY Name: grafana-admin-credentials URL: https://g-123example.grafana-workspace.aws-region.amazonaws.com Status: Admin URL: https://g-123example.grafana-workspace.aws-region.amazonaws.com Dashboards: ... -
您在 Grafana 中看不到任何儀表板:您正在使用過期的 API 金鑰。
若要尋找此案例,您需要取得 grafana 運算子並檢查日誌是否有錯誤。使用此命令取得 Grafana 運算子的名稱:
kubectl get pods -n grafana-operator這將傳回運算子名稱,例如:
NAME READY STATUS RESTARTS AGEgrafana-operator-1234abcd5678ef901/1 Running 0 1h2m在下列命令中使用運算子名稱:
kubectl logsgrafana-operator-1234abcd5678ef90-n grafana-operator下列錯誤訊息表示 API 金鑰已過期:
ERROR error reconciling datasource {"controller": "grafanadatasource", "controllerGroup": "grafana.integreatly.org", "controllerKind": "GrafanaDatasource", "GrafanaDatasource": {"name":"grafanadatasource-sample-amp","namespace":"grafana-operator"}, "namespace": "grafana-operator", "name": "grafanadatasource-sample-amp", "reconcileID": "72cfd60c-a255-44a1-bfbd-88b0cbc4f90c", "datasource": "grafanadatasource-sample-amp", "grafana": "external-grafana", "error": "status: 401, body: {\"message\":\"Expired API key\"}\n"} github.com/grafana-operator/grafana-operator/controllers.(*GrafanaDatasourceReconciler).Reconcile在此情況下,請建立新的 API 金鑰並再次部署解決方案。如果問題仍然存在,您可以在重新部署之前使用下列命令強制同步:
kubectl delete externalsecret/external-secrets-sm -n grafana-operator -
CDK 安裝 – 缺少 SSM 參數。如果您看到類似以下的錯誤,請執行
cdk bootstrap,然後再試一次。Deployment failed: Error: aws-observability-solution-eks-infra-$EKS_CLUSTER_NAME: SSM parameter /cdk-bootstrap/xxxxxxx/version not found. Has the environment been bootstrapped? Please run 'cdk bootstrap' (see https://docs.aws.amazon.com/cdk/latest/ guide/bootstrapping.html) -
如果 OIDC 提供者已存在,則部署可能會失敗。您將看到如下所示的錯誤 (在此情況下,適用於 CDK 安裝):
| CREATE_FAILED | Custom::AWSCDKOpenIdConnectProvider | OIDCProvider/Resource/Default Received response status [FAILED] from custom resource. Message returned: EntityAlreadyExistsException: Provider with url https://oidc.eks.REGION.amazonaws.com/id/PROVIDER IDalready exists.在此情況下,請前往 IAM 入口網站並刪除 OIDC 供應商,然後再試一次。
-
Terraform 安裝 – 您看到錯誤訊息,其中包含
cluster-secretstore-sm failed to create kubernetes rest client for update of resource和failed to create kubernetes rest client for update of resource。此錯誤通常表示 Kubernetes 叢集中未安裝或啟用外部秘密運算子。這會安裝為解決方案部署的一部分,但有時在解決方案需要它時尚未就緒。
您可以使用下列命令來驗證是否已安裝:
kubectl get deployments -n external-secrets如果已安裝,可能需要一些時間才能讓運算子完全準備好可供使用。您可以執行下列命令,檢查所需自訂資源定義 (CRDs的狀態:
kubectl get crds|grep external-secrets此命令應列出與外部秘密運算子相關的 CRDs,包括
clustersecretstores.external-secrets.io和externalsecrets.external-secrets.io。如果未列出,請等待幾分鐘,然後再次檢查。註冊 CRDs後,您可以
terraform apply再次執行 來部署解決方案。
