在仔細考慮之後,我們決定停止 Amazon Kinesis Data Analytics for SQL 應用程式:
1. 從 2025 年 9 月 1 日起,我們不會為 Amazon Kinesis Data Analytics for SQL 應用程式提供任何錯誤修正,因為考慮到即將終止,我們將對其提供有限的支援。
2. 從 2025 年 10 月 15 日起,您將無法建立新的 Kinesis Data Analytics for SQL 應用程式。
3. 我們將自 2026 年 1 月 27 日起刪除您的應用程式。您將無法啟動或操作 Amazon Kinesis Data Analytics for SQL 應用程式。從那時起,Amazon Kinesis Data Analytics for SQL 將不再提供支援。如需詳細資訊,請參閱Amazon Kinesis Data Analytics for SQL 應用程式終止。
本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
範例:使用列時間的輪轉窗口
當窗口查詢以非重疊的方式處理每個窗口時,即稱作輪轉窗口。如需詳細資訊,請參閱輪轉窗口(使用 GROUP BY 彙總)。此 Amazon Kinesis Data Analytics 範例使用 ROWTIME 資料欄來建立輪轉窗口。該 ROWTIME 欄示應用程式讀取記錄的時間。
在此範例中,將下列記錄寫入 Amazon Kinesis 資料串流。
{"TICKER": "TBV", "PRICE": 33.11} {"TICKER": "INTC", "PRICE": 62.04} {"TICKER": "MSFT", "PRICE": 40.97} {"TICKER": "AMZN", "PRICE": 27.9} ...
然後,您可以在 中建立 Kinesis Data Analytics 應用程式 AWS Management Console,並將 Kinesis 資料串流做為串流來源。探索程序會讀取串流來源上的範例記錄,並推斷含有兩個資料欄 (TICKER 和 PRICE) 的應用程式內結構描述,如下所示。
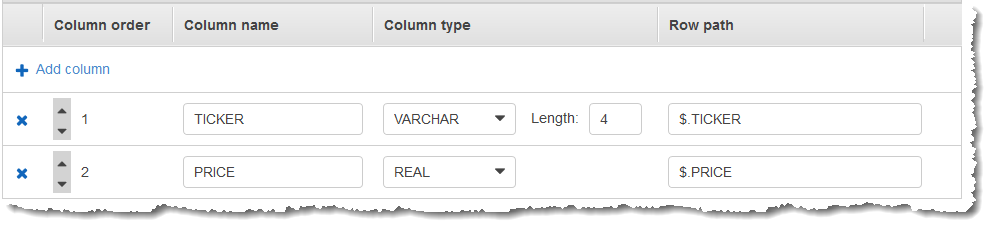
您可以將應用程式碼與 MIN 和 MAX 函數搭配使用,以建立資料的窗口化彙總。接著將產生的資料插入另一個應用程式內串流,如下列螢幕擷取畫面所示:
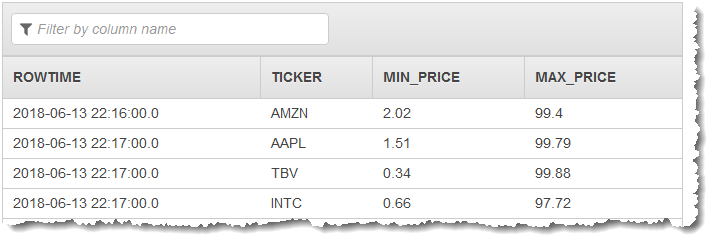
在下列程序中,建立 Kinesis Data Analytics 應用程式,以根據 ROWTIME 在輪轉窗口彙總輸入串流中的值。
步驟 1:建立 Kinesis Data Stream
建立 Amazon Kinesis 資料串流,並填入紀錄,如下所示:
登入 AWS Management Console 並開啟位於 https://https://console.aws.amazon.com/kinesis
的 Kinesis 主控台。 -
在導覽窗格中選擇資料串流。
-
選擇建立 Kinesis 串流,然後建立內含一個碎片之串流。如需詳細資訊,請參閱 Amazon Kinesis Data Streams 開發人員指南中的建立串流。
-
若要在生產環境中將記錄寫入 Kinesis 資料串流,建議您使用 Kinesis Client Library或 Kinesis Data Streams API。為了簡單起見,這個例子使用下面的 Python 指令碼來生成記錄。執行程式碼以填入範例股票代號記錄。這個簡單的程式碼會持續將隨機股票代號記錄寫入串流。讓指令碼持續執行,以便在稍後的步驟產生應用程式結構描述。
import datetime import json import random import boto3 STREAM_NAME = "ExampleInputStream" def get_data(): return { "EVENT_TIME": datetime.datetime.now().isoformat(), "TICKER": random.choice(["AAPL", "AMZN", "MSFT", "INTC", "TBV"]), "PRICE": round(random.random() * 100, 2), } def generate(stream_name, kinesis_client): while True: data = get_data() print(data) kinesis_client.put_record( StreamName=stream_name, Data=json.dumps(data), PartitionKey="partitionkey" ) if __name__ == "__main__": generate(STREAM_NAME, boto3.client("kinesis"))
步驟 2:建立 Kinesis Data Analytics 應用程式
建立 Kinesis Data Analytics 應用程式,如下所示。
前往 https://console.aws.amazon.com/kinesisanalytics
開啟 Managed Service for Apache Flink 主控台。 -
選擇建立應用程式,輸入應用程式名稱,然後選擇建立應用程式。
-
在應用程式詳細資料頁面上,選擇連接串流資料來連接至來源。
-
在連接至來源頁面,執行下列動作:
-
選擇您在上一節建立的串流。
-
選擇探索結構描述。等待主控台顯示推斷的結構描述和範例記錄,這些記錄可用來推斷應用程式內串流所建立的結構描述。推斷的結構描述有兩個資料欄。
-
選擇儲存結構描述並更新串流範例。主控台儲存結構描述後,選擇結束。
-
選擇儲存並繼續。
-
-
在應用程式詳細資訊頁面上,選擇至 SQL 編輯器。若要啟動應用程式,請在出現的對話方塊中選擇是,啟動應用程式。
-
在 SQL 編輯器中,編寫應用程式碼並驗證結果,如下所示:
-
請複製以下應用程式碼,然後貼到編輯器中。
CREATE OR REPLACE STREAM "DESTINATION_SQL_STREAM" (TICKER VARCHAR(4), MIN_PRICE REAL, MAX_PRICE REAL); CREATE OR REPLACE PUMP "STREAM_PUMP" AS INSERT INTO "DESTINATION_SQL_STREAM" SELECT STREAM TICKER, MIN(PRICE), MAX(PRICE) FROM "SOURCE_SQL_STREAM_001" GROUP BY TICKER, STEP("SOURCE_SQL_STREAM_001".ROWTIME BY INTERVAL '60' SECOND); -
選擇 儲存並執行 SQL。
在即時分析標籤上,您可以查看應用程式建立的所有應用程式內串流,並驗證資料。
-
