本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
混合存取模式的運作方式
下圖顯示當您查詢 Data Catalog 資源時 Lake Formation 授權如何在混合存取模式中運作。
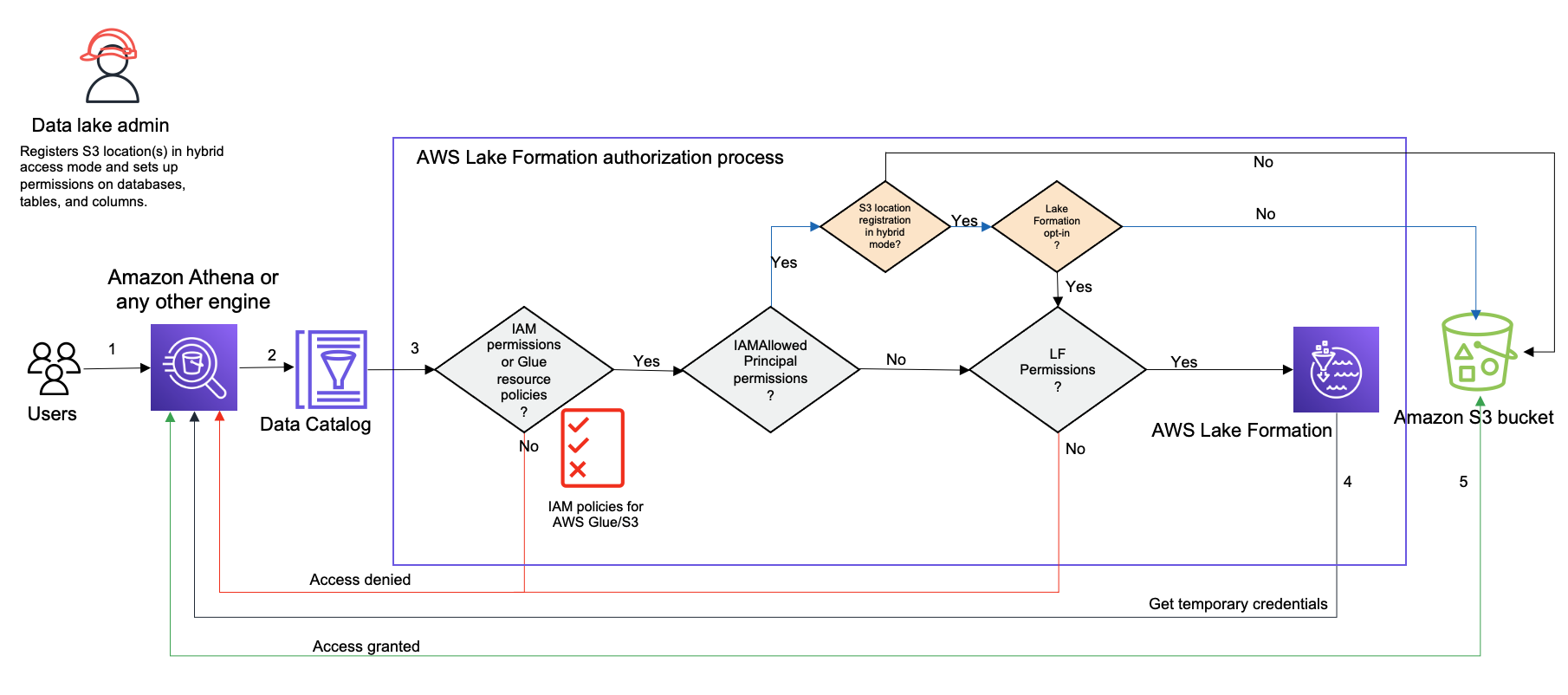
在存取資料湖中的資料之前,具有管理許可的資料湖管理員或使用者會設定個別的資料目錄資料表使用者政策,以允許或拒絕存取資料目錄中的資料表。然後,具有執行RegisterResource操作許可的委託人會將資料表的 Amazon S3 位置註冊為 Lake Formation 混合存取模式。管理員將 Lake Formation 許可授予 Data Catalog 資料庫和資料表上的特定使用者,並選擇讓他們在混合存取模式下使用這些資料庫和資料表的 Lake Formation 許可。
提交查詢 - 委託人使用整合服務提交查詢或ETL指令碼,例如 Amazon Athena AWS Glue、Amazon EMR或 Amazon Redshift Spectrum。
請求資料 - 整合式分析引擎會識別請求的資料表,並將中繼資料請求傳送至 Data Catalog (
GetTable、GetDatabase)。-
檢查許可 - Data Catalog 會使用 Lake Formation 驗證查詢主體的存取許可。
-
如果資料表未連接
IAMAllowedPrincipals群組許可,則會強制執行 Lake Formation 許可。 -
如果主體已選擇在混合存取模式中使用 Lake Formation 許可,且資料表已連接
IAMAllowedPrincipals群組許可,則會強制執行 Lake Formation 許可。查詢引擎會套用從 Lake Formation 收到的篩選條件,並將資料傳回給使用者。 -
如果資料表位置未向 Lake Formation 註冊,且主體尚未選擇在混合存取模式中使用 Lake Formation 許可,則 Data Catalog 會檢查資料表是否已連接
IAMAllowedPrincipals群組許可。如果此許可存在於資料表中,則帳戶中的所有主體都會取得資料表上的Super或All許可。
-
-
取得憑證 – Data Catalog 會檢查並告知引擎資料表位置是否已向 Lake Formation 註冊。如果基礎資料已向 Lake Formation 註冊,分析引擎會請求 Lake Formation 提供暫時憑證,以存取 Amazon S3 儲存貯體中的資料。
-
取得資料 – 如果委託人有權存取資料表資料,Lake Formation 會提供整合式分析引擎的暫時存取權。分析引擎會使用暫時存取從 Amazon S3 擷取資料,並執行必要的篩選,例如資料欄、資料列或儲存格篩選。當引擎完成執行任務時,它會將結果傳回給使用者。此程序稱為憑證販售程序。如需詳細資訊, 請參閱 將第三方服務與 整合 Lake Formation。
-
如果資料表的資料位置未向 Lake Formation 註冊,則分析引擎的第二個呼叫會直接呼叫 Amazon S3。評估相關的 Amazon S3 儲存貯體政策和IAM使用者政策以進行資料存取。每當您使用IAM政策時,請務必遵循IAM最佳實務。如需詳細資訊,請參閱 IAM 使用者指南 IAM 中的安全最佳實務。
