我們不再更新 Amazon Machine Learning 服務或接受新使用者。本文件可供現有使用者使用,但我們不再更新。如需詳細資訊,請參閱什麼是 Amazon Machine Learning。
本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
交叉驗證
交叉驗證是一種評估 ML 模型的技術,採用的方法是使用可用輸入資料的子集來訓練數個 ML 模型並根據資料的互補子集來評估這些模型。使用交叉驗證可以偵測過度擬合,亦即無法一般化模式。
在 Amazon ML 中,您可以使用 k 倍交叉驗證方法來執行交叉驗證。在 k 倍交叉驗證中,您可以將輸入資料分割為 k 個資料子集 (也稱為折疊)。 您可以在除了一個 (k-1) 以外的所有子集上訓練 ML 模型,然後在未用於訓練的子集上評估模型。此程序會重複 k 次,每次保留不同的子集用於評估 (以及排除不用於訓練)。
下圖顯示在 4 倍交叉驗證期間建立和訓練的四個模型,為每個模型所產生的訓練子集和互補評估子集範例。模型一將前 25% 的資料用於評估,其餘 75% 用於訓練。模型二將第二個 25% 子集 (25% 到 50%) 用於評估,其餘三個子集 的資料用於訓練,依此類推。
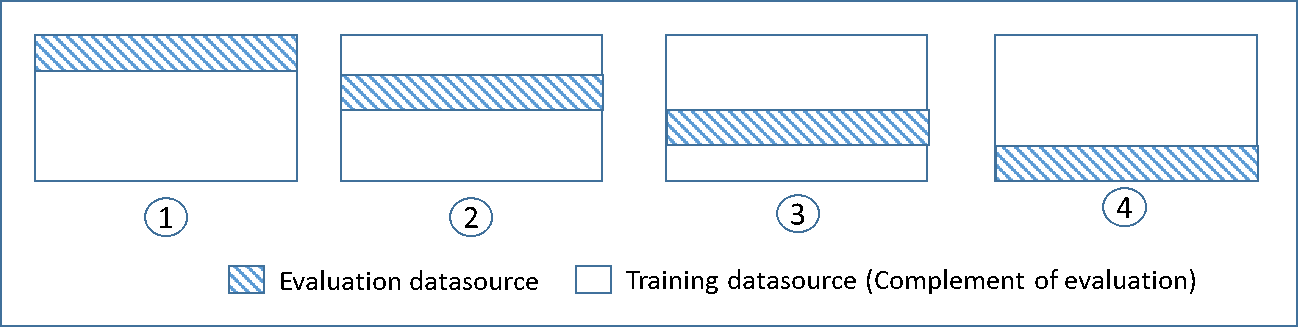
每個模型使用互補資料來源來訓練和評估 - 評估資料來源中的資料包含並受限於不屬於訓練資料來源的所有資料。您使用 DataRearrangement、createDatasourceFromS3 和 createDatasourceFromRedShift API 中的 createDatasourceFromRDS 參數來建立這些子集的資料來源。在 DataRearrangement 參數中,指定每個區段的開始和結束位置,來指定資料來源要包含哪些資料子集。若要建立 4k 倍交叉驗證所需的互補資料來源,請指定 DataRearrangement 參數,如以下範例所示:
模型一:
評估的資料來源:
{"splitting":{"percentBegin":0, "percentEnd":25}}
培訓的資料來源:
{"splitting":{"percentBegin":0, "percentEnd":25, "complement":"true"}}
模型二:
評估的資料來源:
{"splitting":{"percentBegin":25, "percentEnd":50}}
培訓的資料來源:
{"splitting":{"percentBegin":25, "percentEnd":50, "complement":"true"}}
模型三:
評估的資料來源:
{"splitting":{"percentBegin":50, "percentEnd":75}}
培訓的資料來源:
{"splitting":{"percentBegin":50, "percentEnd":75, "complement":"true"}}
模型四:
評估的資料來源:
{"splitting":{"percentBegin":75, "percentEnd":100}}
培訓的資料來源:
{"splitting":{"percentBegin":75, "percentEnd":100, "complement":"true"}}
執行 4 倍交叉驗證會產生四個模型、四個資料來源來訓練模型、四個資料來源來評估模型,以及四個評估,每個模型各一個。Amazon ML 會為每個評估產生模型效能指標。例如,在二元分類問題的 4 倍交叉驗證中,每個評估報告一個曲線下的區域 (AUC) 指標。您可以透過計算這四個 AUC 指標的平均,取得整體效能測量。如需 AUC 指標的相關資訊,請參閱衡量 ML 模型準確性。
如需示範如何建立跨驗證和平均模型分數的範例程式碼,請參閱 Amazon ML 範例程式碼
調整您的模型
交叉驗證模型之後,如果您的模型效能不符合你的標準,您可為下一個模型調整設定。如需過度擬合的詳細資訊,請參閱模型擬合:低度擬合與過度擬合。如需正規化的詳細資訊,請參閱正規化。如需變更正規化設定的詳細資訊,請參閱使用自訂選項建立 ML 模型。
