我們不再更新 Amazon Machine Learning 服務或接受新使用者。本文件可供現有使用者使用,但我們不再更新。如需詳細資訊,請參閱什麼是 Amazon Machine Learning。
本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
資料的深入解析
Amazon ML 會計算輸入資料的描述性統計資料,供您用來了解資料。
描述性統計資料
Amazon ML 會針對不同的屬性類型計算下列描述性統計資料:
數值:
-
色階分佈圖
-
無效值的數量
-
最小值、中間值、平均值與最大值
二元與分類:
-
(每個類別的相異值) 計數
-
數值色階分佈圖
-
最常出現的值
-
不重複的值計數
-
true 值的百分比 (僅限二元)
-
最重要的單字
-
最常出現的單字
文字:
-
屬性的名稱
-
與目標的相互關聯性 (如有設定目標)
-
總字數
-
不重複的文字
-
單一資料列中的字數範圍
-
單字長度範圍
-
最重要的單字
在 Amazon ML 主控台上存取 Data Insights
在 Amazon ML 主控台上,您可以選擇任何資料來源的名稱或 ID,以檢視其 Data Insights 頁面。此頁面提供指標與視覺效果,可讓您了解資料來源相關聯的輸入資料,包括下列資訊:
-
資料摘要
-
目標分佈
-
缺少值
-
無效值
-
變數的摘要統計資料 (依資料類型)
-
變數的分佈 (依資料類型)
下列各節將詳細說明指標與視覺效果。
資料摘要
資料來源的資料摘要報告顯示摘要資訊,包括資料來源 ID、名稱、完成位置、目前的狀態、目標屬性、輸入資料資訊 (S3 儲存貯體位置、資料格式、已處理的記錄數與處理期間發生的錯誤記錄數),以及變數的數量 (依資料類型)。
目標分佈
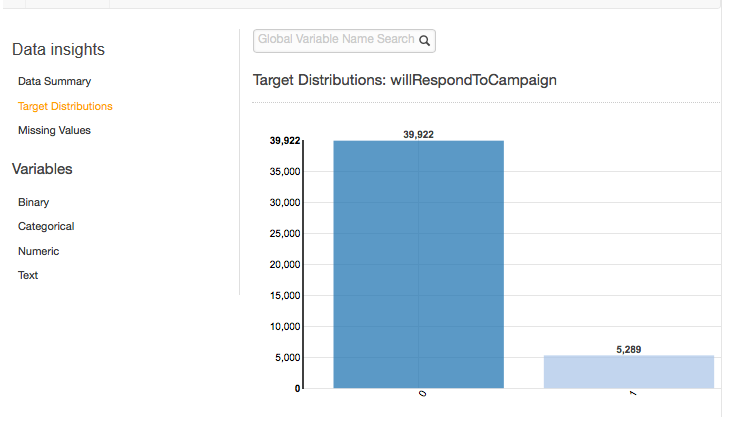
目標分佈報告顯示資料來源的目標屬性分佈。下列範例有 39,922 個觀察,其中的 willRespondToCampaign 目標屬性等於 0。這是未回應電子郵件行銷活動的客戶人數。總共有 5,289 個觀察,其中 willRespondToCampaign 等於 1。這是已回應電子郵件行銷活動的客戶人數。
缺少的值
缺少的值報告會列出輸入資料中缺少值的屬性。只有資料類型為數值的屬性才會缺少值。因為缺少值可能會影響 ML 模型的訓練品質,所以建議您盡可能提供所缺少的值。
在 ML 模型訓練期間,如果遺失目標屬性,Amazon ML 會拒絕對應的記錄。如果目標屬性存在於記錄中,但缺少另一個數值屬性的值,則 Amazon ML 會忽略缺少的值。在此情況下,Amazon ML 會建立替代屬性,並將其設定為 1,以表示缺少此屬性。這可讓 Amazon ML 從遺失值的出現中學習模式。
無效值
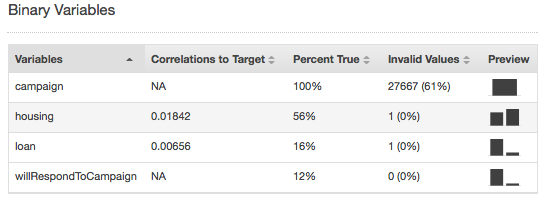
只有數值與二元資料類型才會出現無效值。您可以檢視資料類型報告中的變數摘要統計資料來尋找無效值。在下列範例中,持續時間的數值屬性有一個無效值,二元資料類型有兩個無效值 (分別在房屋屬性與貸款屬性中)。

變數與目標的相互關聯性
建立資料來源之後,Amazon ML 可以評估資料來源,並識別變數與目標之間的相互關聯或影響。例如,產品價格對於能否成為暢銷商品的影響可能很大,但產品大小對於預測的影響可能就很小。
一般會建議在訓練資料中加入愈多的變數愈好。但加入許多對於預測影響很小之變數所帶來的干擾,可能會對您的 ML 模型品質與正確性造成負面影響。
您可以移除訓練模型時影響力很小的變數,藉此改善模型的預測效能。您可以在配方中定義哪些變數可供機器學習程序使用,這是 Amazon ML 的轉換機制。若要進一步了解配方,請參閱機器學習的資料轉換。
屬性的摘要統計資料 (依資料類型)
在資料深入解析報告中,您可以依下列資料類型檢視屬性摘要統計資料:
-
二進位
-
分類
-
數值
-
文字
二元資料類型的摘要統計資料會顯示所有的二元屬性。Correlations to target (與目標的相互關聯性) 資料行會顯示目標資料行與屬性資料行中相同的資訊。Percent true (true 的百分比) 資料行顯示觀察值為 1 的百分比。Invalid values (無效值) 資料行顯示無效值的數目,以及每個屬性的無效值所占百分比。Preview (預覽) 資料行提供每個屬性圖形化分佈的連結。
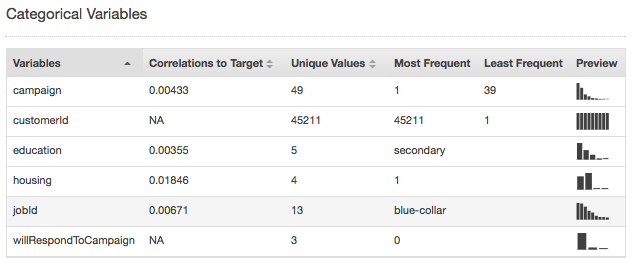
分類資料類型的摘要統計資料顯示所有分類屬性,以及不重複的值、最常出現的值與最少出現的值的數量。Preview (預覽) 資料行提供每個屬性圖形化分佈的連結。
數值資料類型的摘要統計資料顯示所有數值屬性,以及缺少的值、無效值、值的範圍、平均值與中間值的數量。Preview (預覽) 資料行提供每個屬性圖形化分佈的連結。
文字資料類型的摘要統計資料顯示所有的文字屬性、該屬性的總字數、該屬性中不重複的單字數、屬性的字數範圍、單字長度的範圍與最重要的單字。Preview (預覽) 資料行提供每個屬性圖形化分佈的連結。
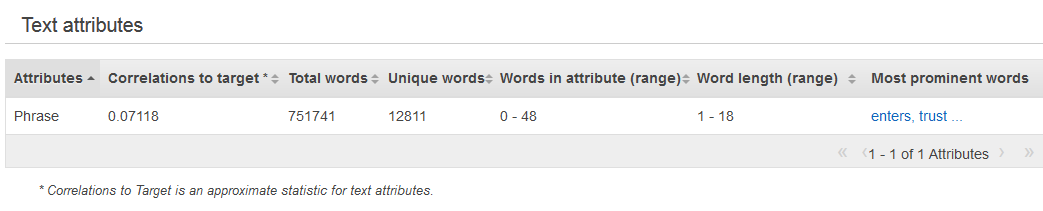
下一個範例顯示文字變數 "review" 的文字資料類型統計資料,其中包含四筆記錄。
1. The fox jumped over the fence. 2. This movie is intriguing. 3. 4. Fascinating movie.
此範例的資料行顯示下列資訊。
-
Attributes (屬性) 資料行顯示變數的名稱。在此範例中,此資料行會顯示 "review"。
-
若已指定目標,才會有 Correlations to target (與目標的相互關聯性) 資料行。相互關聯性測量此屬性所提供與目標相關的資訊量。相互關聯性愈高,此屬性所提供與目標相關的資訊量愈多。相互關聯性在測量文字屬性的簡單表示與目標之間共有的資訊。
-
Total words (總字數) 資料行顯示字符化每筆記錄後所產生的字數,並會以空格分隔每個單字。在此範例中,此資料行會顯示 "12"。
-
Unique words (不重複的單字) 資料行顯示屬性中不重複的單字數。在此範例中,此資料行會顯示 "10"。
-
Words in attribute (range) (屬性中的字數 (範圍)) 資料行顯示屬性之單一資料列中的字數。在此範例中,此資料行會顯示 "0-6"。
-
Word length (range) (單字長度 (範圍)) 資料行顯示單字中的字元數範圍。在此範例中,此資料行會顯示 "2-11"。
-
Most prominent words (最重要的單字) 資料行顯示屬性中出現之單字的排名清單。如有目標屬性,所有單字會依其與目標的相互關聯性排名,亦即,相互關聯性最高的單字會最先列出。若資料中沒有目標,則所有單字會依其熵排名。
了解分類與二元屬性的分佈
您可以按一下與分類或二元屬性相關聯的 Preview (預覽) 連結檢視該屬性的分佈,以及屬性的每一個分類值輸入檔案中的範例資料。
例如,下列螢幕擷取畫面顯示分類屬性 jobId 的分佈。此分佈顯示前 10 個分類值,以及分組為「其他」的所有其他值。其會排名前 10 個分類值,並提供輸入檔案中包含該值的觀察數,以及可檢視輸入資料檔案中範例觀察的連結。
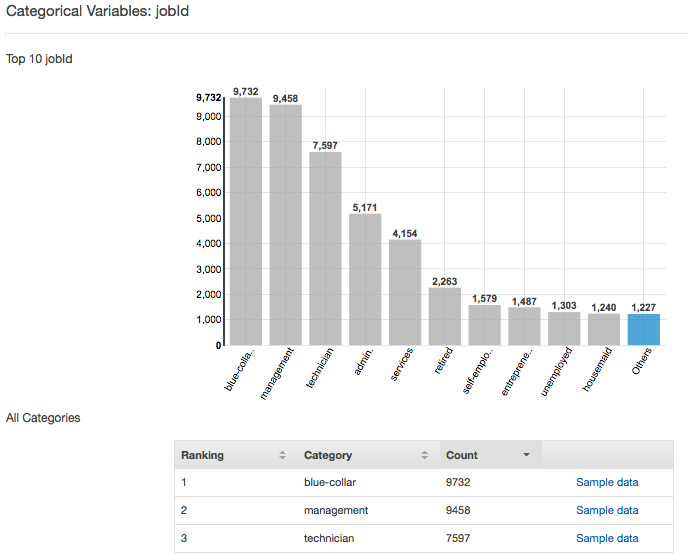
了解數值屬性的分佈
若要檢視數值屬性的分佈,可按一下該屬性的 Preview (預覽) 連結。檢視數值屬性的分佈時,可以選擇量化大小 500、200、100、50 或 20。量化大小愈大,顯示的長條圖數值愈小。此外,量化大小很大的分佈解析度會比較粗糙。反之,若將儲存貯體大小設定為 20,顯示的分佈解析度會相對提升。
此外也會顯示最小值、平均值與最大值,如下列螢幕擷取畫面所示。
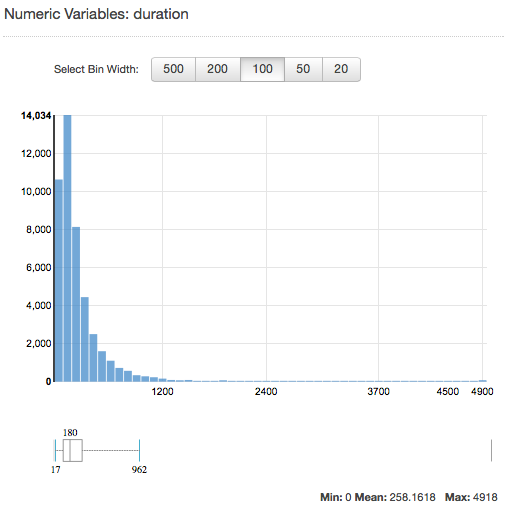
了解文字屬性的分佈
若要檢視文字屬性的分佈,可按一下該屬性的 Preview (預覽) 連結。檢視文字屬性的分佈時,會看到下列資訊。
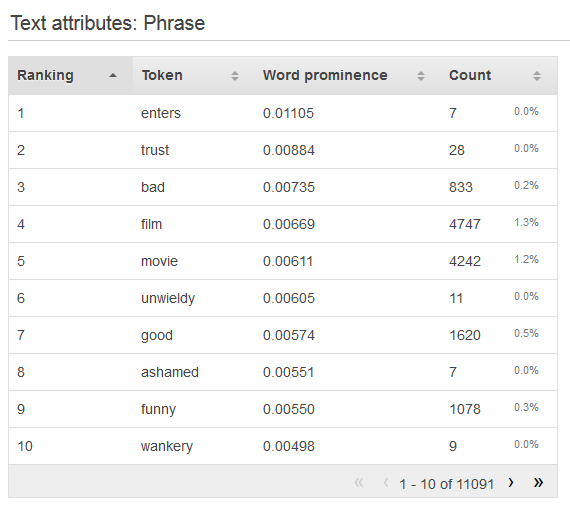
- Ranking (排名)
-
文字字符會依其傳達的資訊量排名,從最多到最少。
- Token (字符)
-
Token (字符) 顯示輸入文字中與統計資料列相關的單文。
- Word prominence (單字重要性)
-
如有目標屬性,文字會依其與目標的相互關聯性排名;因此,相互關聯性最高的文字會最先列出。若資料中沒有目標,則文字會依其熵排名,亦即其可傳達的資訊量。
- Count (計數)
-
Count (計數) 顯示包含此字符之輸入記錄的數量。
- Count percentage (計數百分比)
-
Count Percentage (計數百分比) 顯示字符所在之輸入資料列的百分比。
