我們不再更新 Amazon Machine Learning 服務或接受新使用者。本文件可供現有使用者使用,但我們不再更新。如需詳細資訊,請參閱什麼是 Amazon Machine Learning。
本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
分割您的資料
ML 模型的基本目標是對於用於訓練模型之外的未來資料執行個體,可進行準確的預測。在使用 ML 模型來進行預測之前,我們需要評估模型的預測效能。為了估計 ML 模型對於未知資料的預測品質,我們可以針對現在已知其答案的資料,保留或分割其一部分來做為未來資料的代理,並評估 ML 模型對於該資料預測正確答案的準確程度。您將資料來源分割成一部分做為訓練資料來源,另一部分做為評估資料來源。
Amazon ML 提供三種分割資料的選項:
-
預先分割資料 - 您可以將資料分割成兩個資料輸入位置,然後再將其上傳至 Amazon Simple Storage Service (Amazon S3),並建立兩個單獨的資料來源。
-
Amazon ML 循序分割 - 您可以指示 Amazon ML 在建立訓練和評估資料來源時循序分割資料。
-
Amazon ML 隨機分割 - 您可以在建立訓練和評估資料來源時,指示 Amazon ML 使用種子隨機方法分割資料。
預先分割資料
如果您想明確控制訓練和評估資料來源中的資料,請將您的資料分割為不同的資料位置,並建立輸入和評估位置的不同資料來源。
序列分割資料
分割輸入資料用於訓練和評估的簡單方式,就是選取不重疊的資料子集,同時保留資料記錄的順序。如果您想要評估特定日期或特定時間範圍內的 ML 模型,這個方法非常有用。例如,假設您有過去五個月的客戶互動資料,而且您想要使用此歷史資料來預測下個月的客戶互動。將範圍開頭的資料用於訓練,範圍結束的資料用於評估,可能會比使用從整個資料範圍抽取的資料記錄,能產生更準確的預估值資料。
下圖顯示何時應使用序列分割策略,以及何時應使用隨機策略的範例。
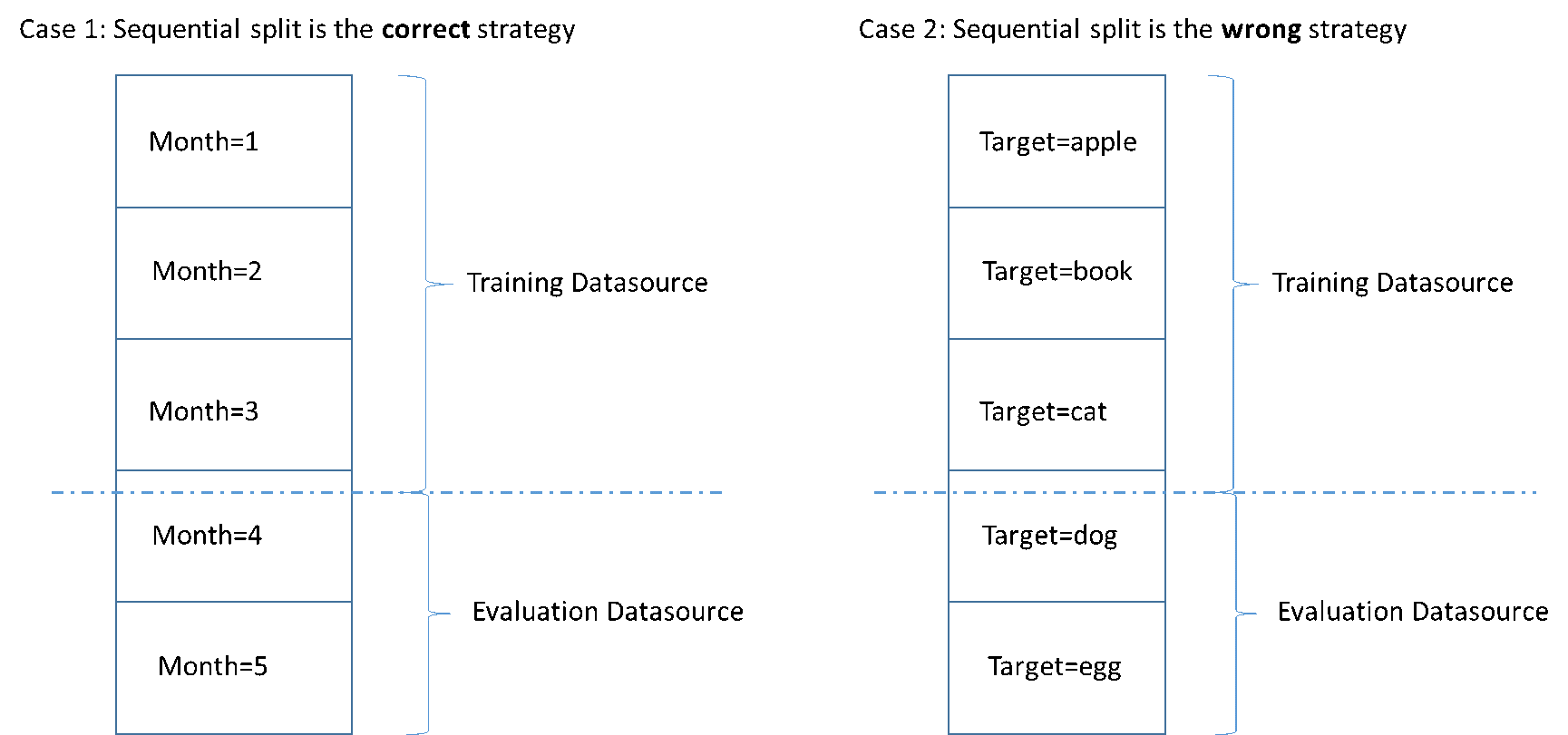
建立資料來源時,您可以選擇依序分割資料來源,Amazon ML 會使用前 70% 的資料進行訓練,其餘 30% 的資料用於評估。這是您使用 Amazon ML 主控台分割資料的預設方法。
隨機分割資料
隨機將輸入資料分割為訓練和評估資料來源,可確保訓練和評估資料來源中的資料分佈類似。當您不需要保留輸入資料的順序,請選擇此選項。
Amazon ML 使用種子虛擬隨機數字產生方法來分割您的資料。種子是部分根據輸入字串值,部分根據資料本身的內容。根據預設,Amazon ML 主控台會使用輸入資料的 S3 位置做為字串。API 使用者可以提供自訂的字串。這表示指定相同的 S3 儲存貯體和資料,Amazon ML 每次都會以相同的方式分割資料。若要變更 Amazon ML 分割資料的方式,您可以使用 CreateDatasourceFromS3、 或 CreateDatasourceFromRDS APICreateDatasourceFromRedshift,並提供種子字串的值。使用這些 API 來建立用於訓練和評估的個別資料來源時,請務必對這兩個資料來源使用相同的種子字串值並對一個資料來源使用補充旗標,以確保訓練和評估資料之間沒有重疊。

開發高品質 ML 模型中常見的陷阱,是在與用於訓練之資料不類似的資料上評估 ML 模型。例如,假設您使用 ML 來預測電影類型,而您的訓練資料包含冒險片、喜劇片以及紀錄片類型的電影。不過,您的評估資料只包含愛情片和驚悚片類型的資料。在這種情況下,ML 模型並未學習到愛情片和驚悚片類型的任何資訊,評估程序也無法評估模型從冒險片、喜劇片以及紀錄片類型的學習程度。因此,類型資訊無用,對於所有類型的 ML 模型預測品質受到損害。模型和評估太過不同 (有非常不同的描述統計資料),因此無用。這可能發生在輸入資料依資料集的某一欄排序,然後依序分割。
如果您的訓練和評估資料來源有不同的資料分佈,您會在模型評估中看到評估提醒。如需評估提醒的詳細資訊,請參閱評估提醒。
如果您已將輸入資料隨機化,例如,在 Amazon S3 中隨機隨機播放輸入資料,或在建立資料來源時使用 Amazon Redshift SQL 查詢的 random()函數或 MySQL SQL 查詢的 rand()函數,則不需要在 Amazon ML 中使用隨機分割。在這些情況下,您可以倚賴序列分割選項來建立具有類似分佈的訓練和評估資料來源。
