本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
向量搜尋功能和限制
向量搜尋可用性
R6g, R7g 和 T4g 節點類型支援啟用向量搜尋的 MemoryDB 組態,並且可在提供 MemoryDB 的所有 AWS 區域中使用。
現有的叢集無法修改以啟用搜尋。不過,啟用搜尋的叢集可以從停用搜尋的叢集快照建立。
參數限制
下表顯示各種向量搜尋項目的限制:
| 項目 | 最大值 |
|---|---|
| 向量中的維度數量 | 32768 |
| 可建立的索引數量 | 10 |
| 索引中的欄位數目 | 50 |
| FT.SEARCH 和 FT.AGGREGATE TIMEOUT 子句 (毫秒) | 10000 |
| FT.AGGREGATE 命令中的管道階段數量 | 32 |
| FT.AGGREGATE LOAD 子句中的欄位數目 | 1024 |
| FT.AGGREGATE GROUPBY 子句中的欄位數目 | 16 |
| FT.AGGREGATE SORTBY 子句中的欄位數目 | 16 |
| FT.AGGREGATE PARAM 子句中的參數數目 | 32 |
| HNSW M 參數 | 512 |
| HNSW EF_CONSTRUCTION 參數 | 4096 |
| HNSW EF_RUNTIME 參數 | 4096 |
擴展限制
MemoryDB 的向量搜尋目前僅限於單一碎片,不支援水平擴展。向量搜尋支援垂直和複本擴展。
操作限制
索引持久性和回填
向量搜尋功能會保留索引的定義,以及索引的內容。這表示在任何導致節點啟動或重新啟動的操作請求或事件期間,索引定義和內容會從最新的快照還原,而任何待定交易都會從多可用區域交易日誌中讀取。不需要使用者動作即可啟動此動作。一旦資料還原,重建就會以回填操作的形式執行。這在功能上等同於系統自動為每個定義的索引執行 FT.CREATE 命令。請注意,一旦還原資料,但可能在索引回填完成之前,節點就可供應用程式操作使用,這表示應用程式會再次看到回填 (例如,使用回填索引的搜尋命令可能會遭拒)。如需回填的詳細資訊,請參閱 向量搜尋概觀。
索引回填的完成不會在主要和複本之間同步。應用程式可能會意外看到這種缺乏同步的情況,因此建議應用程式在啟動搜尋操作之前,先驗證主要和所有複本上的回填完成。
快照匯入/匯出和即時遷移
RDB 檔案中是否存在搜尋索引會限制該資料的相容可傳輸性。只有另一個啟用 MemoryDB 向量的叢集才能了解 MemoryDB 向量搜尋功能定義的向量索引格式。此外,預覽叢集的 RDB 檔案可由 MemoryDB 叢集的 GA 版本匯入,這會在載入 RDB 檔案時重建索引內容。
不過,不包含索引的 RDB 檔案不會以此方式受到限制。因此,在匯出之前刪除索引,可將預覽叢集內的資料匯出至非預覽叢集。
記憶體使用量
記憶體耗用取決於向量數量、維度數量、M 值和非向量資料數量,例如與向量相關聯的中繼資料或存放在執行個體中的其他資料。
所需的總記憶體是實際向量資料所需的空間,以及向量索引所需的空間的組合。向量資料所需的空間是透過測量在 HASH 或 JSON 資料結構中存放向量所需的實際容量,以及對最接近記憶體板的額外負荷來計算,以獲得最佳記憶體配置。每個向量索引使用對存放在這些資料結構中的向量資料的參考,並使用有效的記憶體最佳化來移除索引中向量資料的任何重複副本。
向量數量取決於您決定將資料表示為向量的方式。例如,您可以選擇將單一文件表示為數個區塊,其中每個區塊代表向量。或者,您可以選擇將整個文件表示為單一向量。
向量的維度取決於您選擇的內嵌模型。例如,如果您選擇使用 AWS Titan
M 參數代表索引建構期間為每個新元素建立的雙向連結數目。MemoryDB 將此值預設為 16;不過,您可以覆寫此值。較高的 M 參數較適用於高維度和/或高回收需求,而低 M 參數較適用於低維度和/或低回收需求。隨著索引變大,M 值會增加記憶體的消耗量,進而增加記憶體消耗量。
在主控台體驗中,MemoryDB 可根據向量工作負載的特性,在叢集設定下勾選啟用向量搜尋後,提供簡單的方式來選擇正確的執行個體類型。
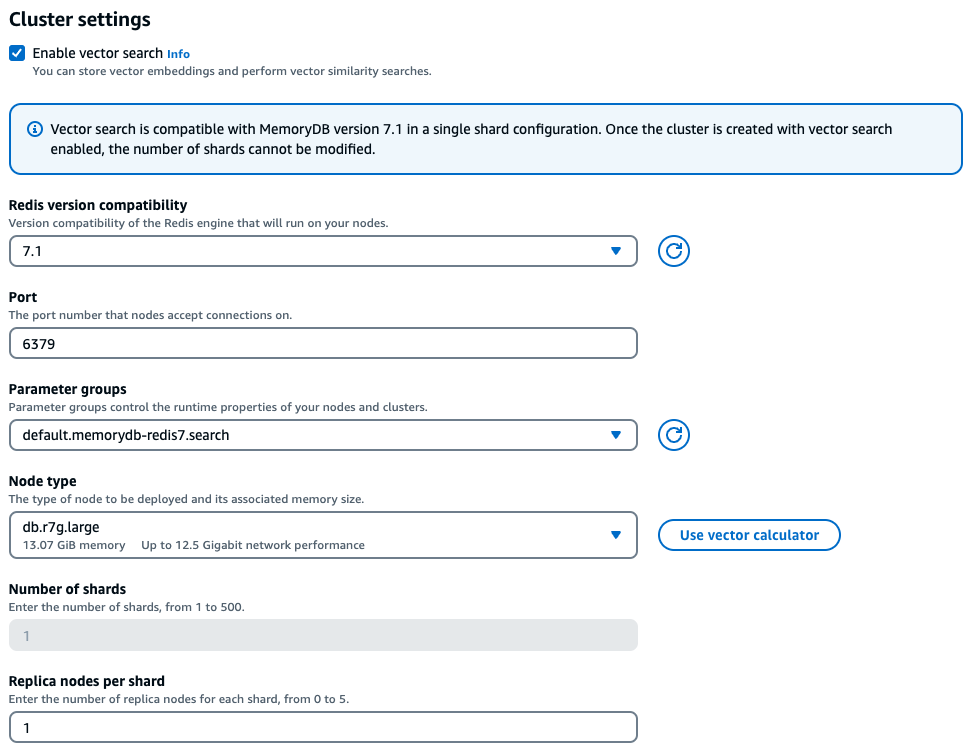
範例工作負載
客戶想要建置以內部財務文件為基礎的語意搜尋引擎。他們目前擁有 1M份財務文件,這些文件使用具有 1536 個維度的 titan 內嵌模型,每個文件分成 10 個向量,而且沒有非向量資料。客戶決定使用預設值 16 做為 M 參數。
向量:1 M * 10 區塊 = 10M 向量
維度:1536
非向量資料 (GB):0 GB
M 參數:16
透過此資料,客戶可以按一下主控台中的使用向量計算器按鈕,根據其參數取得建議的執行個體類型:
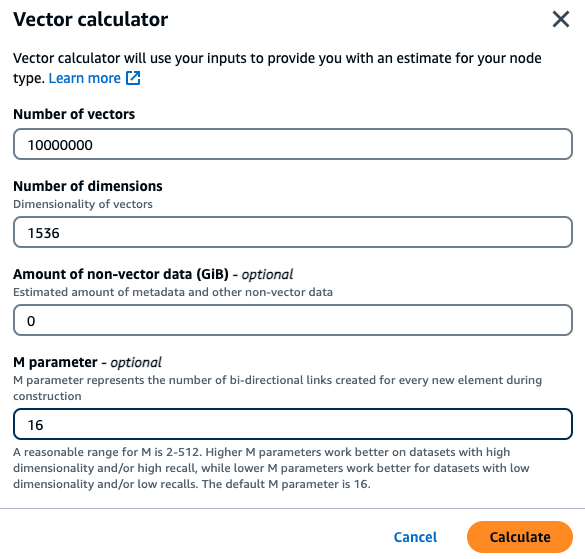

在此範例中,向量計算器會尋找最小的 MemoryDB r7g 節點類型
根據上述計算方法和範例工作負載中的參數,此向量資料需要 104.9 GB 才能存放資料和單一索引。在此情況下,建議使用db.r7g.4xlarge執行個體類型,因為它有 105.81 GB 的可用記憶體。下一個最小節點類型太小,無法容納向量工作負載。
由於每個向量索引都使用所存放向量資料的參考,而且不會在向量索引中建立向量資料的額外副本,因此索引也會耗用相對較少的空間。這在建立多個索引時非常有用,在已刪除部分向量資料且重建 HNSW 圖形的情況下,也有助於為高品質向量搜尋結果建立最佳節點連線。
回填期間記憶體不足
與 Valkey 和 Redis OSS 寫入操作類似,索引回填會out-of-memory的限制。如果在回填進行時填滿引擎記憶體,則會暫停所有回填。如果記憶體可用,則會繼續回填程序。當回填因記憶體不足而暫停時,也可以刪除和編製索引。
交易
命令 FT.CREATE、FT.DROPINDEX、FT.ALIASDEL、 FT.ALIASADD和 FT.ALIASUPDATE無法在交易內容中執行,即不在 MULTI/EXEC 區塊內或在 LUA 或 FUNCTION 指令碼內。
