本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
如何使用 Neptune ML 特徵的概觀
Amazon Neptune 中的 Neptune ML 功能提供簡化的工作流程,以利用圖形資料庫中的機器學習模型。此程序涉及幾個關鍵步驟:將資料從 Neptune 匯出為 CSV 格式、預先處理資料以準備模型訓練、使用 Amazon SageMaker AI 訓練機器學習模型、建立推論端點以提供預測,然後直接從 Gremlin 查詢查詢模型。Neptune 工作台提供便利的明細和儲存格魔術命令,以協助管理和自動化這些步驟。透過將機器學習功能直接整合到圖形資料庫中,Neptune ML 可讓使用者衍生寶貴的洞見,並使用儲存在 Neptune 圖形中的豐富關聯式資料進行預測。
啟動使用 Neptune ML 的工作流程
在 Amazon Neptune 中使用 Neptune ML 功能通常涉及以下五個步驟以開始:
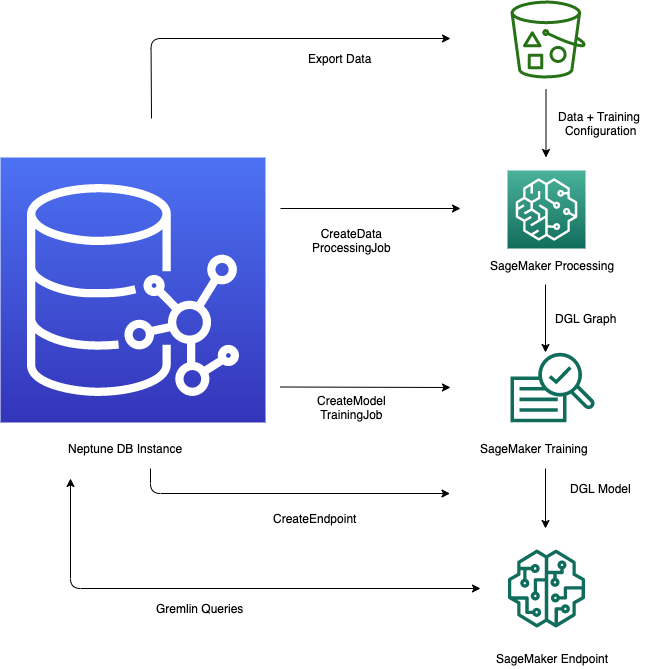
-
資料匯出和組態 – 資料匯出步驟會使用 Neptune-Export 服務或
neptune-export命令列工具,以 CSV 格式將資料從 Neptune 匯出至 Amazon Simple Storage Service (Amazon S3)。名為training-data-configuration.json的組態檔案會同時自動產生,指定如何將匯出的資料載入至可訓練的圖形。 -
資料預先處理 – 在此步驟中,匯出的資料集會使用標準技術預先處理,以準備進行模型訓練。可針對數值資料執行特徵標準化,並可以使用
word2vec編碼文字特徵。在此步驟結束時,會從匯出的資料集產生 DGL (Deep Graph Library) 圖形,供模型訓練步驟使用。此步驟是使用您帳戶中的 SageMaker AI 處理任務來實作,產生的資料會存放在您指定的 Amazon S3 位置。
-
模型訓練 – 模型訓練步驟會訓練將用於預測的機器學習模型。
模型訓練分兩個階段完成:
第一階段使用 SageMaker AI 處理任務來產生模型訓練策略組態集,指定要用於模型訓練的模型和模型超參數範圍類型。
第二階段接著使用 SageMaker AI 模型調校任務來嘗試不同的超參數組態,然後選取產生最佳效能模型的訓練任務。調整工作會對已處理的資料執行預先指定數量的模型訓練工作試驗。在此階段結束時,會使用最佳訓練工作的訓練模型參數,產生用於推論的模型成品。
-
在 Amazon SageMaker AI 中建立推論端點 – 推論端點是使用最佳訓練任務產生的模型成品啟動的 SageMaker AI 端點執行個體。每個模型都繫結至單一端點。端點能夠接受來自圖形資料庫的傳入請求,並傳回請求中輸入的模型預測。在您建立端點之後,它會保持作用中狀態,直到您將其刪除為止。
使用 Gremlin 查詢機器學習模型 – 您可以使用 Gremlin 查詢語言的延伸模組,從推論端點查詢預測。
注意
Neptune 工作台包含一個行魔法和一個儲存格魔法,其可以為您節省管理這些步驟的大量時間,即:
