本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
教學課程:使用 Amazon OpenSearch Ingestion 將資料擷取至集合
本教學課程說明如何使用 Amazon OpenSearch Ingestion 設定簡單的管道,並將資料擷取至 Amazon OpenSearch Serverless 集合。管道是 OpenSearch Ingestion 佈建和管理的資源。您可以使用管道來篩選、擴充、轉換、標準化和彙總資料,以在 OpenSearch Service 中進行下游分析和視覺化。
如需示範如何將資料擷取到佈建 OpenSearch Service 網域的教學課程,請參閱 教學課程:使用 Amazon OpenSearch Ingestion 將資料擷取至網域。
您將完成本教學課程中的下列步驟:。
在教學課程中,您將建立下列資源:
-
管道將寫入
ingestion-collection的名為 的集合 -
名為 的管道
ingestion-pipeline-serverless
所需的許可
若要完成本教學課程,您的使用者或角色必須具有具有下列最低許可的連接身分型政策。這些許可可讓您建立管道角色並連接政策 (iam:Create* 和 )iam:Attach*、建立或修改集合 (aoss:*),以及使用管道 ()osis:*。
此外,需要數個 IAM 許可,才能自動建立管道角色並將其傳遞給 OpenSearch Ingestion,以便將資料寫入集合。
步驟 1:建立集合
首先,建立要擷取資料的集合。我們將集合命名為 ingestion-collection。
-
導覽至 Amazon OpenSearch Service 主控台,網址為 https://https://console.aws.amazon.com/aos/home
。 -
從左側導覽中選擇集合,然後選擇建立集合。
-
在無伺服器產生欄位中,選擇切換到傳統。
-
命名集合擷取集合。
-
針對安全性,選擇標準建立。
-
在網路存取設定下,將存取類型變更為公有。
-
將其他所有設定保留為預設值,然後選擇 Next (下一步)。
-
現在,為集合設定資料存取政策。取消選取自動比對存取政策設定。
-
針對定義方法,選擇 JSON,並將下列政策貼到編輯器中。此政策會執行兩個動作:
-
允許管道角色寫入集合。
-
可讓您從集合讀取 。稍後,在您將一些範例資料擷取至管道後,您將查詢集合,以確保資料已成功擷取並寫入索引。
[ { "Rules": [ { "Resource": [ "index/ingestion-collection/*" ], "Permission": [ "aoss:CreateIndex", "aoss:UpdateIndex", "aoss:DescribeIndex", "aoss:ReadDocument", "aoss:WriteDocument" ], "ResourceType": "index" } ], "Principal": [ "arn:aws:iam::your-account-id:role/OpenSearchIngestion-PipelineRole", "arn:aws:iam::your-account-id:role/Admin" ], "Description": "Rule 1" } ]
-
-
修改
Principal元素以包含您的 AWS 帳戶 ID。針對第二個委託人,指定可用於稍後查詢集合的使用者或角色。 -
選擇下一步。命名存取政策pipeline-collection-access,然後再次選擇下一步。
-
檢閱集合組態,然後選擇 Submit (提交)。
步驟 2:建立管道
現在您已擁有集合,您可以建立管道。
建立管道
-
在 Amazon OpenSearch Service 主控台中,從左側導覽窗格中選擇管道。
-
選擇 Create pipeline (建立管道)。
-
選取空白管道,然後選擇選取藍圖。
-
在本教學課程中,我們將建立使用 HTTP 來源
外掛程式的簡單管道。外掛程式接受 JSON 陣列格式的日誌資料。我們將指定單一 OpenSearch Serverless 集合做為接收器,並將所有資料擷取至 my_logs索引。在來源功能表中,選擇 HTTP。在路徑中,輸入 /logs。
-
為了簡化本教學課程,我們將設定管道的公有存取。針對來源網路選項,選擇公開存取。如需設定 VPC 存取的資訊,請參閱 設定 Amazon OpenSearch Ingestion 管道的 VPC 存取。
-
選擇下一步。
-
針對處理器,輸入日期,然後選擇新增。
-
啟用從接收到的時間。將所有其他設定保留為預設值。
-
選擇下一步。
-
設定接收器詳細資訊。針對 OpenSearch 資源類型,選擇集合 (無伺服器)。然後選擇您在上一節中建立的 OpenSearch Service 集合。
將網路政策名稱保留為預設值。針對索引名稱,輸入 my_logs。如果集合中尚不存在,OpenSearch Ingestion 會自動建立此索引。
-
選擇下一步。
-
命名管道 ingestion-pipeline-serverless。將容量設定保留為預設值。
-
針對管道角色,選取建立並使用新的服務角色。管道角色為管道提供寫入集合目的地並從提取型來源讀取所需的許可。透過選取此選項,您可以允許 OpenSearch Ingestion 為您建立角色,而不是在 IAM 中手動建立角色。如需詳細資訊,請參閱在 Amazon OpenSearch 擷取中設定角色和使用者。
-
針對服務角色名稱尾碼,輸入 PipelineRole。在 IAM 中,角色的格式為
arn:aws:iam::。your-account-id:role/OpenSearchIngestion-PipelineRole -
選擇下一步。檢閱您的管道組態,然後選擇建立管道。管道需要 5-10 分鐘才會變成作用中。
步驟 3:擷取一些範例資料
當管道狀態為 時Active,您可以開始將資料導入其中。您必須使用 Signature 第 4 版簽署管道的所有 HTTP 請求。使用 Postman
注意
簽署請求的委託人必須具有 osis:Ingest IAM 許可。
首先,從管道設定頁面取得擷取 URL:
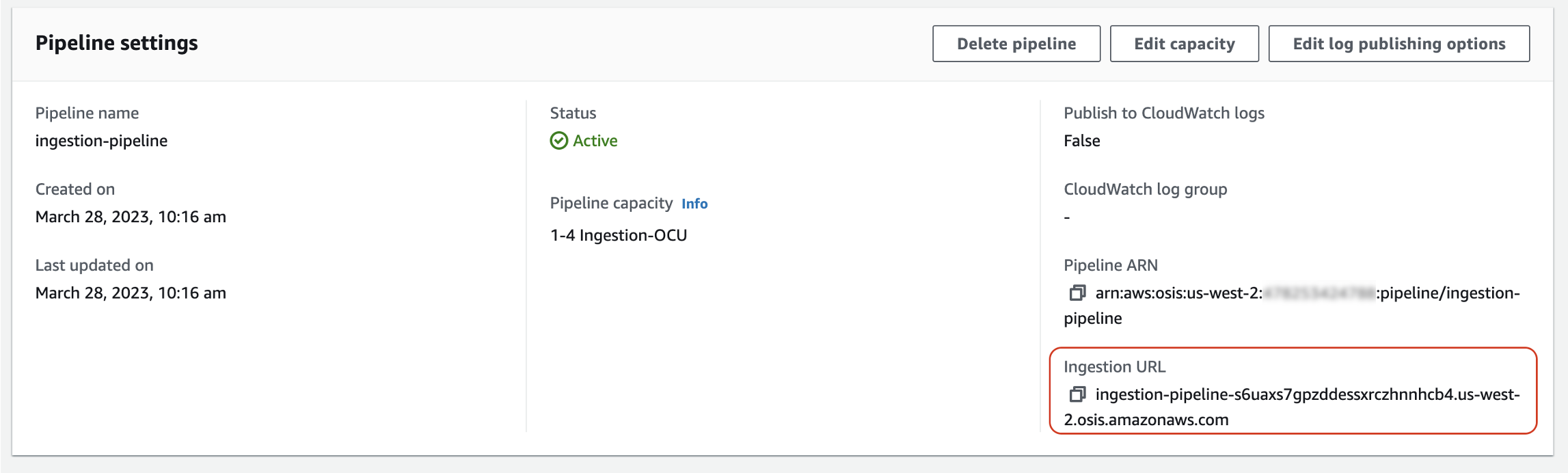
然後,將一些範例資料傳送至擷取路徑。下列範例請求使用 awscurl
awscurl --service osis --regionus-east-1\ -X POST \ -H "Content-Type: application/json" \ -d '[{"time":"2014-08-11T11:40:13+00:00","remote_addr":"122.226.223.69","status":"404","request":"GET http://www.k2proxy.com//hello.html HTTP/1.1","http_user_agent":"Mozilla/4.0 (compatible; WOW64; SLCC2;)"}]' \ https://pipeline-endpoint.us-east-1.osis.amazonaws.com/logs
您應該會看到200 OK回應。
現在,請查詢my_logs索引,以確保已成功擷取日誌項目:
awscurl --service aoss --regionus-east-1\ -X GET \ https://collection-id.us-east-1.aoss.amazonaws.com/my_logs/_search | json_pp
回應範例:
{ "took":348, "timed_out":false, "_shards":{ "total":0, "successful":0, "skipped":0, "failed":0 }, "hits":{ "total":{ "value":1, "relation":"eq" }, "max_score":1.0, "hits":[ { "_index":"my_logs", "_id":"1%3A0%3ARJgDvIcBTy5m12xrKE-y", "_score":1.0, "_source":{ "time":"2014-08-11T11:40:13+00:00", "remote_addr":"122.226.223.69", "status":"404", "request":"GET http://www.k2proxy.com//hello.html HTTP/1.1", "http_user_agent":"Mozilla/4.0 (compatible; WOW64; SLCC2;)", "@timestamp":"2023-04-26T05:22:16.204Z" } } ] } }
相關資源
本教學課程提供透過 HTTP 擷取單一文件的簡單使用案例。在生產案例中,您將設定用戶端應用程式 (例如 Fluent Bit、Kubernetes 或 OpenTelemetry Collector),以將資料傳送至一或多個管道。您的管道可能比本教學課程中的簡單範例更複雜。
若要開始設定用戶端和擷取資料,請參閱下列資源:
