本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
什麼是 Amazon OpenSearch Serverless?
Amazon OpenSearch Serverless 是 Amazon OpenSearch Service 的隨需無伺服器選項,可消除佈建、設定和調校 OpenSearch 叢集的操作複雜性。對於偏好不自我管理叢集或缺乏專用資源和專業知識來操作大規模部署的組織來說,這是理想的選擇。使用 OpenSearch Serverless,您可以搜尋和分析大量資料,而無需管理基礎基礎設施。
OpenSearch Serverless 集合是一組 OpenSearch 索引,可共同運作以支援特定工作負載或使用案例。相較於需要手動佈建的自我管理 OpenSearch 叢集,集合可簡化操作。
集合使用與佈建 OpenSearch Service 網域相同的高容量、分散式和高可用性儲存體,但透過消除手動組態和調校來進一步降低複雜性。集合內的資料會在傳輸中加密。OpenSearch Serverless 也支援 OpenSearch Dashboards,提供用於資料分析的介面。
OpenSearch Serverless 與開放原始碼 OpenSearch 相容。隨著新版本發佈,OpenSearch Serverless 會自動升級集合,以整合新功能、錯誤修正和效能改善。
OpenSearch Serverless 支援與 OpenSearch 開放原始碼套件相同的擷取和查詢 API 操作,因此您可以繼續使用現有的用戶端和應用程式。您的用戶端必須與 OpenSearch 3.x 相容,才能使用 OpenSearch Serverless。如需詳細資訊,請參閱將資料擷取至 Amazon OpenSearch Serverless 集合。
OpenSearch Serverless 使用案例
OpenSearch Serverless 支援兩種主要使用案例:
-
日誌分析:日誌分析區段專注於分析大量半結構化、機器產生的時間序列資料,以提供操作和使用者行為洞察。
-
全文檢索搜尋:全文檢索搜尋區段強化內部網路中的應用程式 (內容管理系統、法律文件) 以及面向網際網路的應用程式,例如電子商務網站內容搜尋。
建立集合時,您可以選擇上述其中一種使用案例。如需詳細資訊,請參閱選擇集合類型。
運作方式
傳統 OpenSearch 叢集有一組執行個體,可執行索引編製和搜尋操作,而索引儲存與運算容量緊密結合。相反地,OpenSearch Serverless 使用雲端原生架構,將索引 (擷取) 元件與搜尋 (查詢) 元件分開,並將 Amazon S3 作為索引的主要資料儲存體。
此分開的架構可讓您獨立擴展搜尋和索引編製功能,並且獨立於 S3 中的索引資料。該架構也會隔離擷取和查詢操作,以便同時執行這兩項操作,而不會爭用資源。
將資料寫入集合時,OpenSearch Serverless 會將資料分發到索引編製運算單元。索引編製運算單元會擷取傳入資料,並將索引移至 S3。對集合資料執行搜尋時,OpenSearch Serverless 會將請求路由至容納所查詢資料的搜尋運算單元。搜尋運算單元會直接從 S3 下載索引資料 (如果尚未在本機快取資料)、執行搜尋操作並執行彙總。
下圖說明了此分開的架構:
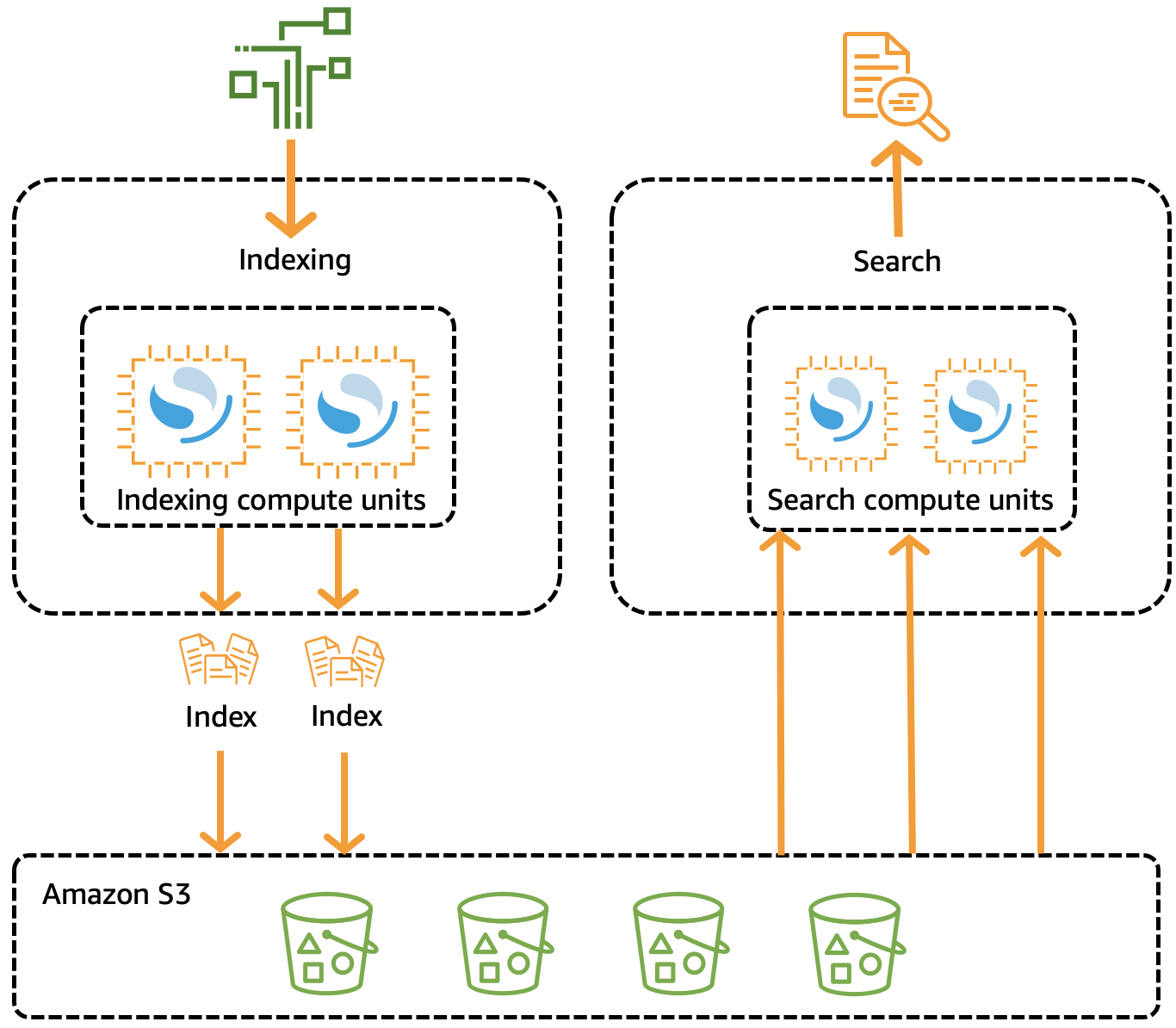
用於資料擷取、搜尋和查詢的 OpenSearch Serverless 運算容量是以 OpenSearch 運算單元 (OCU) 來測量。每個 OCU 都是 6 GiB 記憶體和對應虛擬 CPU (vCPU) 的組合,並會建立 Amazon S3 的資料管道。
OpenSearch Serverless 會分別佈建 OCUs以進行搜尋和索引。OpenSearch Serverless 只會根據您指定的容量限制,視需要新增其他 OCUs 進行搜尋和擷取以支援集合。容量會隨著運算用量的減少而縮減。
如需如何支付這些 OCUs 費用的資訊,請參閱 Amazon OpenSearch Service 定價
選擇集合類型
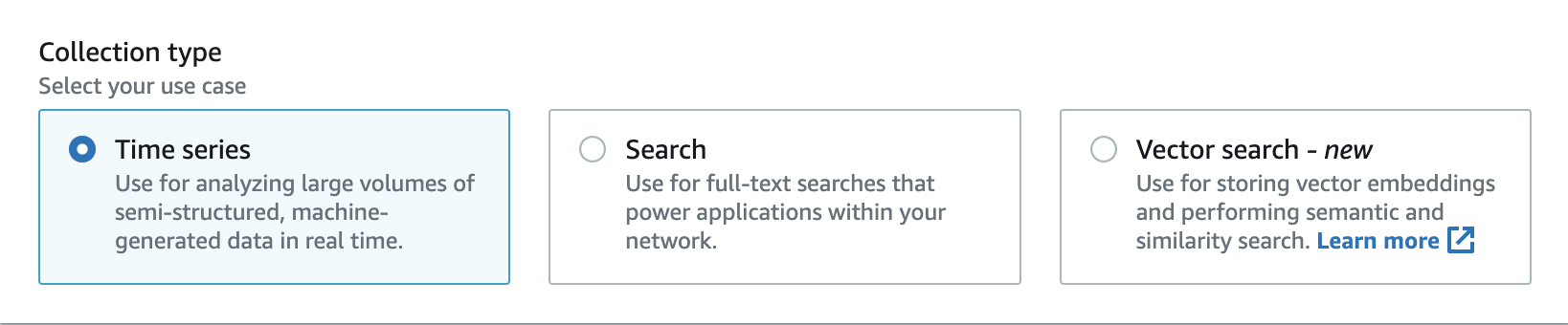
OpenSearch Serverless 支援三種主要集合類型:
時間序列 – 日誌分析區段,可即時分析大量半結構化、機器產生的資料,提供操作、安全性、使用者行為和業務效能的洞見。
注意
時間序列集合僅適用於 Classic 集合。NextGen 集合目前僅支援搜尋和向量搜尋類型。
搜尋 – 啟用內部網路內應用程式的全文搜尋,例如內容管理系統和法律文件儲存庫,以及電子商務網站搜尋和內容探索等面向網際網路的應用程式。
向量搜尋 – 向量內嵌的語意搜尋可簡化向量資料管理,並啟用機器學習 (ML) 擴增搜尋體驗。它支援生成式 AI 應用程式,例如聊天機器人、個人助理和詐騙偵測。
您可以在第一次建立集合時選擇集合類型:
您選擇的集合類型取決於您計劃擷取至集合的資料類型,以及計劃的查詢方式。您無法在建立後變更集合類型。
集合類型有以下顯著差異:
-
對於搜尋和向量搜尋集合,所有資料都會存放在熱儲存體中,以確保快速的查詢回應時間。時間序列集合使用熱儲存和暖儲存組合,其中最新的資料會保留在熱儲存中,以優化更頻繁存取資料的查詢回應時間。
-
對於時間序列集合,您無法依自訂文件 ID 編製索引,也無法依 upsert 請求更新。此操作保留給搜尋使用案例。您可以改為依文件 ID 更新。如需詳細資訊,請參閱支援的 OpenSearch API 操作與許可。
-
對於搜尋和時間序列集合,您無法使用 k-NN 類型索引。
支援的 AWS 區域
OpenSearch Serverless 可在 AWS 區域 OpenSearch Service 提供的子集中使用。如需支援區域的清單,請參閱《》中的 Amazon OpenSearch Service 端點和配額AWS 一般參考。
限制
OpenSearch Serverless 具有下列限制:
-
不支援某些 OpenSearch API 操作。請參閱 支援的 OpenSearch API 操作與許可。
-
不支援某些 OpenSearch 外掛程式。請參閱 支援的 OpenSearch 外掛程式。
-
目前無法將您的資料從受管的 OpenSearch Service 網域自動遷移至無伺服器集合。您必須將資料從網域重新索引至集合。
-
不支援集合的跨帳户存取權。您無法在加密或資料存取政策中包含其他帳戶的集合。
-
不支援自訂 OpenSearch 外掛程式。
-
OpenSearch Serverless 集合支援自動化快照。不支援手動快照。如需詳細資訊,請參閱使用快照備份集合。
-
不支援跨區域搜尋和複寫。
-
您可以在單一帳戶和區域中擁有的無伺服器資源數量有限制。請參閱 OpenSearch Serverless 配額。
-
搜尋和時間序列集合中索引的重新整理間隔約為 10 秒。
-
碎片數量、間隔數量和重新整理間隔不可修改,並由 OpenSearch Serverless 處理。碎片策略是以集合類型和流量為基礎。例如,時間序列集合會根據寫入流量瓶頸擴展主要碎片。
