本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
發佈和檢視結果
Amazon Personalize 化將每個指標的報告發送到 CloudWatch 或 Amazon S3:
-
對於 PutEvents 資料和增量大量資料,Amazon Personalize 會自動將指標傳送到 CloudWatch。如需在中檢視和識別報告的資訊 CloudWatch,請參閱檢視量度 CloudWatch。
-
對於所有大量資料,如果您在建立指標歸因時提供 Amazon S3 儲存貯體,則可以選擇在每次為互動資料建立資料集匯入任務時,將指標報告發佈到 Amazon S3 儲存貯體。
如需將指標報告發佈到 Amazon S3 的資訊,請參閱將指標發佈到 Amazon S3。
檢視量度 CloudWatch
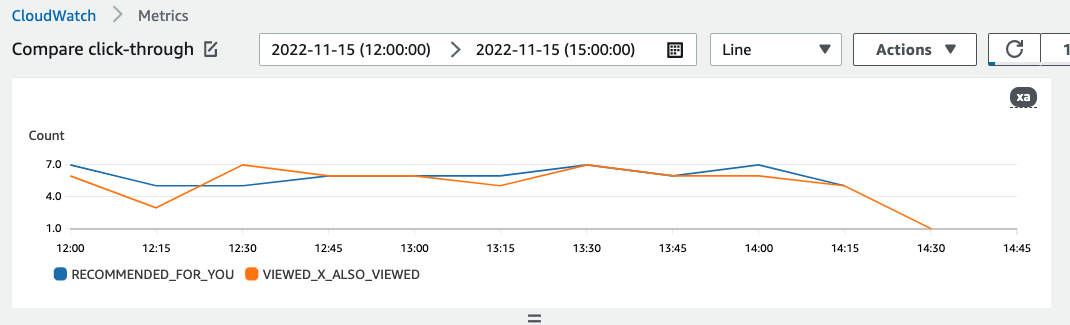
若要在中檢視度量 CloudWatch,請完成繪製測量結果圖形中的程序。您可以繪製的最小期間為 15 分鐘。對於搜尋字詞,請指定您在建立量度歸因時提供的量度名稱。
以下是量度可能在中顯示的範例 CloudWatch。量度會顯示兩個不同推薦人每 15 分鐘的點進率。
將指標發佈到 Amazon S3
若要將指標發佈到 Amazon S3,您可以在指標歸因中提供指向 Amazon S3 儲存貯體的路徑。然後,您可以在建立資料集匯入任務時將報表發佈到 Amazon S3。
任務完成後,您可以在 Amazon S3 儲存貯體中找到指標。每次發佈指標時,Amazon Personalize 都會在您的 Amazon S3 儲存貯體中建立一個新檔案。檔案名稱包括匯入方法和日期,如下所示:
AggregatedAttributionMetrics - ImportMethod -
Timestamp.csv
以下是量度報表 CSV 檔案前幾列可能顯示方式的範例。此範例中的量度會報告兩個不同推薦人在 15 分鐘間隔內的總點擊次數。每個推薦人在「事件 _ 屬性 _ 來源」欄中以其 Amazon 資源名稱 (ARN) 識別。
METRIC_NAME,EVENT_TYPE,VALUE,MATH_FUNCTION,EVENT_ATTRIBUTION_SOURCE,TIMESTAMP
COUNTWATCHES,WATCH,12.0,samplecount,arn:aws:personalize:us-west-2:acctNum:recommender/recommender1Name,1666925124
COUNTWATCHES,WATCH,112.0,samplecount,arn:aws:personalize:us-west-2:acctNum:recommender/recommender2Name,1666924224
COUNTWATCHES,WATCH,10.0,samplecount,arn:aws:personalize:us-west-2:acctNum:recommender/recommender1Name,1666924224
COUNTWATCHES,WATCH,254.0,samplecount,arn:aws:personalize:us-west-2:acctNum:recommender/recommender2Name,1666922424
COUNTWATCHES,WATCH,112.0,samplecount,arn:aws:personalize:us-west-2:acctNum:recommender/recommender1Name,1666922424
COUNTWATCHES,WATCH,100.0,samplecount,arn:aws:personalize:us-west-2:acctNum:recommender/recommender2Name,1666922424
......
.....
將大量資料的指標發佈到 Amazon S3 (主控台)
若要使用 Amazon Personalize 主控台將指標發佈到 Amazon S3 儲存貯體,請建立資料集匯入任務,然後在將事件指標發佈到 S3 中為此匯入任務選擇發佈指標。
如需 step-by-step 指示,請參閱匯入大量記錄 (主控台)。
將大量資料的指標發佈到 Amazon S3 (AWS CLI)
若要使用 AWS Command Line Interface (AWS CLI) 將指標發佈到 Amazon S3 儲存貯體,請使用下列程式碼建立資料集匯入任務並提供publishAttributionMetricsToS3旗標。如果您不想發佈特定工作的量度,請省略旗標。如需每個參數的資訊,請參閱CreateDatasetImportJob。
aws personalize create-dataset-import-job \
--job-name dataset import job name \
--dataset-arn dataset arn \
--data-source dataLocation=s3://bucketname/filename \
--role-arn roleArn \
--import-mode INCREMENTAL \
--publish-attribution-metrics-to-s3
將大量資料的指標發佈到 Amazon S3 (AWS 開發套件)
若要使用 AWS 開發套件將指標發佈到 Amazon S3 儲存貯體,請建立資料集匯入任務並設定publishAttributionMetricsToS3為 true。如需每個參數的資訊,請參閱CreateDatasetImportJob。
- SDK for Python (Boto3)
-
import boto3
personalize = boto3.client('personalize')
response = personalize.create_dataset_import_job(
jobName = 'YourImportJob',
datasetArn = 'dataset_arn',
dataSource = {'dataLocation':'s3://bucket/file.csv'},
roleArn = 'role_arn',
importMode = 'INCREMENTAL',
publishAttributionMetricsToS3 = True
)
dsij_arn = response['datasetImportJobArn']
print ('Dataset Import Job arn: ' + dsij_arn)
description = personalize.describe_dataset_import_job(
datasetImportJobArn = dsij_arn)['datasetImportJob']
print('Name: ' + description['jobName'])
print('ARN: ' + description['datasetImportJobArn'])
print('Status: ' + description['status'])
- SDK for Java 2.x
-
public static String createPersonalizeDatasetImportJob(PersonalizeClient personalizeClient,
String jobName,
String datasetArn,
String s3BucketPath,
String roleArn,
ImportMode importMode,
boolean publishToS3) {
long waitInMilliseconds = 60 * 1000;
String status;
String datasetImportJobArn;
try {
DataSource importDataSource = DataSource.builder()
.dataLocation(s3BucketPath)
.build();
CreateDatasetImportJobRequest createDatasetImportJobRequest = CreateDatasetImportJobRequest.builder()
.datasetArn(datasetArn)
.dataSource(importDataSource)
.jobName(jobName)
.roleArn(roleArn)
.importMode(importMode)
.publishAttributionMetricsToS3(publishToS3)
.build();
datasetImportJobArn = personalizeClient.createDatasetImportJob(createDatasetImportJobRequest)
.datasetImportJobArn();
DescribeDatasetImportJobRequest describeDatasetImportJobRequest = DescribeDatasetImportJobRequest.builder()
.datasetImportJobArn(datasetImportJobArn)
.build();
long maxTime = Instant.now().getEpochSecond() + 3 * 60 * 60;
while (Instant.now().getEpochSecond() < maxTime) {
DatasetImportJob datasetImportJob = personalizeClient
.describeDatasetImportJob(describeDatasetImportJobRequest)
.datasetImportJob();
status = datasetImportJob.status();
System.out.println("Dataset import job status: " + status);
if (status.equals("ACTIVE") || status.equals("CREATE FAILED")) {
break;
}
try {
Thread.sleep(waitInMilliseconds);
} catch (InterruptedException e) {
System.out.println(e.getMessage());
}
}
return datasetImportJobArn;
} catch (PersonalizeException e) {
System.out.println(e.awsErrorDetails().errorMessage());
}
return "";
}
- SDK for JavaScript v3
// Get service clients and commands using ES6 syntax.
import { CreateDatasetImportJobCommand, PersonalizeClient } from
"@aws-sdk/client-personalize";
// create personalizeClient
const personalizeClient = new PersonalizeClient({
region: "REGION"
});
// Set the dataset import job parameters.
export const datasetImportJobParam = {
datasetArn: 'DATASET_ARN', /* required */
dataSource: {
dataLocation: 's3://<name of your S3 bucket>/<folderName>/<CSVfilename>.csv' /* required */
},
jobName: 'NAME', /* required */
roleArn: 'ROLE_ARN', /* required */
importMode: "FULL", /* optional, default is FULL */
publishAttributionMetricsToS3: true /* set to true to publish metrics to Amazon S3 bucket */
};
export const run = async () => {
try {
const response = await personalizeClient.send(new CreateDatasetImportJobCommand(datasetImportJobParam));
console.log("Success", response);
return response; // For unit tests.
} catch (err) {
console.log("Error", err);
}
};
run();