本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
叢集快取管理
快取記憶體是任何資料庫 (DB) 最重要的功能之一,因為它有助於減少磁碟 I/O。最常存取的資料會儲存在稱為緩衝區快取記憶體的記憶體區域中。當查詢頻繁執行時,它會直接從快取擷取而非磁碟擷取資料。這是更快,並提供更好的可擴展性和應用程序性能。您可以使用shared_buffers參數來設定 PostgreSQL 快取大小。如需詳細資訊,請參閱記憶體
容錯移轉之後,Amazon Aurora PostgreSQL 相容版本中的叢集快取管理 (CCM) 旨在改善應用程式和資料庫復原效能。在沒有 CCM 的典型容錯移轉情況中,您可能會發現效能暫時大幅降低。這樣的容錯移轉資料庫執行個體啟動、但緩衝快取處於空的狀態時。空的快取也稱作 冷快取。資料庫執行個體必須從磁碟讀取,這比從快取讀取慢。
當您實作 CCM 時,您可以選擇慣用的讀取器資料庫執行個體,CCM 會持續將其快取記憶體與主要或寫入器資料庫執行個體的快取記憶體同步。如果容錯移轉,喜好的讀取器資料庫執行個體會提升到新的寫入器資料庫執行個體。因為它已經有快取記憶體 (稱為暖快取),因此可將容錯移轉對應用程式效能的影響降到最低。
叢集快取管理如何運作?
容錯移轉資料庫執行個體與主要寫入器資料庫執行個體位於不同的可用區域。偏好的讀取器資料庫執行個體是優先順序容錯移轉目標,透過指派第 0 層優先順序層級來指定。
注意
提取層級優先順序的值,代表容錯移轉後 Aurora 讀取器提升為寫入器資料庫執行個體的特定順序。有效的值為 0–15,0 代表最高優先順序,15代表最低優先順序。如需提取層級的詳細資訊,請參閱 Aurora 資料庫叢集容。若要修改促銷層級不會造成停機
CCM 將快取從寫入器資料庫執行個體同步快取到偏好的讀取器資料庫執行個體。讀取器資料庫執行個體會將目前快取的一組緩衝區位址傳送至寫入器資料庫執行個體,做為布隆篩選器。布隆過濾器是一種概率的,具有內存效率的數據結構,用於測試元素是否為集合的成員。使用 bloom 篩選器可防止讀取器資料庫執行個體重複傳送相同的緩衝區位址到寫入器資料庫執行個體。當寫入器資料庫執行個體收到 bloom 篩選器時,會比較其緩衝區快取中的區塊,並將常用的緩衝區傳送至讀取器資料庫執行個體。默認情況下,如果緩衝區的使用計數大於三,則被認為是經常使用的緩衝區。
下圖顯示 CCM 如何將寫入器資料庫執行個體的緩衝區快取與偏好的讀取器資料庫執行個體同步化。
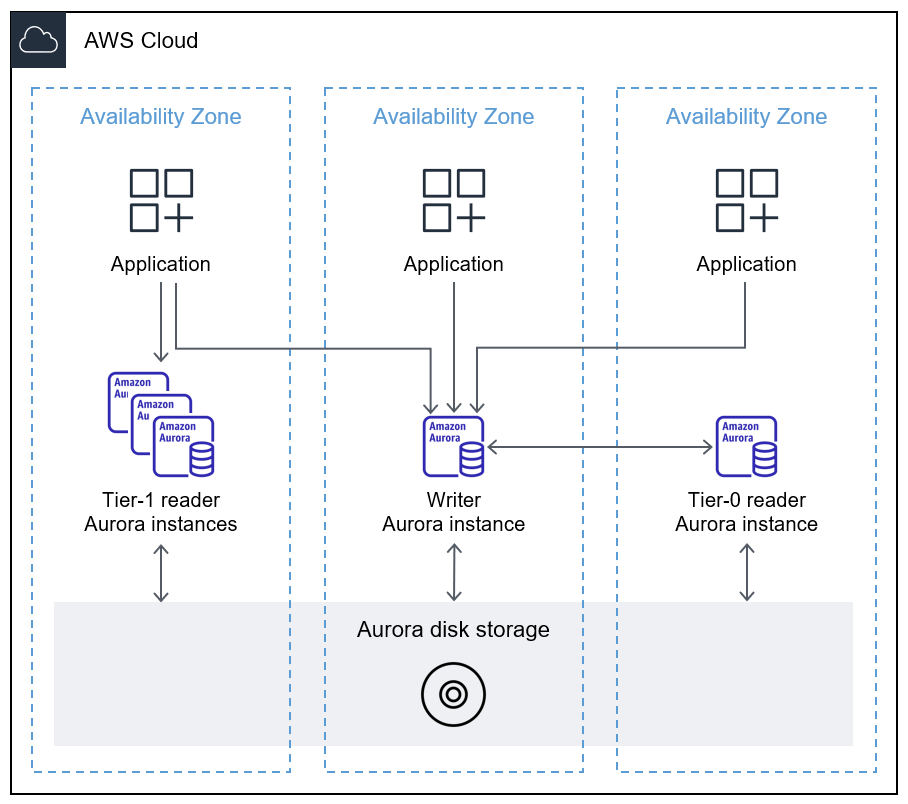
如需 CCM 的詳細資訊,請參閱使用適用於 Aurora PostgreSQL 的叢集快取管理進行容錯移轉後快速復原 (Aurora 文件) 和 Aurora PostgreSQL 叢集快取管理簡介
限制
CCM 功能具有下列限制:
-
讀取器資料庫執行個體必須具有與寫入器資料庫執行個體類別類型和大小
db.r5.xlarge。r5.2xlarge -
作為 Aurora 全域資料庫一部分的 Aurora PostgreSQL 資料庫叢集不支援 CCM。
叢集快取管理
對於某些產業 (例如零售業、銀行業和金融) 而言,只有幾毫秒的延遲可能會導致應用程式效能問題,並導致業務大幅損失。因為 CCM 會持續將主要資料庫執行處理的緩衝區快取與偏好的備份執行處理同步,協助復原應用程式和資料庫效能,因此可協助防止企業因容錯移轉造成的損失。
