本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
Database-per-service模式
鬆耦合是微服務架構的核心特性,因為每個微服務都可以獨立儲存並從自己的資料存放區擷取資訊。透過部署database-per-service模式,您可以為您的應用程式和業務需求選擇最適當的資料存放區 (例如關聯式或非關聯式資料庫)。這表示微服務不會共用資料層、微服務個別資料庫的變更不會影響其他微服務、其他微服務無法直接存取個別資料存放區,而且持久性資料只能由 APIs存取。解耦資料存放區也會改善整體應用程式的彈性,並確保單一資料庫無法成為單一故障點。
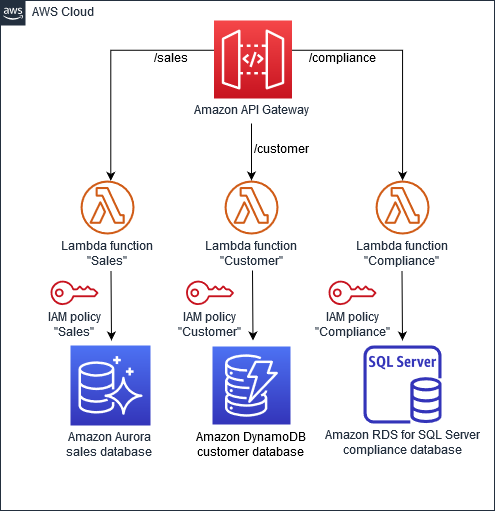
在下圖中,「銷售」、「客戶」和「合規」微服務會使用不同的 AWS 資料庫。這些微服務會部署為 AWS Lambda 函數,並透過 Amazon API Gateway API 存取。 AWS Identity and Access Management (IAM) 政策可確保資料保持私有,而不會在微服務之間共用。每個微服務都使用符合其個別需求的資料庫類型;例如,「銷售」使用 Amazon Aurora,「客戶」使用 Amazon DynamoDB,而「合規」使用 Amazon Relational Database Service (Amazon RDS) for SQL Server。
在以下情況下,您應該考慮使用此模式:
-
微服務之間需要鬆散耦合。
-
微服務對其資料庫有不同的合規或安全要求。
-
需要更精細地控制擴展。
使用database-per-service資料庫模式有以下缺點:
-
實作橫跨多個微服務或資料存放區的複雜交易和查詢可能具有挑戰性。
-
您必須管理多個關聯式和非關聯式資料庫。
-
您的資料存放區必須符合兩個 CAP 理論
要求:一致性、可用性或分割區公差。
注意
