本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
# Amazon Redshift 中的 SQL 查詢處理
Amazon Redshift 會透過剖析器和最佳化器遞送提交的 SQL 查詢,以開發查詢計畫。執行引擎接著會將查詢計畫轉譯為程式碼,並將該程式碼傳送至運算節點以供執行。在設計查詢計劃之前,了解查詢處理的運作方式至關重要。
## 查詢計劃和執行工作流程
下圖提供查詢規劃和執行工作流程的高階檢視。
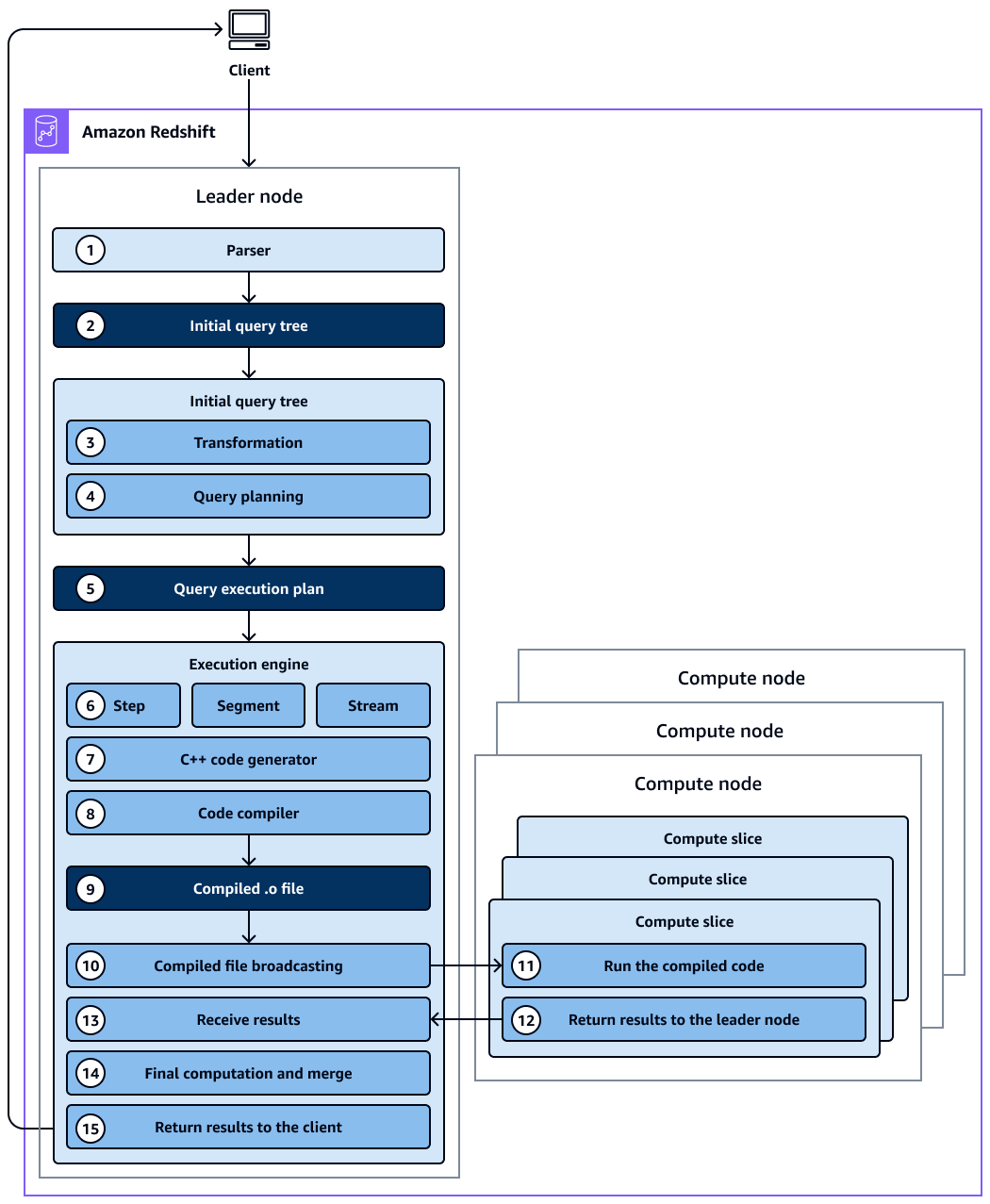
該圖顯示以下工作流程:
1. Amazon Redshift 叢集中的領導節點會收到查詢並剖析 SQL 陳述式。
1. 剖析器會產生初始查詢樹狀結構,這是原始查詢的邏輯表示法。
1. 查詢最佳化工具會取得初始查詢樹狀目錄並對其進行評估、分析資料表統計資料以判斷聯結順序和述詞選擇性,並視需要重寫查詢以最大化其效率。有時,單一查詢可以撰寫為背景中的數個相依陳述式。
1. 最佳化器會產生一個查詢計畫 (或數個,如果先前的步驟產生多個查詢) 以利用最佳效能執行。查詢計畫會指定執行選項,例如執行順序、網路操作、聯結類型、聯結順序、彙總選項和資料分佈。
1. 查詢計畫包含執行查詢所需的個別操作資訊。您可以使用 `EXPLAIN` 命令來檢視查詢計畫。查詢計畫為用於分析和調校複雜查詢的基礎工具。
1. 查詢最佳化工具會將查詢計畫傳送至執行引擎。執行引擎會檢查編譯的計劃快取是否有查詢計劃比對,並使用編譯的快取 (如果找到)。否則,執行引擎會將查詢計劃轉換為步驟、區段和串流:
+ *步驟*是在查詢執行期間發生的個別操作。步驟由標籤識別 (例如,、`hjoin`、 `scan` `dist`或 `merge`)。步驟是最小的單位。您可以結合步驟,讓運算節點可以執行查詢、聯結或其他資料庫操作。
+ *區段*是指查詢的區段,並結合可透過單一程序完成的數個步驟。區段是運算節點配量可執行的最小編譯單位。配量是 Amazon Redshift 中平行處理的單位。
+ *串流*是要封裝在可用運算節點配量上的區段集合。串流中的區段會跨節點配量平行執行。因此,相同區段的相同步驟也會在多個配量中平行執行。
1. 程式碼產生器會收到翻譯的計劃,並為每個區段產生 C\+\+ 函數。
1. 產生的 C\+\+ 函數由 GNU 編譯器集合編譯,並轉換為 O (`.o`) 檔案。
1. 編譯的程式碼 (O 檔案) 會執行。相較於轉譯的程式碼,編譯的程式碼執行得更快速,並且使用較少運算容量。
1. 然後,編譯的 O 檔案會廣播到運算節點。
1. 每個運算節點都包含數個運算配量。運算配量會平行執行查詢區段。Amazon Redshift 利用最佳化的網路通訊、記憶體和磁碟管理,將中繼結果從一個查詢計畫步驟傳遞到下一個步驟。這也有助於加速查詢執行。考慮下列各項:
+ 步驟 6、7、8、9、10 和 11 會針對每個串流進行一次。
+ 引擎會為一個串流建立可執行區段,並將這些區段傳送至運算節點。
+ 先前的串流區段完成後,引擎會為下一個串流產生區段。以此方式,引擎可以分析前一個串流中發生的動作 (例如,操作是否基於磁碟) 以影響下一個串流中區段的產生。
1. 運算節點完成後,它們會將查詢結果傳回領導節點以進行最終處理。領導節點會將資料合併為單一結果集,並處理任何必要的排序或彙總。
1. 領導節點會將結果傳回給用戶端。
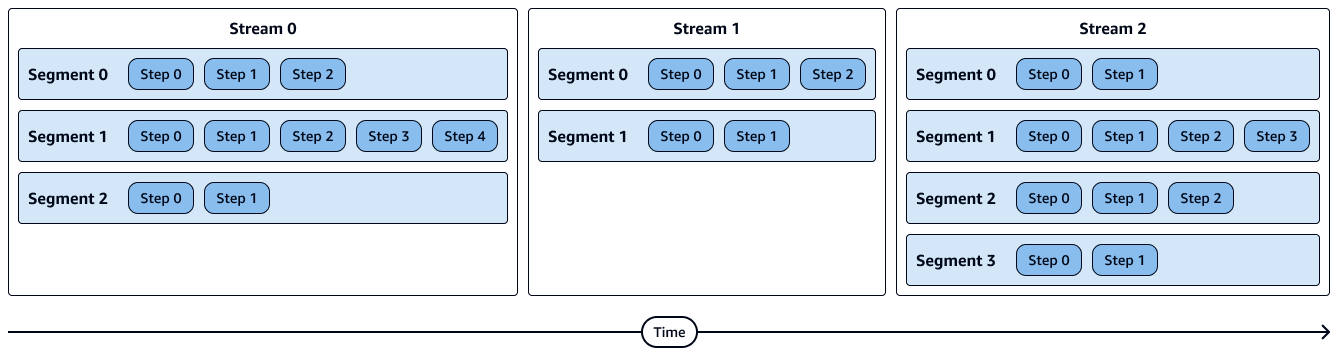
下圖顯示串流、區段、步驟和運算節點配量的執行工作流程。請謹記以下幾點:
+ 區段中的步驟會依序執行。
+ 串流中的區段會平行執行。
+ 串流會依序執行。
+ 運算節點配量會平行執行。
下圖顯示串流、區段和步驟的視覺化呈現。每個區段包含多個步驟,每個串流包含多個區段。
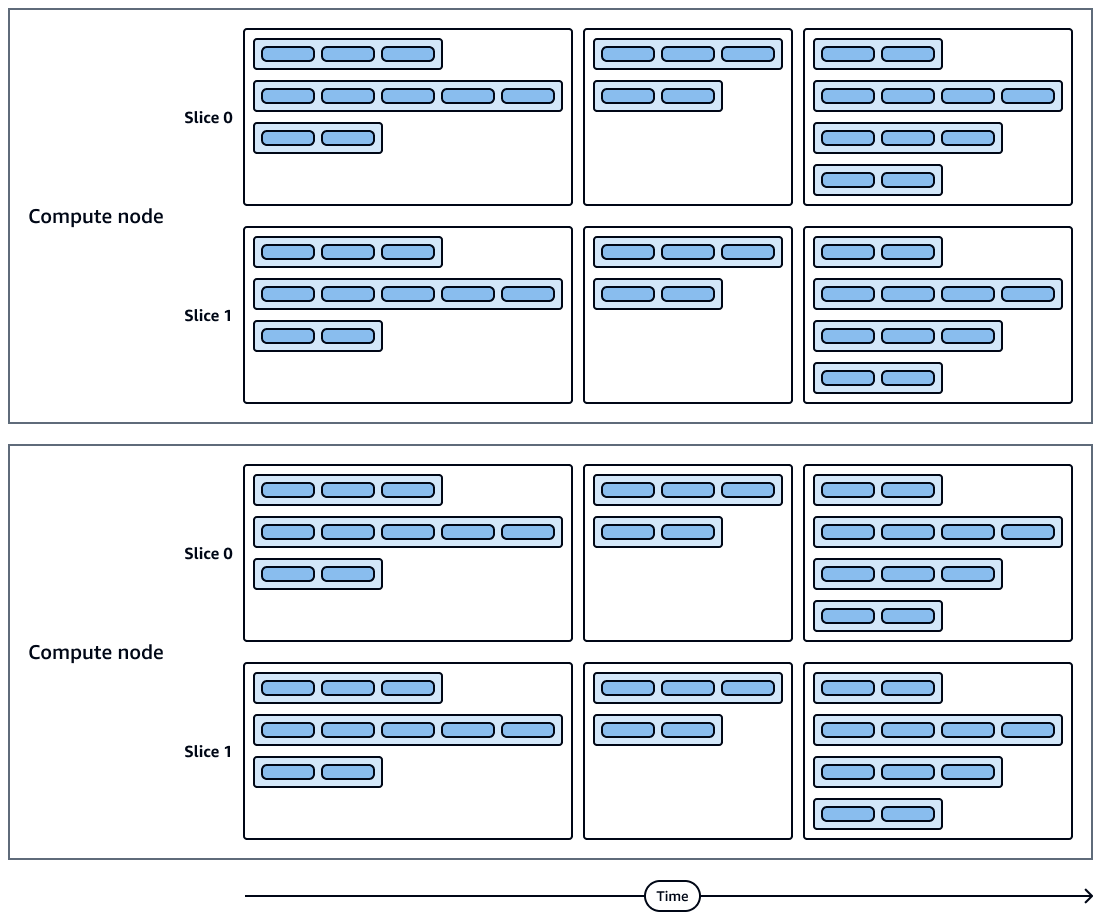
下圖顯示查詢執行和運算節點配量的視覺化呈現。每個運算節點包含多個配量、串流、區段和步驟。
## 其他考量
我們建議您在查詢處理方面考慮下列事項:
+ 快取的編譯程式碼會在相同叢集上的工作階段之間共用,因此即使使用不同的參數,相同查詢的後續執行也會更快。
+ 當您對查詢進行基準測試時,我們建議您一律比較查詢第二次執行的時間,因為第一次執行時間包含編譯程式碼的額外負荷。如需詳細資訊,請參閱 *Amazon Redshift *[的查詢最佳實務指南中的查詢效能因素](https://docs.aws.amazon.com/prescriptive-guidance/latest/query-best-practices-redshift/query-performance-factors.html)。
+ 如有必要,運算節點可以在查詢執行期間將一些資料傳回領導節點。例如,如果您有子查詢具有 `LIMIT`子句,則限制會套用至領導節點,然後再將資料重新分佈到叢集以進行進一步處理。