本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
優化用戶定義函
用戶定義的函數(UDFs)和 RDD.map in PySpark 經常會顯著降低性能。這是因為在 Spark 的底層 Scala 實現中準確表示您的 Python 代碼所需的開銷。
下圖顯示了 PySpark 作業的體系結構。當您使用時 PySpark,星火驅動程序使用 Py4j 的庫從 Python 調用 Java 方法。當調用 Spark SQL 或 DataFrame 內置函數時,Python 和 Scala 之間的性能差異很小,因為函數JVM使用優化的執行計劃在每個執行程序上運行。
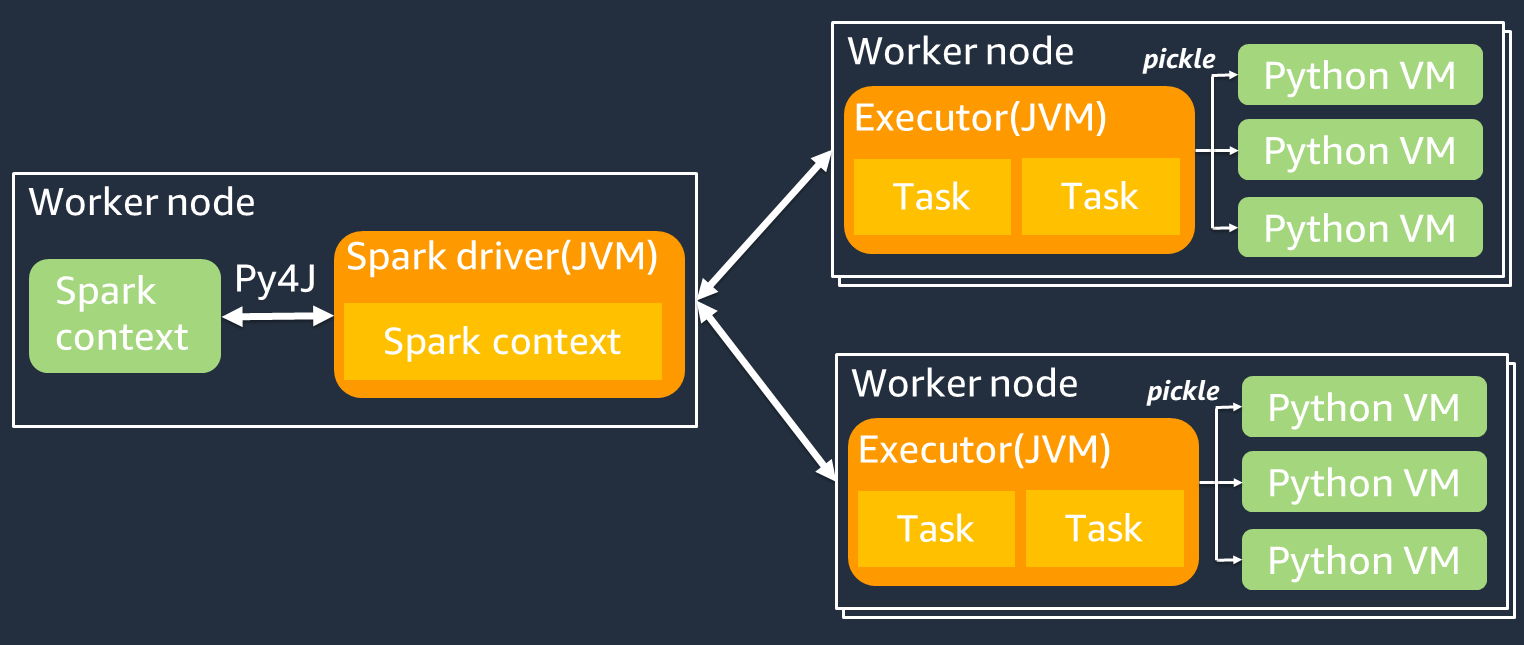
如果您使用自己的 Python 邏輯(例如使用)map/ mapPartitions/ udf,則該任務將在 Python 運行時環境中運行。管理兩個環境會產生額外負荷成本。此外,您必須轉換記憶體中的資料,以供JVM執行階段環境的內建函數使用。P@@ ickle 是默認情況下用於JVM和 Python 運行時之間交換的序列化格式。但是,這種序列化和反序列化的成本非常高,因此用 Java 或 Scala UDFs 編寫的成本比 Python 更快。UDFs
為了避免中的序列化和反序列化開銷 PySpark,請考慮以下幾點:
-
使用內置的 Spark SQL 函數-考慮用 Spark UDF 或 DataFrame內置函數替換您自己的SQL或地圖功能。運行 Spark SQL 或 DataFrame 內置函數時,Python 和 Scala 之間的性能差異很小,因為任務在每個執行程序上處理。JVM
-
UDFs在斯卡拉或 Java 中實現 — 考慮使用 Java 或斯卡拉編寫的,因為它們在JVM. UDF
-
UDFs針對向量化工作負載使用 Apache 箭頭 — 請考慮使用以箭頭為基礎。UDFs此功能也稱為矢量化UDF(熊貓UDF)。Apache 箭頭
是一種語言無關的內存中數據格式, AWS Glue 可以用來有效地在和 Python 進程之間傳輸數據。JVM對於使用熊貓或 NumPy數據的 Python 用戶來說,這是目前最有益的。 箭頭是柱狀(矢量化)格式。它的使用不是自動的,可能需要對配置或代碼進行一些小的更改,以充分利用並確保兼容性。如需詳細資訊和限制,請參閱中的 Apache 箭頭 PySpark
。 下面的例子比較標準 Python UDF 中的基本增量,作為矢量化UDF,並在星火。SQL
標準 Python UDF
示例時間為 3.20(秒)。
範例程式碼
# DataSet df = spark.range(10000000).selectExpr("id AS a","id AS b") # UDF Example def plus(a,b): return a+b spark.udf.register("plus",plus) df.selectExpr("count(plus(a,b))").collect()
執行計劃
== Physical Plan == AdaptiveSparkPlan isFinalPlan=false +- HashAggregate(keys=[], functions=[count(pythonUDF0#124)]) +- Exchange SinglePartition, ENSURE_REQUIREMENTS, [id=#580] +- HashAggregate(keys=[], functions=[partial_count(pythonUDF0#124)]) +- Project [pythonUDF0#124] +- BatchEvalPython [plus(a#116L, b#117L)], [pythonUDF0#124] +- Project [id#114L AS a#116L, id#114L AS b#117L] +- Range (0, 10000000, step=1, splits=16)
矢量化 UDF
示例時間為 0.59(秒)。
矢量化UDF的速度比前UDF面的示例快 5 倍。檢查Physical Plan,你可以看到ArrowEvalPython,這表明這個應用程序是由 Apache 箭矢量化。要啟用矢量化UDF,您必須在代碼spark.sql.execution.arrow.pyspark.enabled = true中指定。
範例程式碼
# Vectorized UDF from pyspark.sql.types import LongType from pyspark.sql.functions import count, pandas_udf # Enable Apache Arrow Support spark.conf.set("spark.sql.execution.arrow.pyspark.enabled", "true") # DataSet df = spark.range(10000000).selectExpr("id AS a","id AS b") # Annotate pandas_udf to use Vectorized UDF @pandas_udf(LongType()) def pandas_plus(a,b): return a+b spark.udf.register("pandas_plus",pandas_plus) df.selectExpr("count(pandas_plus(a,b))").collect()
執行計劃
== Physical Plan == AdaptiveSparkPlan isFinalPlan=false +- HashAggregate(keys=[], functions=[count(pythonUDF0#1082L)], output=[count(pandas_plus(a, b))#1080L]) +- Exchange SinglePartition, ENSURE_REQUIREMENTS, [id=#5985] +- HashAggregate(keys=[], functions=[partial_count(pythonUDF0#1082L)], output=[count#1084L]) +- Project [pythonUDF0#1082L] +- ArrowEvalPython [pandas_plus(a#1074L, b#1075L)], [pythonUDF0#1082L], 200 +- Project [id#1072L AS a#1074L, id#1072L AS b#1075L] +- Range (0, 10000000, step=1, splits=16)
火花 SQL
示例時間是 0.087(秒)。
Spark SQL 比矢量化快得多UDF,因為這些任務在沒有 Python 運行時的JVM情況下在每個執行程序上運行。如果您可以UDF用內置函數替換您的,我們建議您這樣做。
範例程式碼
df.createOrReplaceTempView("test") spark.sql("select count(a+b) from test").collect()
使用熊貓進行大數據
如果您已經熟悉熊貓
