本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
減少資料掃描量
首先,請考慮僅加載所需的數據。您只需減少每個資料來源載入 Spark 叢集的資料量,就可以改善效能。若要評估此方法是否適當,請使用下列量度。
您可以在 Spark UI 中檢查CloudWatch指標中讀取 Amazon S3 的位元組,以及如 Spark UI 一節中所述的更多詳細資訊。
CloudWatch 度量
您可以在ETL資料移動 (位元組) 中查看 Amazon S3 的近似讀取大小。此指標顯示自上一份報告以來,所有執行者從 Amazon S3 讀取的位元組數。您可以使用它來監控來自 Amazon S3 的ETL資料移動,也可以將讀取與外部資料來源的擷取速率進行比較。
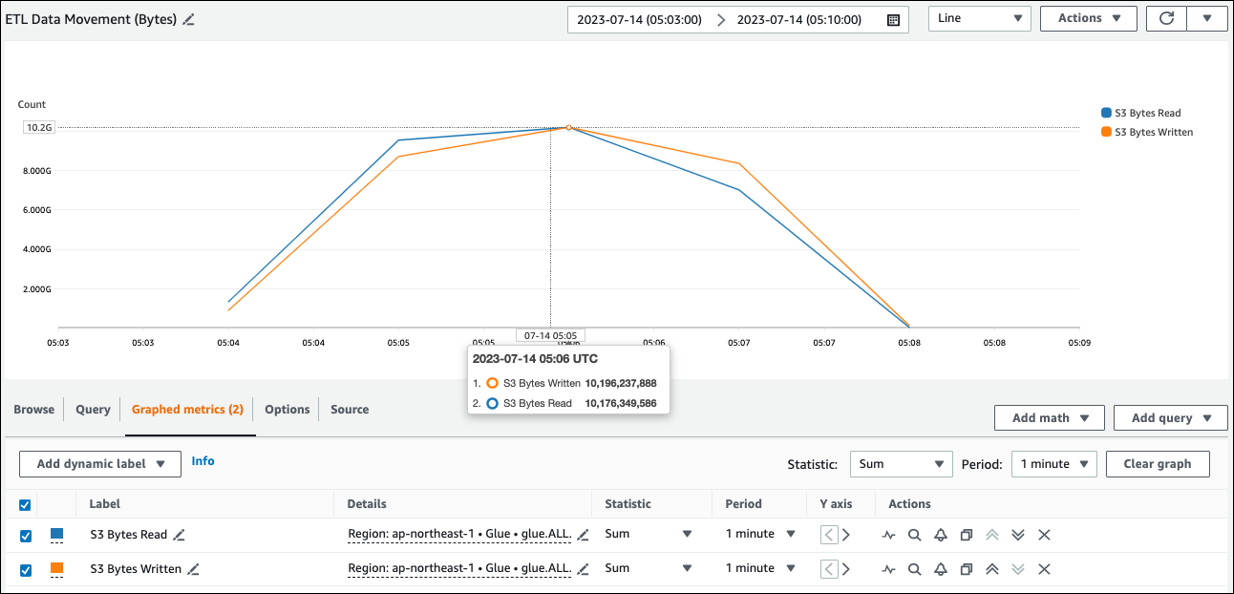
如果您發現的 S3 位元組讀取資料點超出預期,請考慮下列解決方案。
Spark UI
在 Spark UI 的「舞台」索引標籤上,您可以看到「輸入」和「輸出」大小。 AWS Glue 在下列範例中,階段 2 會讀取 47.4 GiB 輸入和 47.7 GiB 輸出,而階段 5 則讀取 61.2 MiB 輸入和 56.6 MiB 輸出。

當您在 AWS Glue 工作中使用 Spark SQL 或 DataFrame 方法時,SQL/D ataFrame 索引標籤會顯示有關這些階段的更多統計資料。在此情況下,階段 2 會顯示讀取的檔案數目:430、讀取的檔案大小:47.4 GiB,以及輸出列數目:160,796,570。
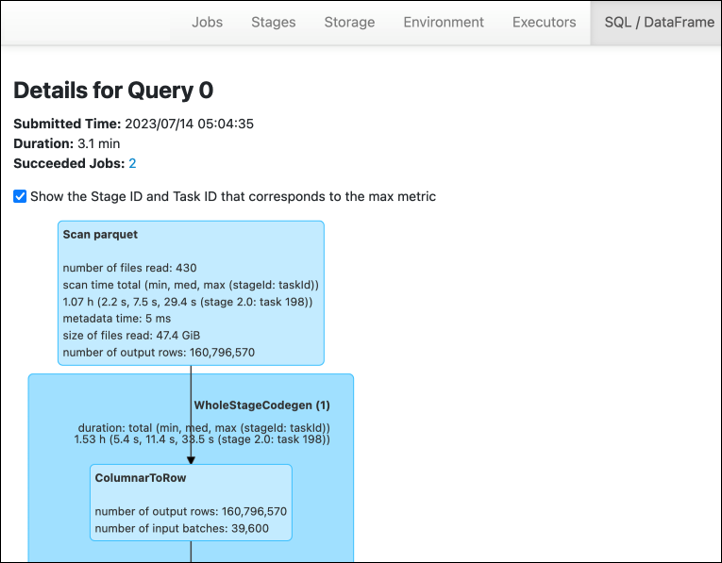
如果您發現正在讀取的資料與使用的資料之間存在大小差異,請嘗試下列解決方案。
Amazon S3
若要減少從 Amazon S3 讀取時載入任務的資料量,請考慮資料集的檔案大小、壓縮、檔案格式和檔案配置 (分割區)。 AWS Glue Spark 作業通常用於原始ETL資料,但為了有效率地分散式處理,您需要檢查資料來源格式的功能。
-
檔案大小 — 我們建議將輸入和輸出的檔案大小保持在中等範圍內 (例如 128 MB)。檔案太小和檔案太大可能會造成問題。
大量的小檔案會導致以下問題:
-
Amazon S3 上的網路 I/O 負載過重,因為對許多物件發出請求 (例如
ListGet、或Head) 所需的開銷 (與存放相同數量資料的一些物件相比)。 -
Spark 驅動程序上的 I/O 和處理負載繁重,這將生成許多分區和任務,並導致過多的並行性。
另一方面,如果您的文件類型不可分割(例如 gzip),並且文件太大,則 Spark 應用程序必須等到單個任務完成讀取整個文件。
若要減少為每個小型檔案建立 Apache Spark 工作時所產生的過多平行處理原則,請使用檔案群組。 DynamicFrames這種方法減少了 Spark 驅動程序OOM異常的可能性。若要規劃檔案群組,請設定
groupFiles和groupSize參數。下列程式碼範例會 AWS Glue DynamicFrame API在具有這些參數的ETL指令碼中使用。dyf = glueContext.create_dynamic_frame_from_options("s3", {'paths': ["s3://input-s3-path/"], 'recurse':True, 'groupFiles': 'inPartition', 'groupSize': '1048576'}, format="json") -
-
壓縮 — 如果您的 S3 物件大於數百 MB,請考慮壓縮它們。有多種壓縮格式,大致可分為兩種類型:
-
不可分割的壓縮格式 (例如 gzip) 需要由一個 Worker 解壓縮整個檔案。
-
可分割的壓縮格式,例如 bzip2 或 LZO (索引),允許對檔案進行部分解壓縮,這些格式可以平行化。
對於 Spark (以及其他常見的分散式處理引擎),您會將來源資料檔案分割成引擎可以 parallel 處理的區塊。這些單位通常被稱為拆分。資料採用可分割格式後,最佳化的 AWS Glue 讀取器可以透過提供僅擷取特定區塊的
Range選項,從 S3 物件擷GetObjectAPI取分割。請看下面的圖表,看看這將如何在實踐中工作。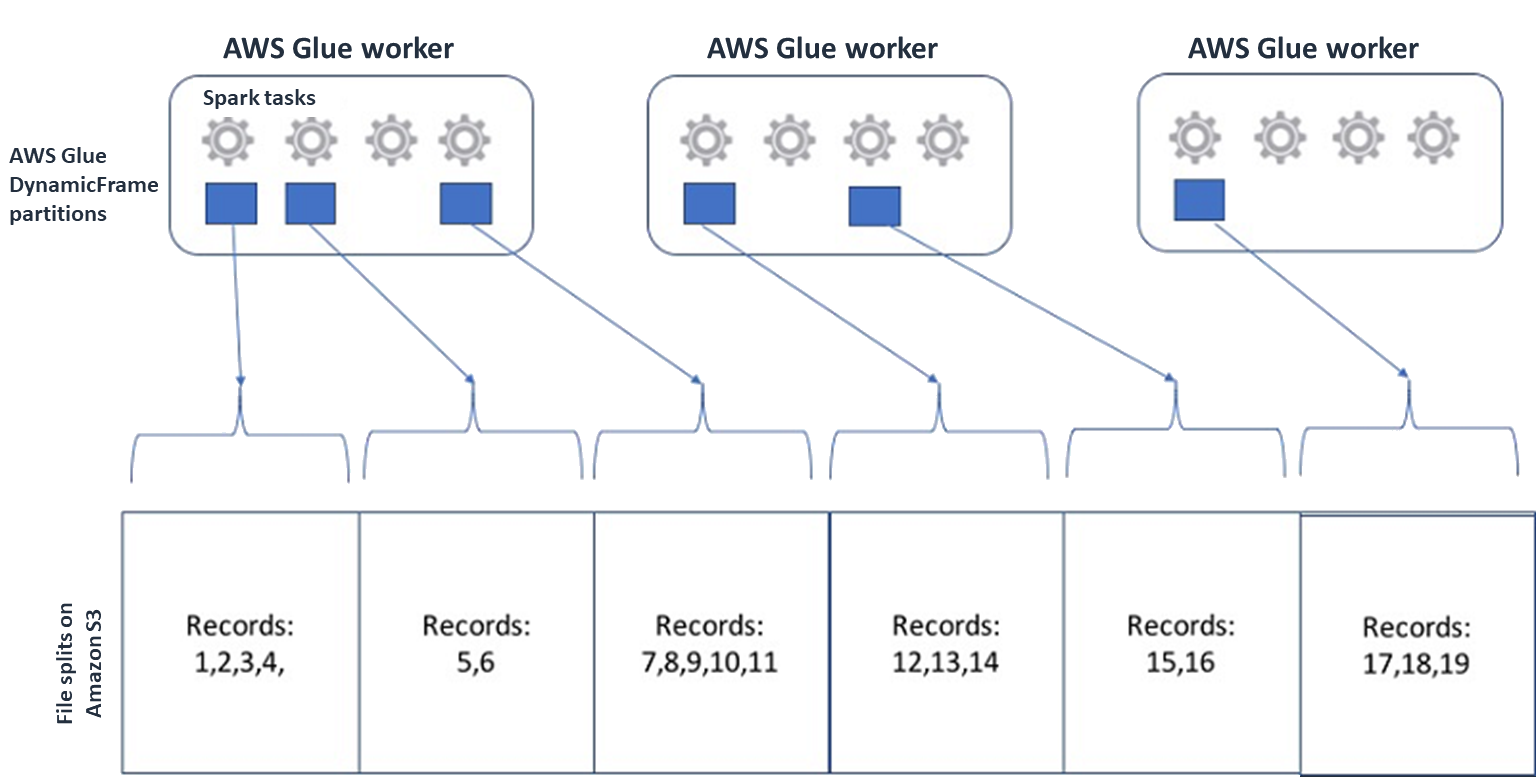
只要檔案具有最佳大小或檔案可分割,壓縮資料就可以大幅加快應用程式的速度。較小的資料大小可減少從 Amazon S3 掃描的資料,以及從 Amazon S3 傳送到 Spark 叢集的網路流量。另CPU一方面,壓縮和解壓縮數據需要更多。所需的計算量會根據壓縮演算法的壓縮率進行縮放。在選擇可拆分壓縮格式時,請考慮這種權衡。
注意
雖然 gzip 文件通常不是可分割的,但是您可以使用 gzip 壓縮單個實木複合地板塊,並且這些塊可以並行化。
-
-
檔案格式 — 使用欄格式。阿帕奇鑲木地板
和 Apache ORC 是流行的柱狀數據格式。實木複合地板,並通過採用基於列的壓縮,編碼和基於其數據類型壓縮每列有效地ORC存儲數據。有關鑲木地板編碼的更多信息,請參閱實木地板編碼定義 。實木複合地板文件也是可分割的。 柱格式按列對值進行分組,並將它們存儲在塊中。使用單欄格式時,您可以略過對應於您不打算使用的欄的資料區塊。Spark 應用程式只能擷取您需要的資料行。一般而言,較佳的壓縮比率或略過資料區塊表示從 Amazon S3 讀取較少的位元組,從而獲得更好的效能。這兩種格式也支援下列下推方法來減少 I/O:
-
投影下推 — 投影下推是一種僅擷取應用程式中指定的欄的技術。您可以在 Spark 應用程式中指定欄,如下列範例所示:
-
DataFrame 例如:
df.select("star_rating") -
火花的SQL例子:
spark.sql("select start_rating from <table>")
-
-
謂詞下推-謂詞下推是一種有效地處理和子句的技術。
WHEREGROUP BY這兩種格式都有代表欄值的資料區塊。每個區塊都會保留區塊的統計資料,例如最大值和最小值。Spark 可以使用這些統計資料來判斷是否應該讀取或略過區塊,具體取決於應用程式中使用的篩選器值。若要使用此功能,請在條件中新增更多篩選器,如下列範例所示:-
DataFrame 例如:
df.select("star_rating").filter("star_rating < 2") -
火花的SQL例子:
spark.sql("select * from <table> where star_rating < 2")
-
-
-
檔案配置 — 透過根據資料的使用方式將 S3 資料存放到不同路徑中的物件,您可以有效率地擷取相關資料。如需詳細資訊,請參閱 Amazon S3 文件中的使用前置詞組織物件。 AWS Glue 支援以格式將金鑰和值存放到 Amazon S3 前置詞
key=value,並依 Amazon S3 路徑對資料進行分區。透過分割資料,您可以限制每個下游分析應用程式掃描的資料量,從而改善效能並降低成本。如需詳細資訊,請參閱管理中的ETL輸出分割區 AWS Glue。分區將您的表格分成不同的部分,並根據列值(例如年,月和日)將相關數據保存在分組文件中,如以下示例所示。
# Partitioning by /YYYY/MM/DD s3://<YourBucket>/year=2023/month=03/day=31/0000.gz s3://<YourBucket>/year=2023/month=03/day=01/0000.gz s3://<YourBucket>/year=2023/month=03/day=02/0000.gz s3://<YourBucket>/year=2023/month=03/day=03/0000.gz ...您可以使用中的資料表建立模型,以定義資料集的分區 AWS Glue Data Catalog。然後,您可以使用分割區修剪來限制資料掃描量,如下所示:
-
對於 AWS Glue DynamicFrame,設定
push_down_predicate(或catalogPartitionPredicate)。dyf = Glue_context.create_dynamic_frame.from_catalog( database=src_database_name, table_name=src_table_name, push_down_predicate = "year='2023' and month ='03'", ) -
對於 Spark DataFrame,請設定修剪分割區的固定路徑。
df = spark.read.format("json").load("s3://<YourBucket>/year=2023/month=03/*/*.gz") -
對於 SparkSQL,您可以將 where 子句設定為從資料目錄中修剪資料分割。
df = spark.sql("SELECT * FROM <Table> WHERE year= '2023' and month = '03'") -
要在使用寫入數據時按日期劃分 AWS Glue,請partitionKeys在 DynamicFrame 或 partitionBy()
in 中設置,並在列中 DataFrame 使用日期信息,如下所示。 -
DynamicFrame
glue_context.write_dynamic_frame_from_options( frame= dyf, connection_type='s3',format='parquet' connection_options= { 'partitionKeys': ["year", "month", "day"], 'path': 's3://<YourBucket>/<Prefix>/' } ) -
DataFrame
df.write.mode('append')\ .partitionBy('year','month','day')\ .parquet('s3://<YourBucket>/<Prefix>/')
這可以提高輸出數據的消費者的性能。
如果您無權更改建立輸入資料集的管道,則無法進行磁碟分割。相反,您可以使用 glob 模式排除不需要的 S3 路徑。在閱讀時設定排除項目 DynamicFrame。例如,下列程式碼會排除 2023 年 01 到 09 個月的天數。
dyf = glueContext.create_dynamic_frame.from_catalog( database=db, table_name=table, additional_options = { "exclusions":"[\"**year=2023/month=0[1-9]/**\"]" }, transformation_ctx='dyf' )您也可以在「資料目錄」中的表格屬性中設定排除項:
-
索引鍵:
exclusions -
值:
["**year=2023/month=0[1-9]/**"]
-
-
-
Amazon S3 分割區太多 — 避免在包含多種值的資料行 (例如具有數千個值的 ID 資料行) 上分割 Amazon S3 資料。這可能會大幅增加儲存貯體中的分割區數量,因為可能的分割區數量是您所分割之所有欄位的產品。分割區過多可能會導致以下情況:
-
增加從資料目錄擷取分割區中繼資料的延遲
-
小檔案數量增加,需要更多 Amazon S3 API 請求 (
ListGet、和Head)
例如,當您在
partitionBy或中設置日期類型時partitionKeys,日期級分區(例如)對許多用例都yyyy/mm/dd很有用。但是,yyyy/mm/dd/<ID>可能會產生如此多的分割區,以至於整體效能會產生負面影響。另一方面,某些用例(例如實時處理應用程序)需要許多分區,例如
yyyy/mm/dd/hh。如果您的使用案例需要大量的分割區,請考慮使用資料AWS Glue 分割索引來減少從資料目錄擷取分割區中繼資料的延遲。 -
資料庫和 JDBC
若要在從資料庫擷取資訊時減少資料掃描,您可以在SQL查詢中指定where述詞 (或子句)。不提供SQL介面的資料庫將會提供自己的查詢或篩選機制。
使用 Java 資料庫連線 (JDBC) 連線時,請提供具有下列參數where子句的選取查詢:
-
對於 DynamicFrame,請使用sampleQuery選項。使用時
create_dynamic_frame.from_catalog,請按如下方式配置additional_options引數。query = "SELECT * FROM <TableName> where id = 'XX' AND" datasource0 = glueContext.create_dynamic_frame.from_catalog( database = db, table_name = table, additional_options={ "sampleQuery": query, "hashexpression": key, "hashpartitions": 10, "enablePartitioningForSampleQuery": True }, transformation_ctx = "datasource0" )何時
using create_dynamic_frame.from_options,如下配置connection_options引數。query = "SELECT * FROM <TableName> where id = 'XX' AND" datasource0 = glueContext.create_dynamic_frame.from_options( connection_type = connection, connection_options={ "url": url, "user": user, "password": password, "dbtable": table, "sampleQuery": query, "hashexpression": key, "hashpartitions": 10, "enablePartitioningForSampleQuery": True } ) -
對於 DataFrame,請使用查詢
選項。 query = "SELECT * FROM <TableName> where id = 'XX'" jdbcDF = spark.read \ .format('jdbc') \ .option('url', url) \ .option('user', user) \ .option('password', pwd) \ .option('query', query) \ .load() -
對於 Amazon Redshift,請使用 AWS Glue 4.0 或更新版本來利用 Amazon Redshift 星火連接器中的下推支援。
dyf = glueContext.create_dynamic_frame.from_catalog( database = "redshift-dc-database-name", table_name = "redshift-table-name", redshift_tmp_dir = args["temp-s3-dir"], additional_options = {"aws_iam_role": "arn:aws:iam::role-account-id:role/rs-role-name"} ) -
對於其他資料庫,請參閱該資料庫的文件。
AWS Glue 選項
