本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
了解可用性
可用性是我們可以量化測量恢復能力的主要方法之一。我們將可用性 A 定義為工作負載可供使用的時間百分比。這是其預期的「正常運行時間」(可用)與測量總時間(預期的「正常運行時間」加上預期的「停機時間」)的比率。
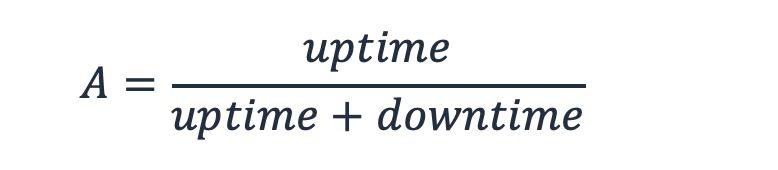
公式 1-可用性
為了更好地理解此公式,我們將研究如何衡量正常運行時間和停機時間。首先,我們想知道工作負載將不會失敗多長時間。我們稱之為平均故障間隔時間 (MTBF),即工作負載開始正常運作到下一次失敗之間的平均時間。然後,我們想知道失敗後恢復需要多長時間。
我們稱此為修復 (或復原) 的平均時間 (MTTR),這是在修復失敗的子系統或返回服務時,工作負載無法使用的一段時間。MTTR 中的一個重要時間段是平均偵測時間 (MTTD)、發生故障與修復作業開始之間的時間長度。下圖說明所有這些度量如何相關。
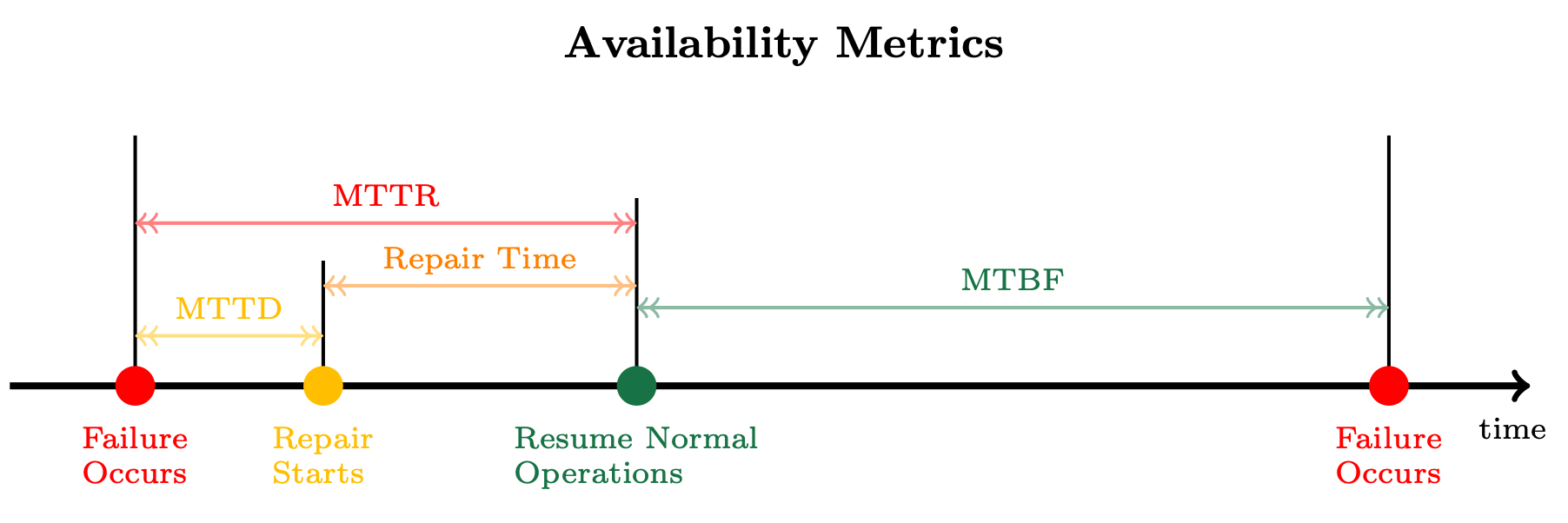
MTTD、MTTR 與 MTBF 之間的關係
因此,我們可以表示可用性,A,使用 MTBF,工作負載啟動的時間和 MTTR,工作負載關閉的時間。
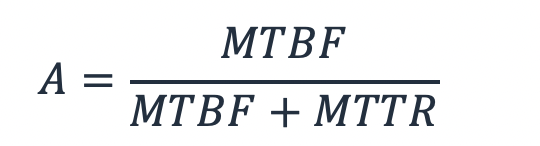
方程式 2-MTBF 和 MTTR 之間的關係
而工作負載「下降」的概率(也就是說,不可用)是失敗的概率,F。
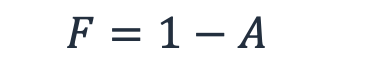
公式 3-失敗的概率
可靠性是指工作負載能夠在要求時在指定的回應時間內完成正確事情的能力。這是什麼可用性措施。工作負載失敗的頻率較低 (MTBF 較長) 或修復時間較短 (縮短 MTTR),可改善其可用性。
規則 1
較少的故障頻率 (較長的 MTBF)、更短的故障偵測時間 (縮短 MTTD),以及更短的修復時間 (縮短 MTTR) 是用來改善分散式系統可用性的三個因素。
